
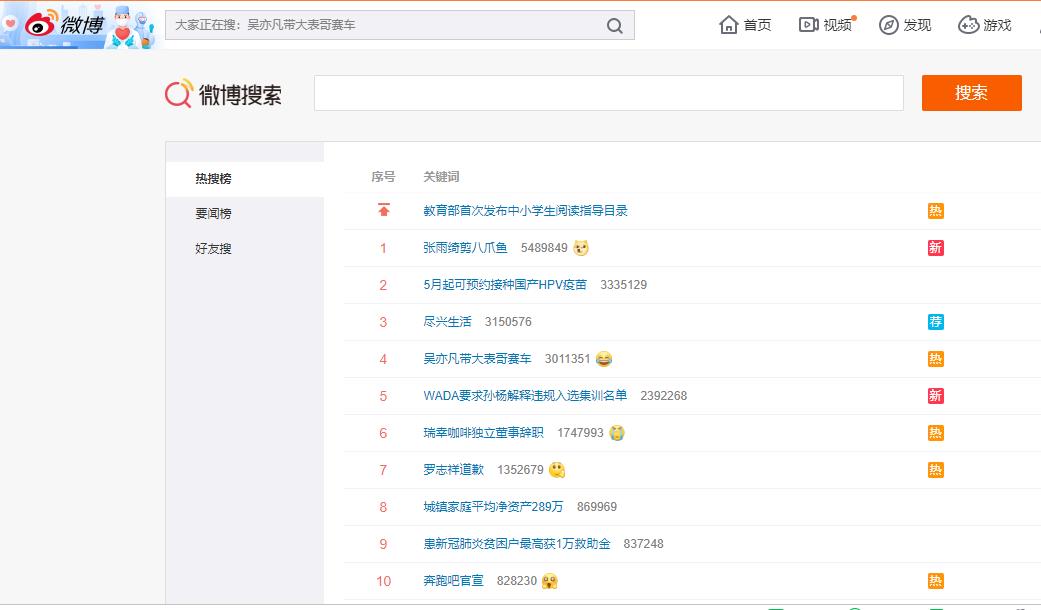
爬取微博热搜
import requests
from bs4 import BeautifulSoup
r = requests.get("https://s.weibo.com/top/summary")#微博热搜排行榜
soup = BeautifulSoup(r.text, 'lxml')
items = soup.find(class_="data").find_all(name="tr")
print('置顶'.ljust(2,' '),items[1].find(class_="td-02").a.string)
for item in items[2:]:
print(item.find(class_="td-01 ranktop").string.ljust(4,' '),item.find(class_="td-02").a.string)
import pandas as pd
#读取文件
df=pd.DataFrame(pd.read_csv("D:\weibo csv."))
print(df)
#删除无效列与行
df.drop('标题', axis=1, inplace = True)
df.head()
#绘制垂直柱状图
plt.bar(['第1名','第2名','第3名','第4名','第5名'],[5489849,335129,3150576,3011351,2392268],label="微博热搜前五名")
#绘制水平柱状图
plt.barh(['第1名','第2名','第3名','第4名','第5名'],[5489849,335129,3150576,3011351,2392268],label="微博热搜前五名")
#绘制折线图
def two():
x = df['排名']
y = df['标题']
plt.xlabel('排名')
plt.ylabel('标题')
plt.plot(x,y)
plt.scatter(x,y)
plt.title("绘制折线图")
plt.show()
two()
#绘制散点图
def sandian():
x = df['排名']
y = df['标题']
plt.xlabel('排名')
plt.ylabel('标题')
plt.scatter(x,y,color="red",label=u"热度分布数据",linewidth=2)
plt.title("排名与标题散点图")
plt.legend()
plt.show()
sandian()

以上是我的代码,远远达不到400行代码,只能说尽量,个人能力不足,在完成这次作业时深有体会

 浙公网安备 33010602011771号
浙公网安备 33010602011771号