夏子恒——第一次个人编程作业
| 这个作业属于哪个课程 | 2018级计算机和综合实验班 |
|---|---|
| 这个作业要求在哪里 | 第一次个人编程作业 |
| 这个作业的目标 | 爬取网页信息,基本的数据处理(分词),学习使用echarts插件,绘制html页面,进一步熟悉GitHub的使用 |
| 作业源代码 | first-personal-work |
| 学号 | 211808331 |
大致流程
| 事项 | 时间 |
|---|---|
| 选题确定及准备 | 2-3d |
| 数据采集 | 2d |
| 数据处理 | 5h |
| 绘制html词云图 | 3h |
| 博客编辑 | 2h |
前期
- 这次作业刚发布时,我简单看了一下作业要求内容,说实话我是拒绝的o(╥﹏╥)o。毕竟上一次作业才做完不久,喜庆的新年也还未完全结束
(其实主要是爬虫掌握的实在不咋滴...),突然就一份“难搞”的作业砸我脸上,我直接@#¥#%¥#**……。虽然挣扎了几天,但随着提交时间的临近以及陆续有同学提交作业,我也还是准备试着做一做。 - 既然决定要试着做一做,那就得选择一个题目。因为爬虫实在辣鸡,起初是想选题目二疫情地图的,毕竟有现成的数据,但是上手尝试之后发现...爬数据是不用了,但是之后的数据处理实在是搞不太来,拿到数据也整不出个名堂来(裂开),即便查阅一些资料也不太明白,再加上选择题目二的同学比较少,没有什么可以问的同学,实在难以上手,最终只能作罢。
- 在这期间也看了许多同学交的作业,空余时间也看了一下第一题,简单思考了一些,查了一部分相关资料,复习了一点之前的爬虫知识。于是在放弃第二题之后转向了第一题……
中期
- 首先爬取数据,进入腾讯视频电视剧《在一起》第一集页面后滑到页面底部查看评论,按F12并刷新,点击底部的查看更多评论

- 展开后可以发现评论都在‘content’中,并且存放在这个链接中



- 进一步查看后发现,每一页的评论URL只有两串数字不同。并且后面那串是上一页+1。前面那串看似没有规律。


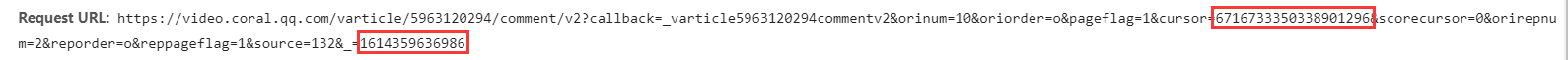
- 但打开URL便发现last中的数值正是下一页cursor=中的数值,之后的页面也依旧如此。


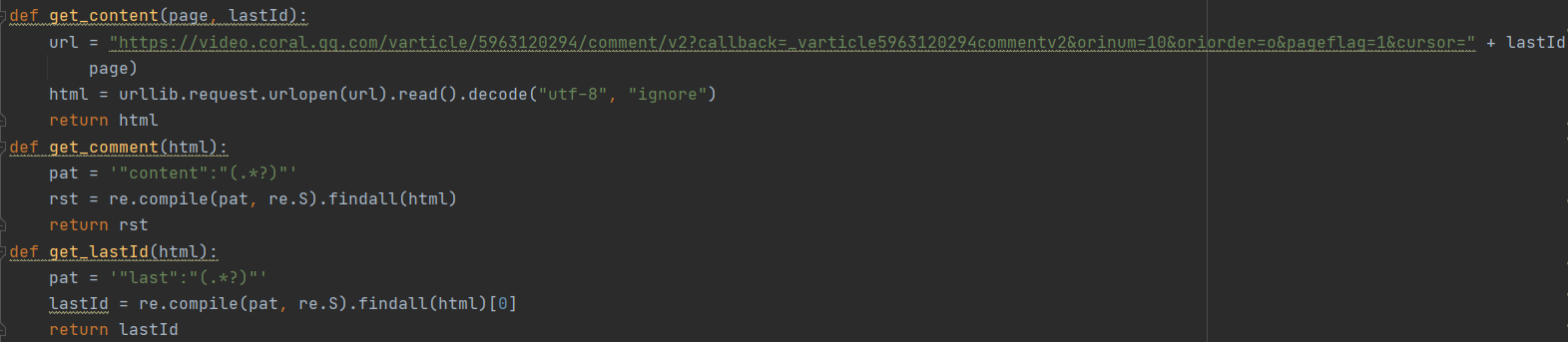
- 综合上述规律进行爬取,部分代码如下。
- 以下是爬取的部分评论数据。
- 评论数据爬取完之后,就是进行分词,简单看了后选择了jieba分词器。因为之前没有用过pycharm还特意查了一下pycharm如何安装模组...但是不知道为什么一直安装不下来,老是等了半天然后告诉我超时安装失败???尝试多次还是不行之后没办法直接用python,结果还是没有安装成功,这一波下来就浪费了不少时间[○・`Д´・ ○]。最后询问同学之后为了节约时间直接把安装后的文件拷贝到python文件夹下了...
- 解决了jieba的安装之后开始分词,使用比较生疏也是在同学的帮助下才完成。以下是部分代码。

- 部分分词数据。

后期
- 分词完成之后就是绘制词云图了。echarts插件第一次接触,也是通过询问同学才成功安装以及初步了解如何使用。我最终截取了部分数据绘制词云图,网页效果如图。

- 最后将文件上传到GitHub即可。因为是全部弄完才上传所以emmmm……QAQ。
复盘
- 虽然过程艰难痛苦,但总归是把这难搞的作业磨完了。主要一方面之前学过的内容掌握的不太好再加上遗忘,实际用起来还是比较困难;另一方面在第一点的基础上,遇到一些新的东西的学习上也有些困难,以及这方面相关的学习能力不够强。
也许这也是我坚定考公的原因之一吧,不过技多不压身,即便以后真的走上了公务员这条路,还是希望学过的东西在需要的时候能用上吧。- 不过通过这次作业收获也是有的,毕竟整个过程对我来说也不算短了,期间查阅的东西,看到的学到的新东西也还是有那么一些些的,以及之前掌握的不好的知识,遗忘的知识也得到了些许的加强。
参考资料
究极福利带你Python爬虫| 爬取腾讯视频评论
jieba
echarts官方教程
廖雪峰git教程
Git与GitHub笔记

