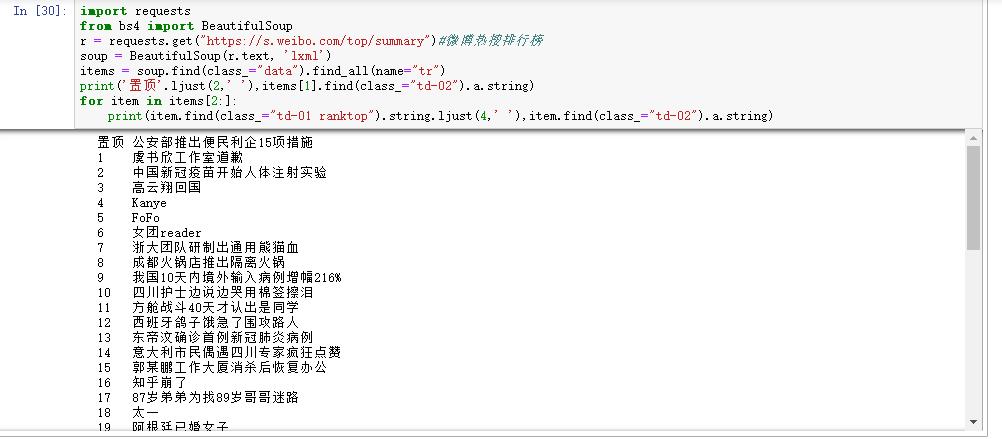
微博热搜
import requests from bs4 import BeautifulSoup r = requests.get("https://s.weibo.com/top/summary")#微博热搜排行榜 soup = BeautifulSoup(r.text, 'lxml') items = soup.find(class_="data").find_all(name="tr") print('置顶'.ljust(2,' '),items[1].find(class_="td-02").a.string) for item in items[2:]: print(item.find(class_="td-01 ranktop").string.ljust(4,' '),item.find(class_="td-02").a.string)