

神经网络课堂测试
石家庄铁道大学2024年春季
2021 级大数据技术与应用课堂测试
-神经网络计算过程
课程名称:大数据技术与应用 任课教师:王建民
1、用自己的话说明深度学习训练三部群正向传播,反向传播,梯度下降的基本功能和原理。
2、请问人工神经网络中为什么ReLu要好过于tanh和sigmoid function?
3、为什么引入非线性激励函数?
4、根据样例:
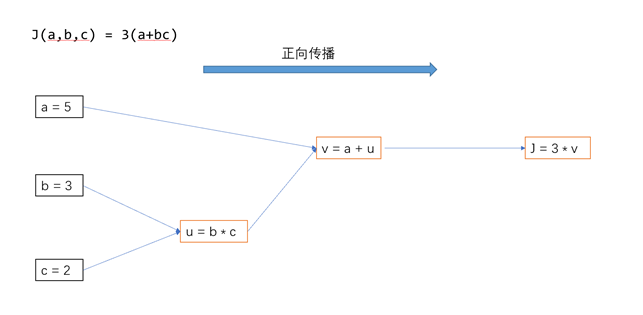
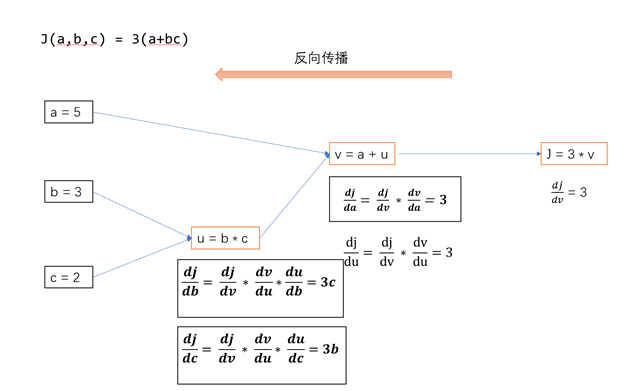
计算出模型正向传播、反向传播的各个神经元的输入与输出。模型中的非线性函数采用Relu,方向传播的损失函数结果为Y。
其中 X1 =1,X2 = -1,要求计算Z_1, Z_2, Z_3,并写出计算过程。
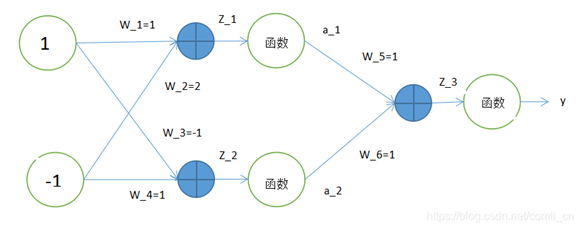
1、
正向传播: 将数据传入到相应的神经网络,从输入数据开始,在神经网络内部,一直到输出结果。每个步骤都会对输入的数据进行加权求和,然后通过激活函数来产生输出,这个输出随后作为下一层的输入继续传递。最后,我们得到网络对于给定输入数据的预测结果。
反向传播: 当得到了相应的预测结果,反向传播来计算预测误差也就是实际输出与预计输出的差异。从输出层开始,向输入层方向每一步计算每个神经元对于最终误差的影响程度。通过链式法则来实现,先计算输出层的误差,然后逐层向前计算每一层神经元的误差。这样,就可以知道哪些权重需要调整以及如何调整它们用来减少误差。
梯度下降:用上一步计算出的误差梯度来更新神经网络中的权重和偏置。权重的改变是通过沿着误差梯度的反方向进行的,是为了减少损失函数的值。损失函数比较了实际和预测的差异。通过不断地更新权重,性能会逐渐提高,直到达到某个满意的结果或条件停止。
2、
不存在梯度饱和的问题,计算非常简单,线性性质,它可以避免梯度消失,不会饱和较高的激活水平,性能和计算效率高。
3、
就是更能理解和处理现实问题,让模型能处理现实世界中的复杂问题。
4、
z_1:1*w_1+(-1)*w_2=1 * 1 + (-1) * 2 = -1
a_1:max(z_1,0)=0
z_2:1*w_3+(-1)*w_4= 1*(-1)+ (-1) * 1 = -2
a_2: max(z_2,0)=0
z_3:0*1=0*1=0
Y=0
