

6.6哈夫曼算法能够大幅提升压缩比率
使用哈夫曼树后,出现频率越高的数据所占用的数据位数就越少,而且数据的区分也可以很清晰地实现。但哈夫曼算法为什么达到这么好的效果呢,大家都了解吗?
通过图6-5的步骤2可以发现,在用枝条连接数据时,我们是从出现频率较低的数据开始的,这就意味着出现频率越低的数据到达根部的枝条数就越多。而枝条数越多,编码的位数也就随之增多了。

而从用哈夫曼算法压缩过的文件中读取数据后,就会以位为单位对该数据进行排查,并与哈夫曼树进行比较看是否到达了目标编码,这就是为什么哈夫曼算法可以对数据进行区分的原因。例如,10001这个使用图6-5所示的哈夫曼编码作成的5位数据,到达100时,对照哈夫曼树的数据,该数据表示的是B这个字符。至此就找到了1个字符。然后再顺着哈夫曼树寻找剩下的01,会发现它表示的是E这个字符。
接下来,让我们来看一下哈夫曼算法的压缩比率。如下图:
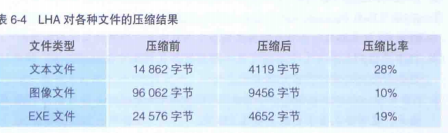
得到的哈夫曼编码表示AAAAAABBCDDEEEEEF,结果为0000000000001001001101011010101010101111,40位=5字节(这里为不包含哈夫曼编码信息的情况)。压缩前的数据是17字符=17字节,也就是说,我们惊奇地得到了5字节÷17字节=29%这样高的压缩率。表6-4是将表6-1中的文件应用哈夫曼算法的LHA进行压缩后的结果,大家可以参考一下。可以看出,不管是哪种类型的文件,都得到了很高的压缩比率。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· AI Agent开发,如何调用三方的API Function,是通过提示词来发起调用的吗