



吴家劲--第一次个人编程作业
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | 采集腾讯视频里电视剧《在一起》的全部评论信息做成词云 |
| 作业源代码 | https://github.com/chaser886/first-personal-work/tree/main |
| 学号 | 211808527 |
- 统计
| 代码行数 | <填写这份作业所在的博客班级的链接> |
|---|---|
| 代码所分析时长 | 2h |
| 代码实现 | 1h |
| 数据收集 | 3h |
| 数据处理 | 4h |
| 数据分析展示 | 3h |
| 博客编写 | 1h |
- 数据采集
首先进入腾讯视频,找到在一起评论页面,查看源代码

通过点击更多评论发现 每点击一次 name便会增加一条,所以评论区为加载内容
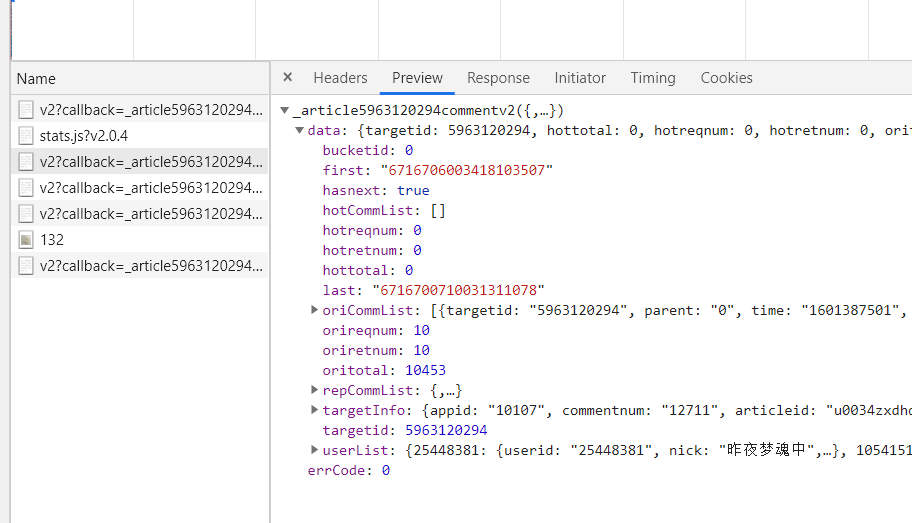
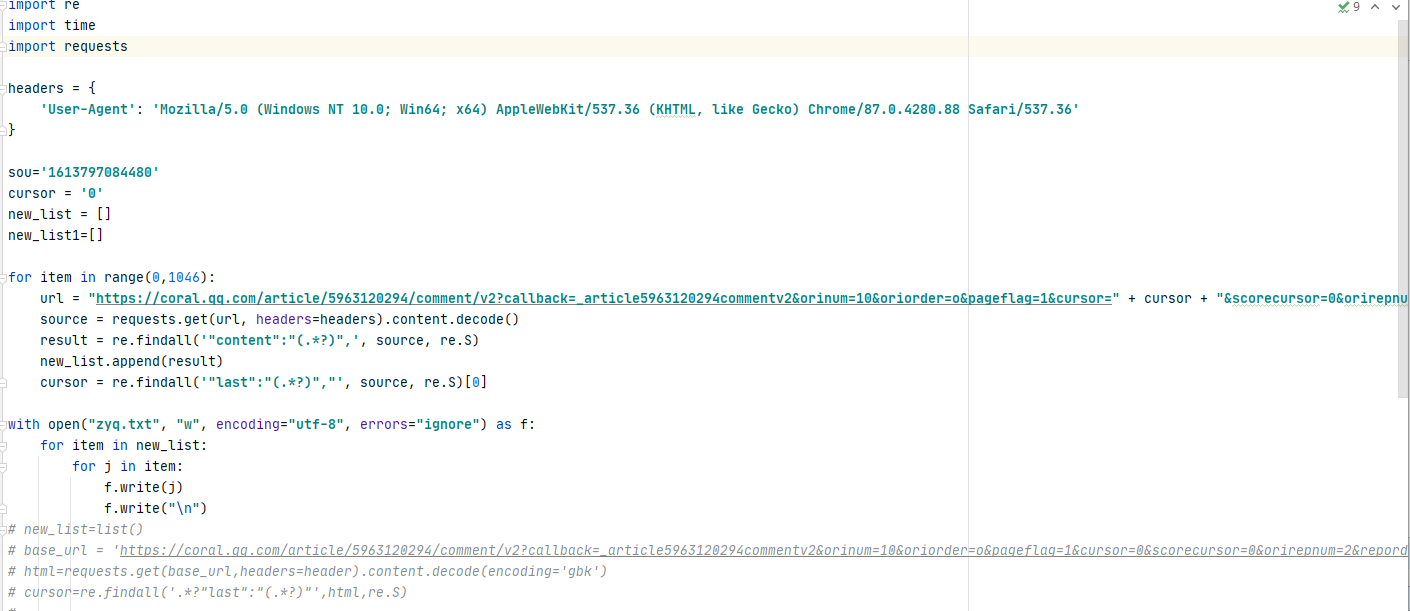
此外页面主要通过改变cursor和source的数值来进行改变,每加载一次更多评论,source便加一,cursor起始值为0,在查找发现后cursor在每一个页面的,我们可以通过正则表达式来爬取评论
- 数据处理
在pycham中安装jieba 然后利用jieba进行分词 进而进行词频统计

-
词云图

-
git的相关操作
git clone 远程仓库地址
git branch:查看当前所有分支
git branch crawl、chart:创建crawl分支、chart分支
git checkou:切换分支
git push origin:分支推送到远程仓库
git status::查看分支状态 -
困难以及解决
第一个就是爬虫有点忘了,代码还是请教了一下同学,然后还有一些没有学过的知识,还是请求同学的帮助还有就是百度。

