

许文豪——第一次个人编程作业
| 博客班级 | 2018级计算机和综合实验班 |
|---|---|
| 作业要求 | 第一次个人编程作业 |
| 作业目标 | 运用各种工具能进行数据采集、数据处理以及数据展示 |
| 作业源代码 | github地址 |
| 学号 | 211808334 |
| 代码行数 | 599行 |
|---|---|
| 准备工作 | 差不多用了一天时间 |
| 爬取评论数据 | 5小时 |
| 使用jieba分词 | 4小时 |
| 使用js渲染词云 | 3小时 |
一、爬取《在一起》评论数据
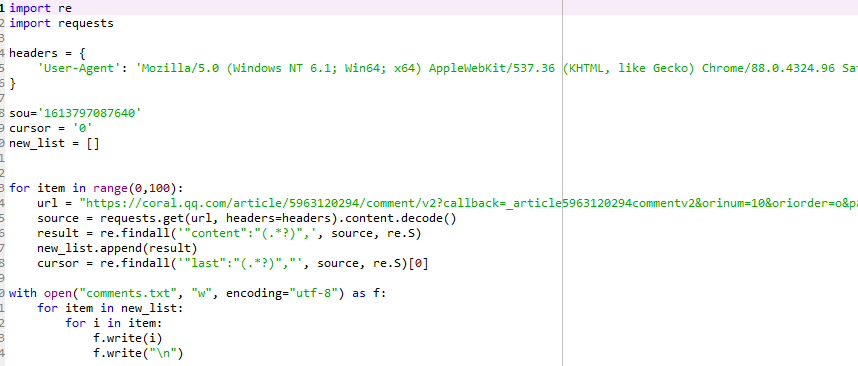
在开头爬取数据就遇到困难,上学期学的爬虫知识有一些模糊了,于是花了几个小时去复习了正则表达和异步加载的知识,在多次磕磕碰碰下终于完成了对评论数据的爬取,依旧使用Spyder进行数据爬取
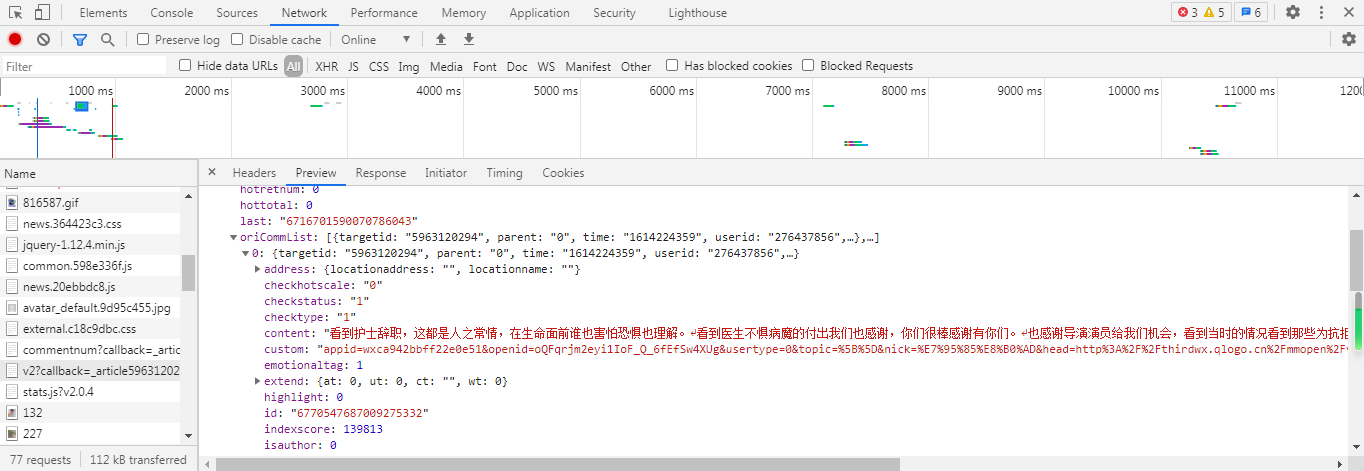
按F12打开
将页面拉至列表最下面,可以看到评论的信息都在v2?=callback=_article内
进行研究后发现页面主要通过Request URL中的cursor值和source的值来加载更多的评论,找到关键点后经过数次尝试成功爬取了评论数据
这是爬取评论数据的代码
二、使用jieba对爬取后的数据进行处理
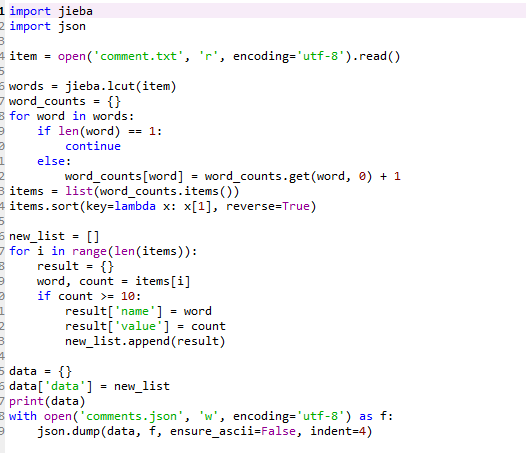
jieba是从未接触过的新领域,在查阅资料的过程中也对jieba有了一定的理解,但最后还是在互联网上寻找了一些模板,并自己进行了修改,请教了一些同学之后也成功完成了对评论里高频词的提取
这是使用jieba分词的代码
三、使用echarts.js插件对词云进行渲染
在echarts的官网摸索了很久,也不知道如何下载,最后向同学要了echarts的下载包。在网上搜索了词云的相关知识,寻到了几套模板,经过多次的代码修改,逐渐明白了大部分代码数据的意思,将用jieba分词后的数据导入其中,最后得到了词云图
大概的效果如下

本来有打算使用其他更为精美的模板,但总是无法生成,最后只好使用自己修改的基础版的图形
四、遇到的问题
1、对爬虫的知识还是不够熟练,今后闲暇之余会将爬虫的知识进行巩固与提升
2、对echarts.js插件的使用还是停留在表面,将作业完成后会对echarts.js插件的使用再进行更深层次的学习,争取能将echarts.js插件使用得更好
3、在开始作业前花了较长时间对git进行了一个全方位的了解,了解到git的种种精妙的使用方法,并在使用过程中对于git有了更深刻的理解。但对git的使用还是十分粗糙,仍然无法做到游刃有余。光是在分支的创建与合并就遇到许多问题。如出现pathspec 'master' did not match any file(s) known to git、nothing added to commit but untracked files present、Everything up-to-date等问题
五、总结
希望以后能提高效率,在发现问题、解决问题的过程学到更多有用的知识。
六、查阅的资料
Commit message 和 Change log 编写指南
Git教程简介
Python爬虫实战:爬取腾讯视频的评论
“结巴”中文分词:做最好的 Python 中文分词组件
Python基于jieba的中文词云
echarts如何实现关键词云图
echarts 简单词云制作,自定义图案词云echarts-wordcloud.js
创建与合并分支
Git问题Everything up-to-date解决
nothing added to commit but untracked files present
Git使用之(pathspec master did not match any file(s) known to git)
