第二次结对作业:班级成绩表
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018SE1/homework/11250 |
|---|---|
| 作业目标 | 学习动态获取网页信息,结对编写代码 |
| 作业源代码 | https://gitee.com/hzl123666/pair |
| 队员1 | 211806384 |
| 队员2 | 211806418 |
| 各个阶段 | 预估时间(h) |
| ------- | -------- |
| 计划:明确需求和其他因素,估计以下各任务要的时间 | 3h |
| 开发 | |
| 需求分析 | 2h |
| 具体设计 | 8h |
| 具体编码,同步复审 | 20h |
| 报告 | |
| 总结报告 | 3h |
| 代码行数 | 100 |
|---|---|
需求分析
-
客户要求
- 阿荣嫌弃要先从网络上下载网页,再爬取云班课成绩,要求的是制作一款爬虫小程序,可以通过网址直接爬取课堂完成部分的经验值并根据最高经验值排序和获得最高经验值,最低经验值和平均经验值。
-
需求分析
- 首先明确需要的是课堂完成部分的经验值,从云班课可知有多个课堂完成部分的作业,但只能利用一个网址进行爬取数据。就是在云班课的活动页面爬取所有课堂完成部分的网址,并对进入这些爬到的网址里获取学生获得经验值,姓名和学号。最后汇总进行计算,排名,按照阿荣的要求将爬取到的数据写入txt格式的文件。
- 首先明确需要的是课堂完成部分的经验值,从云班课可知有多个课堂完成部分的作业,但只能利用一个网址进行爬取数据。就是在云班课的活动页面爬取所有课堂完成部分的网址,并对进入这些爬到的网址里获取学生获得经验值,姓名和学号。最后汇总进行计算,排名,按照阿荣的要求将爬取到的数据写入txt格式的文件。
代码思路与分析模块
-
代码思路
- 爬取所有的课堂完成部分的url
- 将爬取的url作为参数传入爬取经验值学号姓名的函数,获取到每个人的经验值
- 建立学生对象 将爬取到的姓名学号经验值保存到学生对象
- 根据学号将每个课堂完成部分的经验值进行累加并按照格式写入txt文件
-
代码模块分析
-
所有课堂部分的网址和cookie遍历

-
传入参数,对名字学号进行遍历
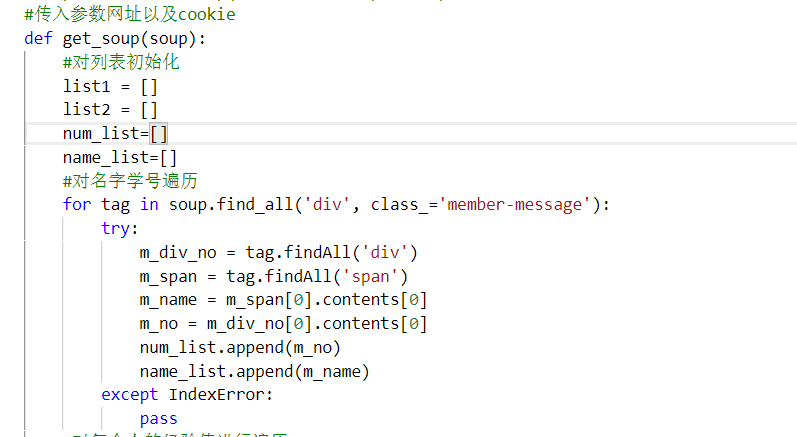
-
每个人的经验值进行遍历txt
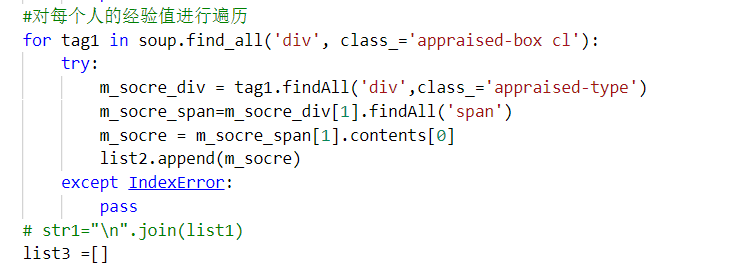
-
得到的数据写入txt文本

-
学习过程及不会知识点
-
成员1 杨显之:
- 一开始我决定和何梓枥同学,分开行动,我用java写,他用python写。有也可能我搜索的资料太过于繁琐,要用Maven进行管理还有HttpClient+jsoup,看到有些还要用Webmagic,第一步弄maven就搞了一个晚上,各种出错,当时何梓枥同学已经用python获取网页内容,感觉java没有python快,我就和何梓枥同学一起,当他领航员。
-
成员2 何梓枥:
- 当我看到这个题目我一眼就想到用python爬虫,因为在疫情期间有去自学python爬虫慕课,只能说有个大致了解。然后我就开始下载python,一开始我是用sublime3写代码,后来感觉写的不是很舒服老是报错,就去下了一个VScode(很香),有代码自动对齐功能就不会因为一些语法而报错。一开始用request库,beautifulsoup库来入手爬取网页,但是重学一门新的语言是真的困难,各种百度,各种问助教,最后只是实现了部分功能,希望能继续学习爬虫完善所所有的功能。
-
不会知识的解决


结对过程,感受,对方评价
-
结对过程:
- 我们是舍友,所以结对过程很自然,并且都对学习有很大的兴趣。我们经常一起研究作业和代码,所以这次结对比较顺利。
-
杨显之对何梓枥的评价和结对感受:
- 何梓枥同学学习能力极强,学习效率比我高很多,学习不容易被打扰,很自律。对于编程还有自己独特的理解,这次结对编程的感受就极强,有几天都一直敲到凌晨2,3点,我到一点就困到不行,提前睡了,他还在敲代码,而且还是用python写的,短短几天就能初步掌握一门语言,很厉害,respect。
-
何梓枥对杨显之的评价和结对感受:
- 太谦虚了,很有团队意识,奖学金获得者,在这次结对作业中,孜孜不倦的学习java爬虫,百度了各种教程,也是非常努力的去学习,虽然这次作业完成的并没有那么出色但是已经付出了努力,学习新的东西也是值得的。
- 太谦虚了,很有团队意识,奖学金获得者,在这次结对作业中,孜孜不倦的学习java爬虫,百度了各种教程,也是非常努力的去学习,虽然这次作业完成的并没有那么出色但是已经付出了努力,学习新的东西也是值得的。
结对照片

参考资料
https://www.cnblogs.com/my_captain/p/9294829.html
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/

