关于使用python运行爬虫的一些事儿
说在前面
首先,使用python坑定绕不开编译器, 对于爬虫这种东西,编译器似乎不是那么重要,因此,我们可以使用python自带的IDLE编译器,或者你希望写代码的时候可以看一些好看的小妹妹赏心悦目也可以自己下载vscode和paychorm,当然编译环境的调试也是一些烦人的事情
系统介绍
python爬虫其实是一个类似百度等一系列搜索引擎之类的工作原理,通过python的一些外置资源库来访问网站,并在得到网站的响应之后对于这些响应进行分析,最终存入Excel等工具中的过程。
在爬虫之中,除了python的基础语法之外,还会使用到一系列的外置库,其中包括bs4,re,urllib,这些资源库需要额外从cmd命令框中手动下
爬虫的一般流程
爬虫主要分为三大步,分别为爬取网站,解析数据,保存数据,而爬取网站中又包括访问网站和接受网站所返回的信息
爬取网站的一些基本东东1
这一步分为两大块,接受网站所返回的信息较为简单,由于一个网站可能会分页,只需要得到网站网址的变化规律就可以使用for循环和字符串可以在后面拼接的方法来组合出所分的各个网页。而重点是访问网站,这里需要用到自己额外安装的urllib数据库,和乌龟一样,使用之前需定义声明


1 import urllib.request 2 import urllib.error
而一般的网页请求为get 类型或者post类型,两者有相似处,get类型可以直接利用request库中的URLopen函数进行打开,不需要向网页传参数就直接可以返回,而post类型较为复杂,需要写代码的人向网页传输一些数据(不固定,甚至连传一句Hellow World都可以,只要有就行),具体代码如下
1 import urllib.request 2 # get请求 3 respound=urllib.request.urlopen("http://www.baidu.com") 4 print(respound.read().decode('utf-8')) 5 # post请求 6 import urllib.parse 7 data=bytes(urllib.parse.urlencode({"hellow":"world"}),encoding='utf-8') 8 respound=urllib.request.urlopen("http://httpbin.org/post",data=data) 9 print(respound.read().decode('utf-8'))
需要介绍一点,网站一般都是经过加密的,他们返回的数据看上去也就是一些乱码,为了让我们和计算机可以看懂,我们一般都需要使用转码的东东,正常使用最多的就是所谓的utf-8,回到上面代码
1 print(respound.read().decode('utf-8')) 2 print(respound.read())
这两个语句所属出的东西是一样的,但是这是为了理解我们一般都加上,具体区别如下
![]()
这是不加utf-8的
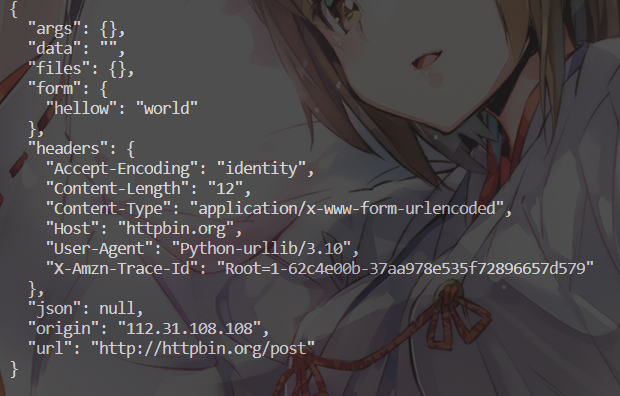
这是加上utf-8之后的,看上去就更像给人看的东西
爬取网站的一些基本东东2
对于很多网站,我们在访问他们的时候不知道会发生什么奇怪的事情,什么超时未响应啊,什么404 not found啊(男生应该深有体会),还有什么418啊(我是一个茶壶,具体梗可以上网搜)总之会有很多错误存在,那怎么让我们的代码可以搞高效的运行而不是在一个问题上就泡汤呢,那就需要使用到我们伟大的谢俊松所说过的异常处理了
异常处理就是except 和try 语句的嵌套,对于try 中所执行的一些语句,我们在except 中提前判断出他会遇到什么阻拦和问题,通过错误码的比较来确保代码的高速运行,困难的点也就很清晰了,怎么提前判断错误就成为了难点,但我们伟大python制作者早就知道了这个状况,这么多年的发展之后,python自己在网页爬取这方面的一个错误库
1 import urllib.error
这一看就是爬虫天天写多了错误太多直接搞一个省事的节奏,但我们还有更加神奇的东西,exception
1 except Exception as e:
只要这样一写,什么错误他都给你包括在内了,可谓是十分的高效。
因此,为了爬取网站,我们都会倾向于使用异常处理的方法来提高效率
除此之外,urllib中还有很多好用的库,
1 import urllib.request 2 respound=urllib.request.urlopen("http://www.baidu.com") 3 print(respound.status)#返回网页的一些预期返回值,没什么用,了解一下就行 4 print(respound.getheaders())#返回该网页的一些基础资料,这个函数是有多少就返回多少 5 print(respound.getheader("date"))#返回特定的资料,注意少了一个s 多了括号里的一个具体字典的名字
这些东西多了解一点总是好的,出去吹牛都更有资本
爬取网站的一些基本东东3
整个爬虫中最困难的东西来了, 现在爬虫这么多,不少网站的安全员又不是傻子,他怎么可能让你随便爬,万一你给自己爬进局子了,他们也会愧疚的,所以在我们朴实无华的使用get去爬取豆瓣的时候就会出现418我是一个茶壶的返回,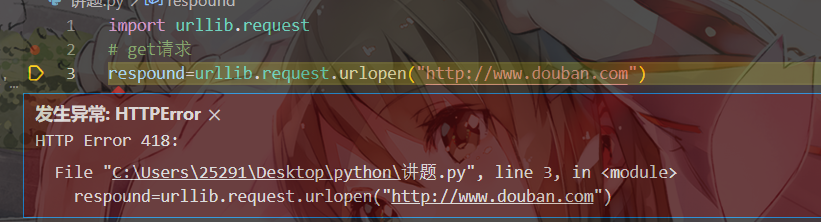
这就是在告诉我们,系统已经看出来我们是个爬虫了,是不可能再让我们访问了,这时候我们就要动点脑子,考虑一下怎么欺骗网站,让他们认为我们是浏览器,在这之前我们必须明白一件事情,我们为啥会被识别出来。细心的小伙伴在观察东东1的那个给人看的返回结果的时候就已经发现了
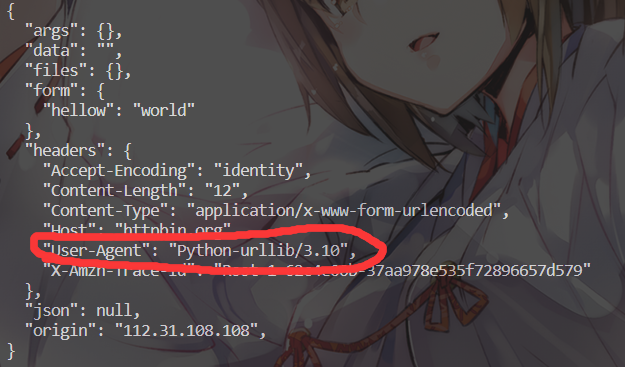
这一句大大的用户是python ,甚至连我们urllib的版本都给人家看了人家能不知道吗,所以我们就需要对这些数据进行修改,让他绝对我们和浏览器是一个东西,而这些数据我们从哪搞呢,那好多什么400.879啥的我们也算不出来啊,没关系,我们电脑里面都有,点开浏览器,按住f12,之后会打开页面代码,在network一栏中我们可以清晰的找到很多浏览器的资料
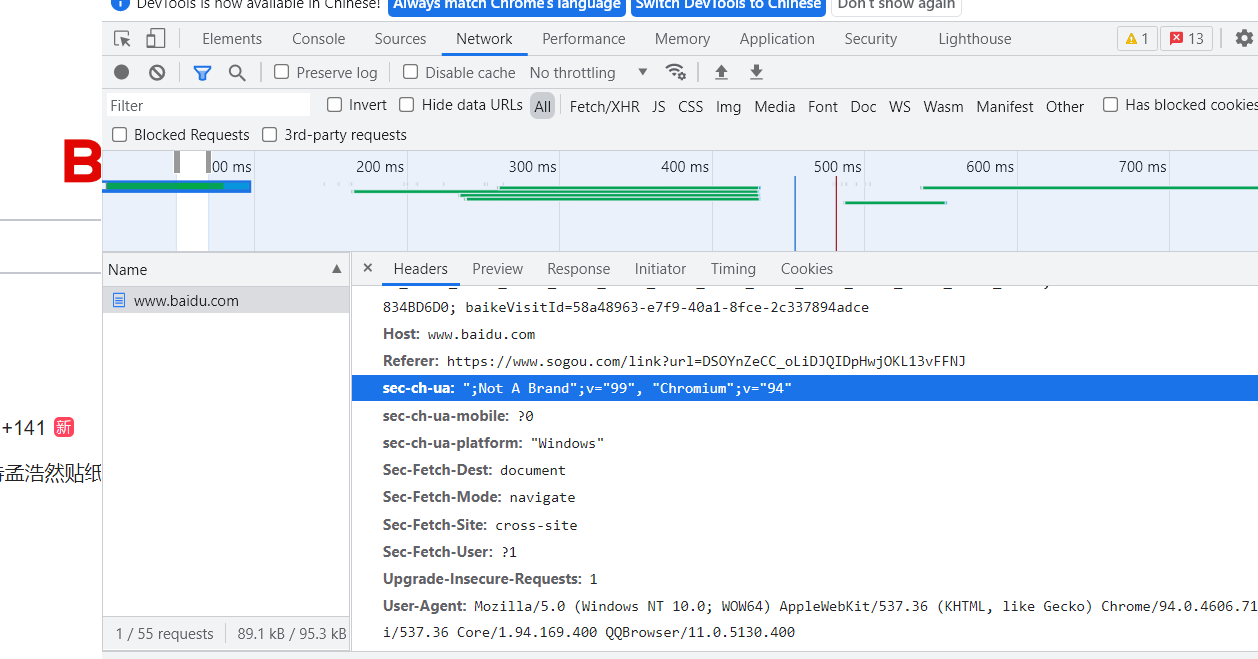
我们只要在我们的代码里面使用get或者post传入这些资料给网站,就可以让他相信我们不是爬虫,具体操作也很简单,我们之前都直接使用urlopen直接打开了那个网站,我们这次要对urlopen 函数进行一些操作
1 url="https://www.movie.douban.com" 2 headers={ 3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.169.400 QQBrowser/11.0.5130.400" 4 }#这是我从我电脑里copy下来的,记得他是一些字典类型,所以要使用字典的方法进行保存,而且字典的名字千万别错 5 data=bytes(urllib.parse.urlencode({"name":"xxxxxx"}),encoding='utf-8') 6 rep=urllib.request.Request(url=url,data=data,headers=headers,method="POST") 7 #我们将我们修改好的一些资料封装在一个交rep的变量之中,当然里面method,data非必须,只是为了加大成功的几率 8 respound=urllib.request.urlopen(rep) 9 #然后用urlopen不打开网站而是打开rep的这个变量,这个变量里就包含了我们伪装的一些数据 10 print(respound.read().decode('utf-8'))
当然,headers字典里并非只能有user-agent 一个名词,越多越好,越多就使我们成功的几率越大,
这一次我们再访问豆瓣,他就相信我们是电脑了,也回馈了一堆网页的资料,由于我们是要爬取很多页的资料,只要用循环就好啦
最终大致代码就是这样: