大数据作业避坑
https://dblab.xmu.edu.cn/blog/2481/关于这个网站,里面的很多过程和步骤是与我们的不一样的。
对此在朋友的推荐找下到了新的学习网站:https://www.bilibili.com/video/BV1CU4y1N7Sh/?p=43&share_source=copy_web&vd_source=19a8f1ff337e12c295c7860dd5e7a04e
但是里面一部分的可视化操作可能不是全部适用(权限问题)下面是我的操作过程。
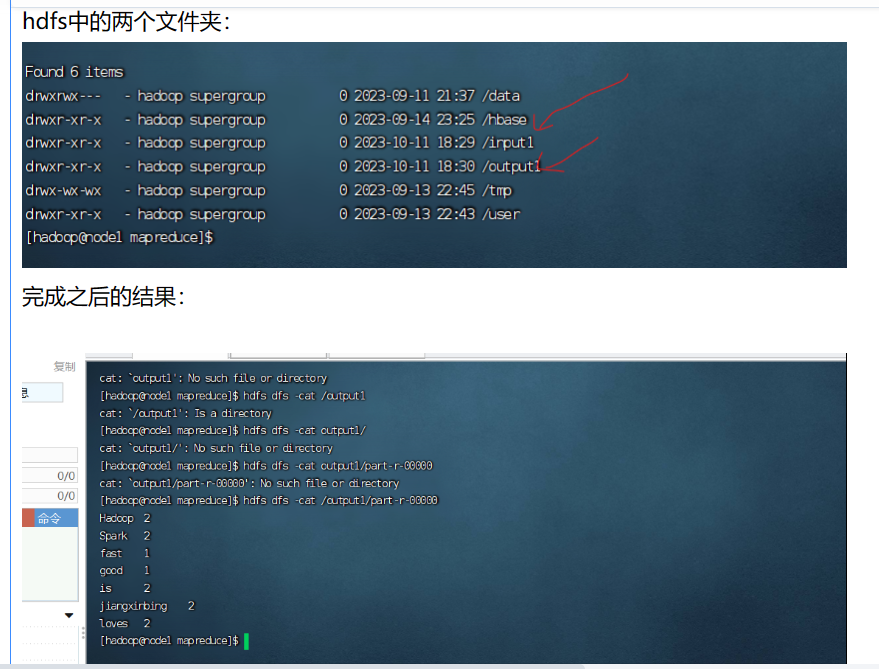
1.按要求创建两个文件如下

2.打开虚拟机连接finalshell
start-dfs.sh
start-yarn.sh
执行上述代码;
3.将创建的两个文件拖到虚拟机的根目录/ 下
4.在hdfs中创建input文件夹(注意插入之前要看看有没有,有可以改名也可以删除)(在hadoop目录下)
hadoop fs -mkdir /input
4.将根目录/的两个文件复制到hdfs的根目录下(在hadoop目录下)
hdfs dfs -put /wordfile1.txt /input
hdfs dfs -put /wordfile2.txt /input
5.执行语句(hadoop目录下)(output同样要检查,有的话可以改名或者删除)
hadoop jar hadoop-mapreduce-examples-3.3.4.jar wordcount /input /output
6.用cat去查,或者在第二个连接里用网址的方式可视化查看