
指数平滑法
- 一次移动平均法
一次移动平均法是收集一组观察值,计算这组值的均值,利用这一均值作为下一期的预测值。当数据的随机因素较大时,宜选用较大的N,这样有利于较大限度的平滑由随机性所带来的严重偏差;反之,当数据的随机性因素较小时,宜选用较小的N,这有利于跟踪数据的变化。
移动平均法的优点有:1. 计算量小;2. 移动平均线能较好的反应时间序列的趋势及其变化。
移动平均法的两个主要限制:1. 计算移动平均必须具有N个过去观察值,当需要预测大量数据时,就必须存储大量数据;2. N个过去观察值中每一个权值都相等,而早于(t-N+1)期的观察值的权值为0,但实际上往往是最近观察的数据包含更多信息,应具有更大权重。
- 一次指数平滑法
一次指数平滑法是一种特殊的加权平均法,对本期观察值和本期预测值赋予不同的权重,求得下一期预测值的方法。这种方法既不需要存储全部历史数据,也不需要存储一组数据,从而可以大大减少数据存储问题。其通式为:
为t+1期的预测值,为t期实际观测值,为权值(也称为平滑系数)。根据通式,t期预测值,将其代入上式中得到
而t-1期的预测值又可以写为:,将其代入上式可得
根据以上规律,通式可以写为如下形式:
由于的取值在0到1之间,所以的值会越来越小,即离t+1期越久远的观测值,对t+1期的预测值的影像越小。式子中最后一项的就是第一期的预测值(初始值),通常可以取第一期的实际值为初值或者取最初几期的平均值为初值(一般分为两种情况:当样本为大样本时(n>42),F1一般以第一期的观察值代替;当样本为小样本时(n<42),F1一般取前几期的平均值代替)。当t很大时非常接近0,所以在式子中的影响并不大。用文字描述该通式就是:对离预测期较近的观察值赋予较大的权数,对离预测值较远的观察值赋予较小的权数,权数由近到远按指数规律递减,所以叫做指数平滑法。
下面举个例子来说明指数平滑法的计算方法。某产品过去20个月的销售数据如下:

C列为指数平滑法计算得到的预测值,F1的值为前三期的平均值,即在C2处输入=AVERAGE(B2:B4),C3处输入,E1的值是指数平滑系数,C3中引用到E1的值需要有绝对引用,这样把C3处的公式下拉复制到C21时,公式永远都是引用E1的指数平滑系数。得出来的结果如下图:
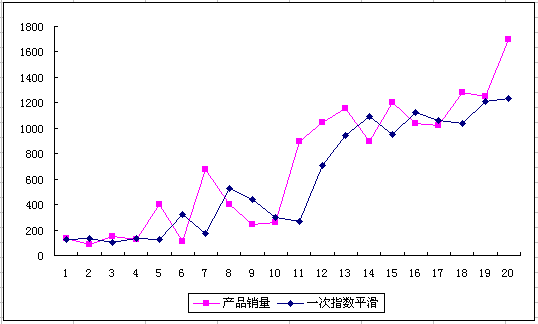
可以看到,指数平滑法进行预测,是有滞后作用的,这是指数平滑法的一个缺点。要对第21期进行预测,只需在A22处输入21,把公式下拉复制到C22即可。
一次指数平滑法比较简单,优点在于它在计算中将所有的观察值在考虑在内,对各期按时期的远近赋予不同的权重,使预测值更接近实际观察值。但是也存在一些问题,问题之一是要找到合适的α值,以使均方差最小,这需要通过反复试验确定。
- 二次移动平均法
二次移动平均法,是对一次移动平均数再进行第二次移动平均,再以一次移动平均值和二次移动平均值为基础建立预测模型,计算预测值的方法。运用一次移动平均法求得的移动平均值存在滞后偏差。特别是在时间序列数据呈现线性趋势时,移动平均值总是落后于观察值数据的变化。二次移动平均法,正是要纠正这一滞后偏差,建立预测目标的线性时间关系数学模型,求得预测值。二次移动平均法适用于有明显趋势变动的市场现象时间序列的预测。线性二次移动平均法的通式为:
式中,为第t期的一次移动平均值;为第t期的二次移动平均值;N为计算移动平均值的跨越期;T为预测超前期数;为截距,即第t期现象的基础水平;为斜率,即第t期现象的单位时间变化量。
- 二次指数平滑法
○ 布朗单一参数线性指数平滑法
其基本原理与线性二次移动平均法相似,因为当趋势存在时,一次和二次平滑值都滞后于实际值,将一次和二次平滑值之差加在一次平滑值上,则可对趋势进行修正。
下面以某省农民家庭平均每人全年食品支出数据为例,用二次指数平滑法(取参数a=0.8),计算历年的理论预测值和2005年的预测值,并计算平均绝对误差。
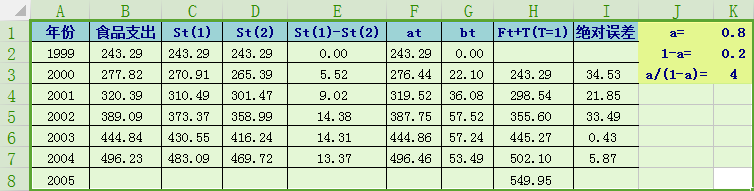
在二次指数平滑法中,和是为了计算最终预测值服务的平滑值。列从第二行起的计算公式为:"";列从第二行起的计算公式为:""
若要预测2005年的值:F05=a04+b04*T=496.46+53.49=549.95元。其余类推。
○ Holt双参数线性指数平滑法
霍尔特指数平滑法有两个基本平滑公式和一个预测公式,两个平滑公式分别对时间数列的两种因素进行平滑,它们是:
公式中:、为平滑参数;为实际观察值;T为外推预测时期数。第一个公式利用前一期的趋势值直接修正平滑值,即将加前一期平滑值上,这就消除了滞后,并使近似达到最新数据值;公式2是来修正趋势值,趋势值用相邻两次平滑值之差来表示,由于随机性,可以利用平滑系数对两次相邻平滑值之差进行修正,并将修正值加上前期趋势值乘以。
初始值S1通常设为x1,b1的初值可以按照下列三种方式之一确定:
用霍尔特指数平滑法进行预测时,最重要的工作是确定平滑参数、的取值,平滑参数的取值适当与否,决定预测的精确程度。
参考:
Forecasting by Smoothing Techniques
Filters skeleton positions to reduce jitter between frames



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律