
Nginx中的502和504
nginx作为一个流行、轻量、高性能、稳定的web服务器,是应用运维日常最常接触的web服务器,更多的时候它是用于web代理服务,今天要说的是日常维护Nginx中最常遇到的两个HTTP状态码502和504
502 - Bad Gateway(坏的网关),一般是网关服务器请求后端服务时,后端服务没有按照http协议正确返回结果。
- the server returned an invalid or incomplete response => HTTP 502
- The server was acting as a gateway or proxy and received an invalid response from the upstream server
504 - Gateway Timeout(网关超时),一般是网关服务器请求后端服务时,后端服务没有在特定的时间内完成服务。
- the server failed to reply in time => HTTP 504
- The server was acting as a gateway or proxy and did not receive a timely response from the upstream server
上面是对两个状态码的解释,可以看到,两个状态码相同的地方就在于,都是后端服务有问题,所以具体看下哪些情况会是上面这两种状态码
上游服务主动reset
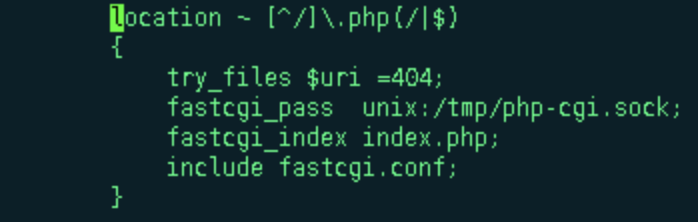
上游服务主动reset的情况呢,就是Nginx与后端建立的连接,被后端主动reset掉了,比如我们以php-fpm的代理为例,做个演示
nginx代理到php-fpm,用的是fast-cgi进行代理
我们配置好fastcgi_pass到php,我们需要后端主动down掉,php有两个配置可以帮我们实现这个,一个是php.ini中的max_execution_time这个值是php脚本的最长执行时间,还有一个配置是在php-fpm.conf中的配置request_terminate_timeout,当使用php-fpm的时候,这个值会覆盖max_execution_time
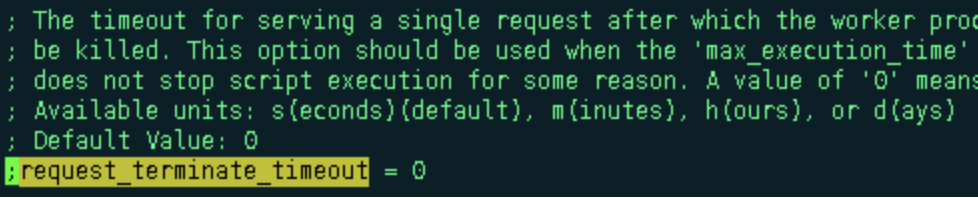

写个php脚本,用sleep()函数写一个时长超过request_terminate_timeout的,我这里sleep(70),然后request_terminate_timeout设置到50,这里不设置60,是为了避开Nginx的一些默认超时参数的时间配置,后面会给大家整理个所有涉及超时时间的参数的列表,为了方便查看,我在logformat中添加了$request_time和$upstream_response_time,然后我们看下效果
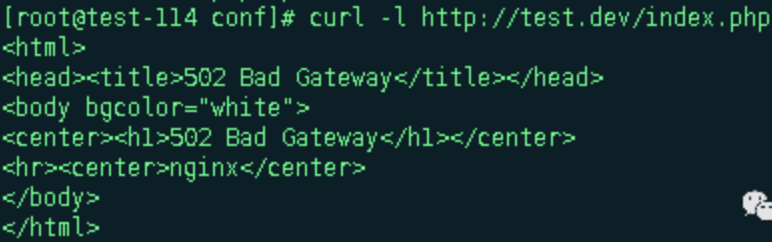
请求报错502,接着看下nginx的日志和php-fpm的日志
最后两个分别是$request_time和$upstream_response_time
错误日志报错104: Connection reset by peer
php-fpm日志报脚本执行超时,进程被kill掉,这种情况nginx返回502错误状态码
我们上面是让php在执行过程php进程被kill掉,还有一种比较常见的情况就是php-fpm没启动,或者php-fpm的sock或端口没被监听,这个时候nginx将php请求转发到php-fpm,由于后端没有这个监听,nginx返回502,在nginx错误日志中报如下错误
111: Connection refused
说到php-fpm进程,在nginx代理php-fpm的配置中,还有一种情况后端会主动reset,就是在高并发的情况下php-fpm最大进程数不够用,这里有两种情况
一种情况是当并发上来后,后面的请求nginx都返回502,这种情况通常是php-fpm的最大进程数设置太小引起的,当然这个配置要根据内存来计算的,太大也不行,通常单个php进程占用内存在20~30M左右,太大的可能存在内存泄漏,这个时候其实在php-fpm的日志中就会有告警了
另外一种情况就是当并发上来后,502间歇性出现,这种情况一般是php-fpm的max_requests配置造成的,这个配置主要是为了解决内存泄漏的问题的,它是指php进程最多处理多少个请求之后就销毁,重新创建新的进程。那么在高并发的情况下,max_requests设置的太小,php-fpm进程就会频繁的销毁重建,销毁重建的过程中,没有php-fpm进程可以处理nginx发过来的请求,nginx就会不断出现502;而max_requests设置太大又达不到解决内存泄漏的问题,而且进程处理、销毁、重建可能会在相同的时间断,这个时候就会造成短暂的502无法响应,最好的办法是在代码层面控制内存泄漏
Nginx超时配置
Nginx中涉及到的超时配置的参数总结如下:
ngx_http_core_module
client_body_timeout 默认60s
client_header_timeout 默认60s
keepalive_timeout 默认75s
lingering_time 默认30s
lingering_timeout 默认5s
resolver_timeout 默认30s
send_timeout 默认60s
ngx_http_proxy_module
proxy_cache_lock_timeout 默认5s
proxy_connect_timeout 默认60s
proxy_read_timeout 默认60s
proxy_send_timeout 默认60s
ngx_http_fastcgi_module
fastcgi_cache_lock_timeout 默认5s
fastcgi_connect_timeout 默认60s
fastcgi_read_timeout 默认60s
fastcgi_send_timeout 默认60s
ngx_http_ssl_module
ssl_session_timeout 默认5m
上面总共是4个模块,分别是核心模块、反向代理模块、fastcgi模块和ssl模块,每个指令的详细信息我就不一一介绍了,官网文档有详细介绍
其中ssl模块中的超时主要是建立ssl连接之后session的超时时间,该参数能够优化ssl连接,减少握手次数,但是并不涉及502及504状态码
通常我们配置nginx处理php请求都是通过fastcgi的,所以我们先看下fastcgi的几个超时参数
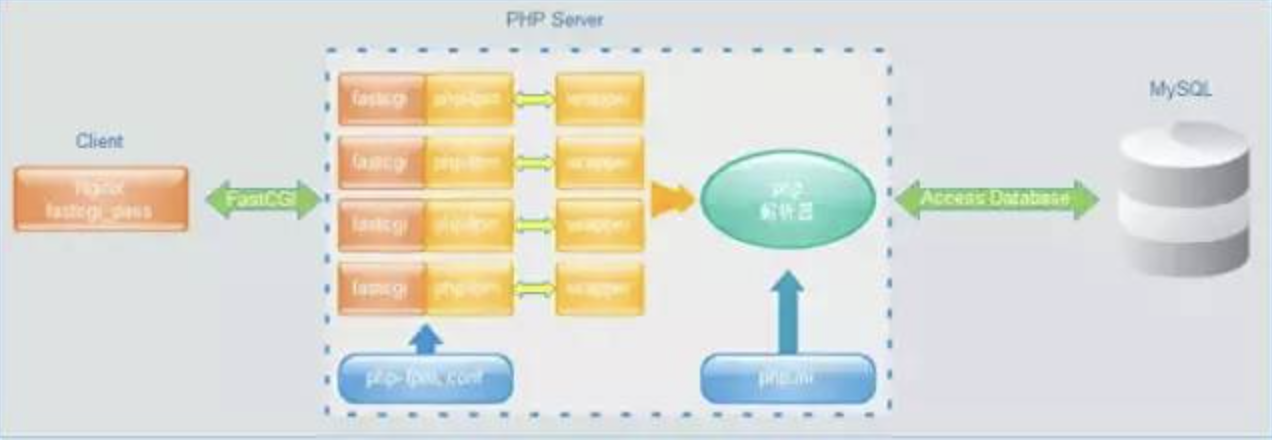
首先是fastcgi_cache_lock_timeout,这个参数是用来设置fastcgi_cache_lock的超时时间,fastcgi_cache_lock主要是用来锁定cache key的,当一次请求过来需要写一个cache key的时候,fastcgi_cache_lock会把这个cache key锁住,目的是当多个请求同时请求写同一个key的时候,只有一个可以去写,其他的请求等该key写成功后直接从cache中返回,防止大量请求下穿透cache,给后端的fastcgi服务器造成压力
剩余的三个参数fastcgi_connect_timeout、fastcgi_read_timeout、fastcgi_send_timeout,分别是nginx与fastcgi服务器建立连接的超时时间、从fastcgi服务器读取响应的超时时间、向fastcgi服务器传输请求的超时时间,这三个参数超时均会引起504错误
先来看下面这个场景
fastcgi_connect_timeout为20s
fastcgi_read_timeout为40s
fastcgi_send_timeout为30s
request_terminate_timeout为50s
php script sleep(70),发送第一个请求
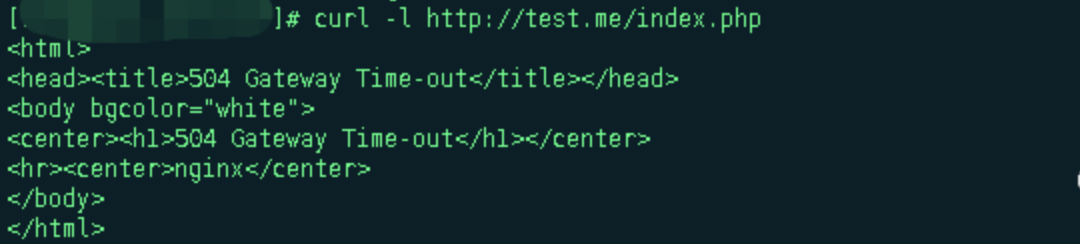
查看nginx日志,40s返回504错误,明显是触发了fastcgi_read_timeout,查看错误日志

110: Connection timed out
另外两个参数超时情况一样,都是超时后nginx主动断开返回504
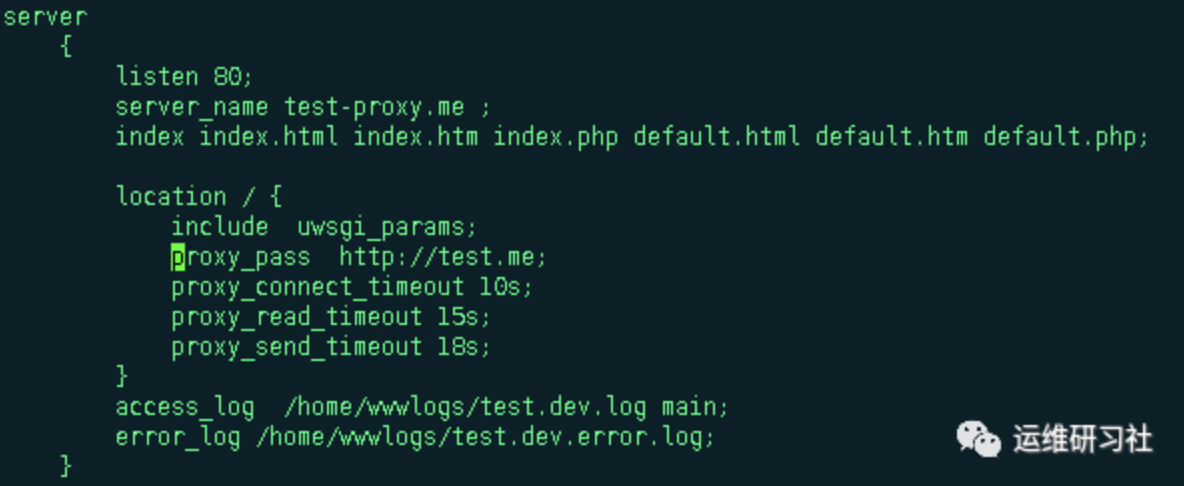
和fastcgi的4个超时参数类似的就是proxy的4个超时参数,原理上面一模一样,不同的在于fastcgi是处理fastcgi网关请求的,多用于处理php脚本,而proxy是用于反向代理的,也是和后端服务之间进行连接,在上面的基础上再加个server,通过proxy_pass反向代理到上面的server上,设置proxy超时时间如下

发起请求查看结果,返回504,查看nginx日志

触发了proxy_read_timeout的超时时间,接着看nginx错误日志

110: Connection timed out
这个结果和fastcgi一样,所以在客户端请求服务端,这个时候nginx是作为客户端的,当nginx请求后端,触发在nginx中配置的超时时间后,都是返回504状态码
在核心模块的超时配置中,基本都是nginx对于请求客户端的超时配置,这个时候,nginx是作为服务端的,这个时候基本返回的错误状态码都是40x,比如client_body_timeout、client_header_timeout超时都是返回408:Request Time-out
总结
504 的原因比较简单,一般都是上游服务的执行时间超过了 nginx 的等待时间,这种情况是由于上游服务的业务太过耗时导致的,或者连接到上游服务器超时。从上面的实验来看,后者的原因比较难以追踪,因为这种情况下连接是存在的,但是却连不上,好在这种 504 一般都会在一段时间后转为 502。
502 的原因是由于上游服务器的故障,比如停机,进程被杀死,上游服务 reset 了连接,进程僵死等各种原因。在 nginx 的日志中我们能够发现 502 错误的具体原因,分别为:104: Connection reset by peer,113: Host is unreachable,111: Connection refused。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!