
数据清洗三(缺失处理)
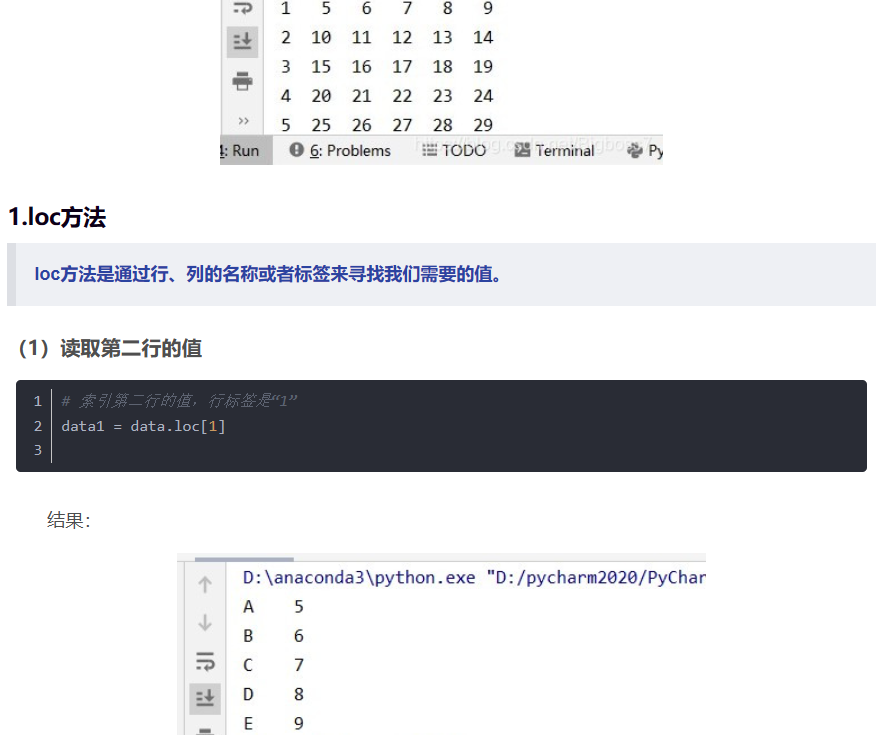
缺失值的处理:Pandas读取某列、某行数据——loc、iloc用法总结_data.iloc用法-CSDN博客 loc 函数的使用方法
#非常重要的列表推导式 #修改出发地是空的,可以将路线名的前两个字段提取出来然后填补到出发地为空的字段中 #首先先将路线名的前两个字段提取出来 [str(x)[:2] for x in df.loc[df.出发地.isnull(), '路线名']]
df.loc[df.出发地.isnull(),'出发地']=[str(x)[:2] for x in df.loc[df.出发地.isnull(), '路线名']]
#str(x) [:2] #将x变成字符串 提取前两个字符 #for x in .... 表示x从哪里来 # df.loc[df.出发地.isnull(), '路线名' ] 表示出发地是空的 路线名
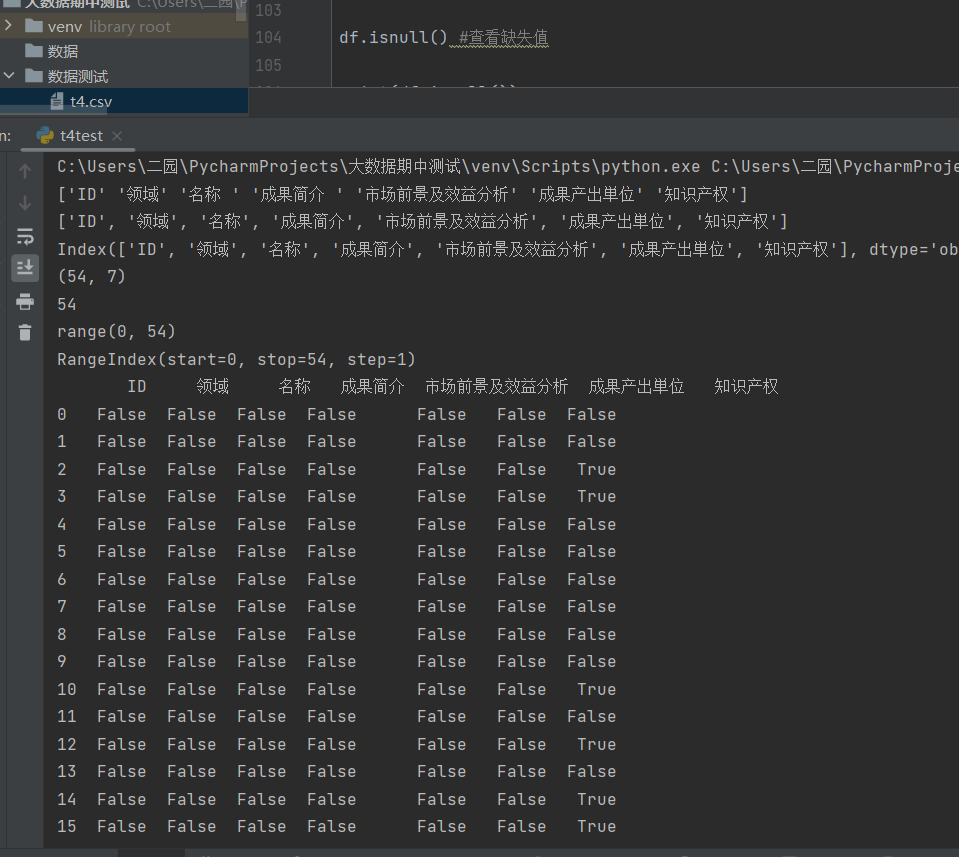
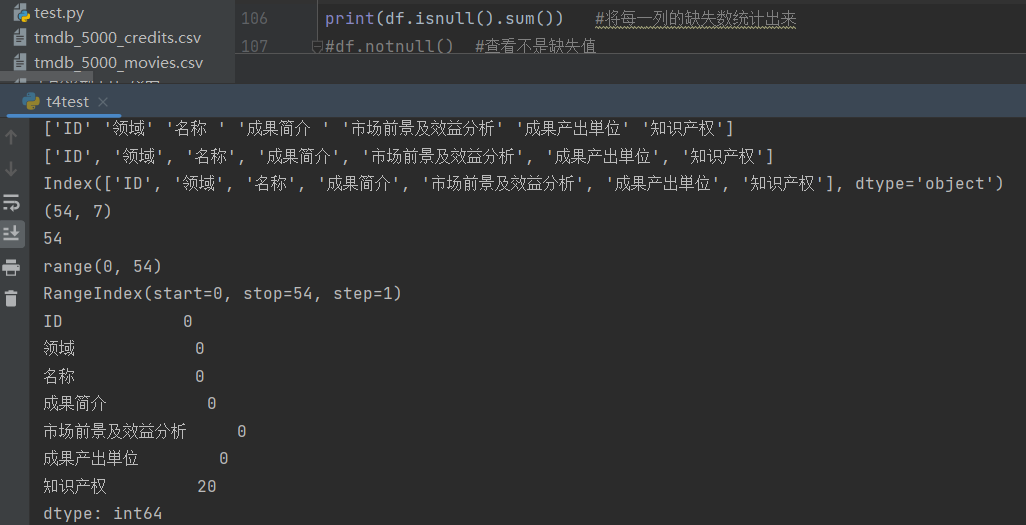
统计每一列缺失值:
价格缺失采用均值填充:
df.价格.mean() #表示价格这一列的均值 #如果均值小数太长用round函数保留几位小数 round(df.价格.mean(),0) #表示保留0位小数
df['价格'].fillna(round(df['价格'].mean(),0, inplace=True)
处理文本型数据:
去除中间空格采用strip函数
从文本数据中采用正则表达式提起出想要的信息
#提取酒店评分 #北京氧化酒店 舒适型 4.7分/5分 df.['酒店评分'] = df.酒店.str.extract('(\d\.\d)分/5分', expend=Flase) #引号里面是规则 \d表示数字 \.表示本来的符号 #expend=Flase (return Index/series) #expend=True (return Dataframe) #然后我们人为的创建出来一个酒店评分这样的列(原先里面并没有酒店评分这样的列) #然后提取酒店等级(舒适性) #观察它的结构,舒适型前面是空格,后面也是空格 df.['酒店等级']=df.酒店.str.extract(' (.+) ', expend=Flase) #引号内部是规则,前后两个空格中间(.+)点加号代表中间的东西全部提取出来 #提取天数信息 df['天数']= df.路线名.str.extract('(\d+)天\d晚',expend=Flase) #\d+表示所有的数字

 浙公网安备 33010602011771号
浙公网安备 33010602011771号