

3.2每日总结
石家庄铁道大学2024年春季
2022 级课堂测试试卷—数据同步练习
课程名称:大数据库技术与应用 任课教师:王建民 考试时间: 120 分钟
一、 数据结构分析:
(1)京津冀三省的2015年度的科技成果数据原始表,为Access数据库,;
(2)要求将三省的科技成果数据汇总到同一表中(要求结果表为MySql数据表);
(3)三个原始数据表结构不一致,要求结果表中包括所有的字段,表达意思相同或相似的字段要进行合并,不允许丢失字段(若只有本表独有字段,在结果表中其他两表数据在该字段填入空值)。
二、 数据同步练习:要求采编程实现三个原始表数据同步功能,将三个表的数据同步到一个结果表中。
三、 数据清洗练习:
(1)重复记录清洗,分析结果表中是否存在重复的数据记录,主要是地域和成果名称相同即判定为重复记录,保留一条记录,并补充其他重复记录中独有的数据字段内容,再删除其余记录。
(2)在结果表中追加年份和地域两个标准维度字段,如果原始表中存在该字段则直接转化成维度字段,若不存在则根据单位名称确定地域字段内容,天津科技成果表中不存在年度字段,则直接将年度维度字段确定为2015年。
四、 数据分析:
根据提供的已知字段名称,自动将科技成果分类,并且分析京津冀三地的科技优势。
五、 将最终的MySQL数据表导入,放入源程序,将文件夹命名为为班级学号姓名提交。
1.汇总表:
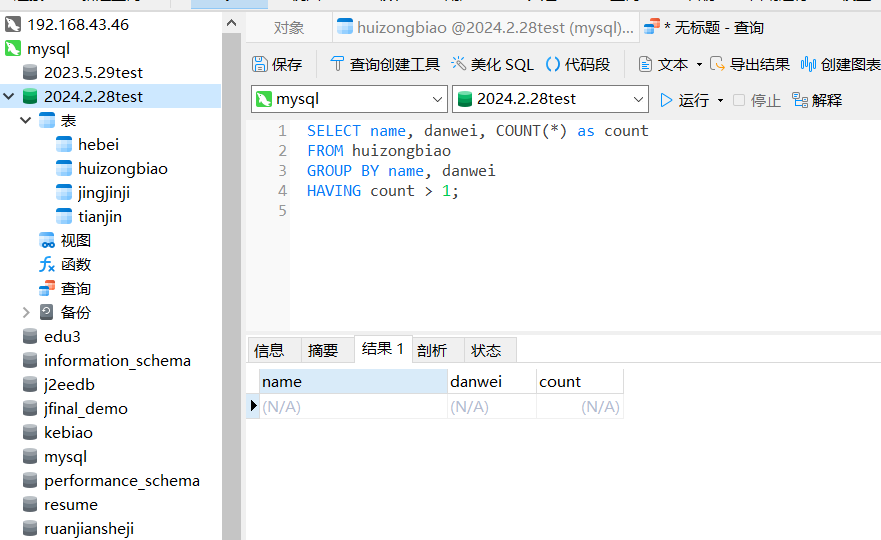
2.数据清洗:
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | import java.sql.*;public class thedataqingxi { public static void main(String[] args) { // 数据库连接信息 String url = "jdbc:mysql://localhost:3306/2024.2.28test"; String username = "root"; String password = "123456"; try { // 连接数据库 Connection connection = DriverManager.getConnection(url, username, password); // 执行数据清洗操作 cleanData(connection); // 关闭数据库连接 connection.close(); } catch (SQLException e) { e.printStackTrace(); } } private static void cleanData(Connection connection) throws SQLException { // SQL查询语句,查找重复记录并保留一条 String findDuplicatesSQL = "SELECT MIN(ID) as minID, name, danwei " + "FROM huizongbiao " + "GROUP BY name, danwei " + "HAVING COUNT(*) > 1"; // SQL删除语句,删除除最小ID外的重复记录 String deleteDuplicatesSQL = "DELETE FROM huizongbiao WHERE ID <> ? AND name = ? AND danwei = ?"; // 执行查询 Statement statement = connection.createStatement(); ResultSet resultSet = statement.executeQuery(findDuplicatesSQL); // 遍历查询结果 while (resultSet.next()) { int minID = resultSet.getInt("minID"); String name = resultSet.getString("name"); String danwei = resultSet.getString("danwei"); // 执行删除操作 PreparedStatement preparedStatement = connection.prepareStatement(deleteDuplicatesSQL); preparedStatement.setInt(1, minID); preparedStatement.setString(2, name); preparedStatement.setString(3, danwei); preparedStatement.executeUpdate(); preparedStatement.close(); } // 关闭Statement和ResultSet statement.close(); resultSet.close(); }} |
3.导出csv文件:
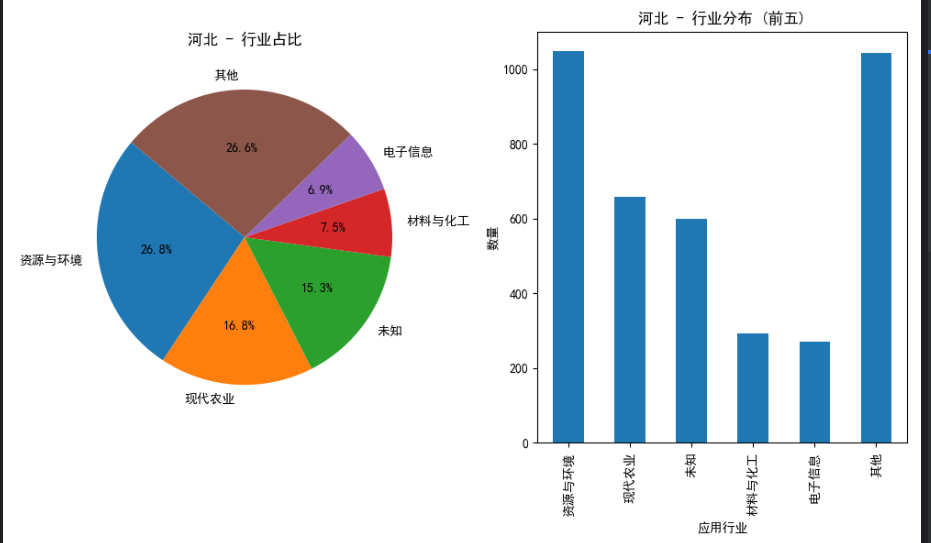
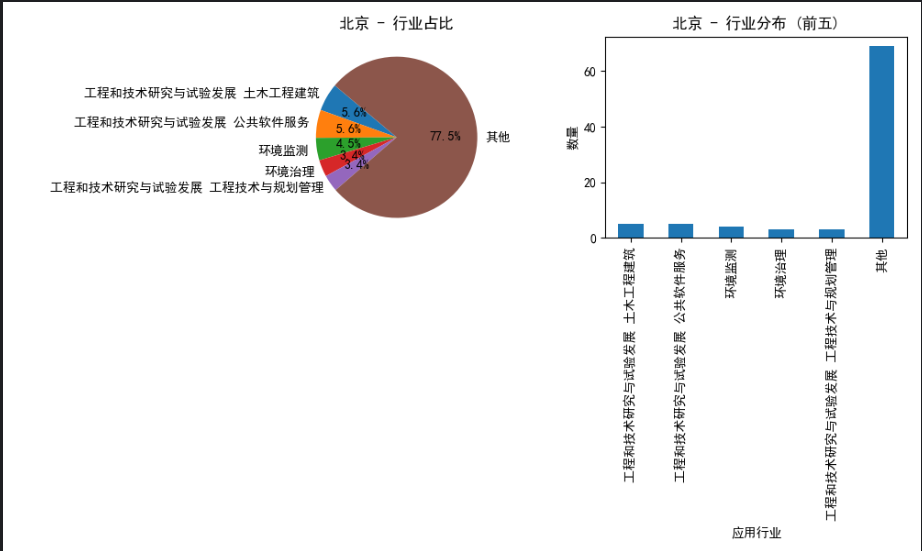
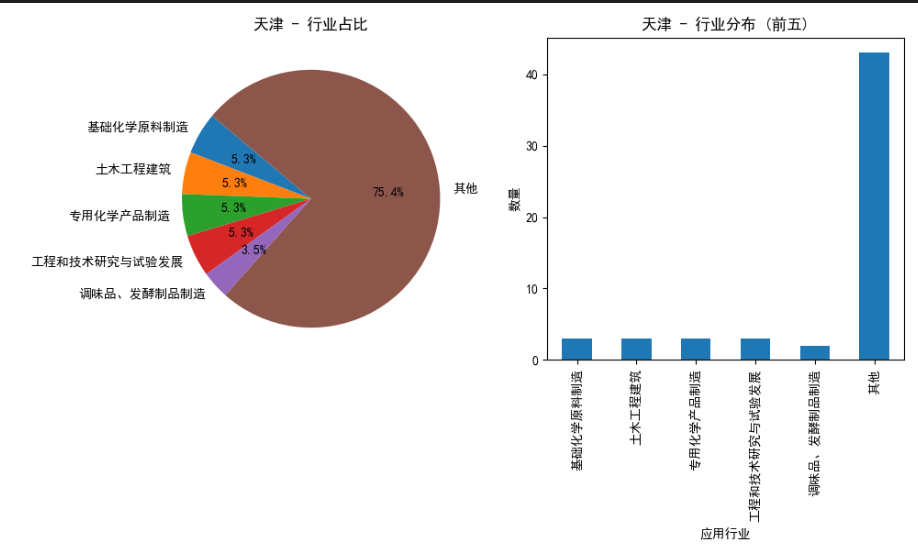
4.数据分析展示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | import pandas as pdimport matplotlib.pyplot as plt# 设置中文显示plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 读取CSV文件df = pd.read_csv('huizongbiao.csv')# 按地区分组并计算各地区的应用行业占比hebei_data = df[df['shengshiqu'] == '河北']beijing_data = df[df['shengshiqu'] == '北京']tianjin_data = df[df['shengshiqu'] == '天津']def plot_pie_and_bar(data, title): # 计算应用行业占比 industry_counts = data['yingyonghangye'].value_counts() # 只保留前五,其余用"其他"代指 top_industries = industry_counts.head(5) other_count = industry_counts[5:].sum() top_industries['其他'] = other_count total_count = len(data) industry_percentages = top_industries / total_count * 100 # 绘制饼状图 plt.figure(figsize=(10, 6)) plt.subplot(1, 2, 1) plt.pie(industry_percentages, labels=industry_percentages.index, autopct='%1.1f%%', startangle=140) plt.title(f'{title} - 行业占比') # 绘制柱状图 plt.subplot(1, 2, 2) top_industries.plot(kind='bar') plt.title(f'{title} - 行业分布 (前五)') plt.xlabel('应用行业') plt.ylabel('数量') plt.tight_layout() plt.show()# 绘制河北地区的图表plot_pie_and_bar(hebei_data, '河北')# 绘制北京地区的图表plot_pie_and_bar(beijing_data, '北京')# 绘制天津地区的图表plot_pie_and_bar(tianjin_data, '天津') |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2023-03-02 3.2每日总结9