第二次结对作业:班级成绩表
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018SE2/homework/11248 |
|---|---|
| 作业目标 | <制作网页爬虫软件,将云班课上全班的课堂完成部分的经验值爬取下来,根据经验值排序,看看自己和自己的同学在全班第几名,同时计算出平均经验、最低经验、最高经验。> |
| 作业源代码 | https://gitee.com/wang-jingjing/pair |
| 队员1 | <211806394> |
| 队员2 | <211806408> |
结对的过程

结对的感受:
在此次的结对编程中,有了第一次的编程作业后我们更快速上手,并且由于我和晶晶同学是舍友,交流就更加方便,面对面的沟通使我们的作业更加容易完成。 结对编程中,双方的互动目的在于开启思路,避免单独编程时思维容易阻塞的情况。
对对方的评价:
- 我对王晶晶同学的评价:
晶晶精力特别旺盛,并且思维活跃,一开始我担心没接触过爬虫,可能会很难完成此次作业,但是晶晶经过一番研究,通过百度以及借鉴写好作业同学的经验来获取数据。在代码问题上(由于我们是借鉴林佳森同学的代码并且经过他本人的同意),出现问题她及时找林佳森同学请教并一个个去修改错误的地方。虽然一开始出现问题很烦躁,但是晶晶能够很快调整状态,静下心来找问题。【特此鸣谢林佳森同学】 - 王晶晶同学对我的评价:
雪凡非常地敬业,爱学习,原本回家的她,听说要写代码了,二号连夜飞奔回来,宿舍还没人给开门,在门口特别凄惨。雪凡特别的沉着冷静,在我浮躁的时候不断地安慰我,让我不要急躁慢慢来,真的是爱了这样的雪凡了。雪凡文采也很好,本文由她出品,称不上上等品,但绝对nice。这样的搭档,爱了爱了。
分析
代码行数:
| 代码行数 | 196行 |
|---|---|
| 需求分析时间 | 2h |
| 编码时间 | 3h |
思路
1. 理解爬虫,首先搜索引擎,其次数据挖掘
2. 通过爬虫获取云班课上的经验地址和cookie

3. 将所有活动都分成div小块,再获取课堂完成部分的div小块,从中获得每个活动的网址
_
4. 将一个网页中每个人的情况分成div小块,获得各个人的学号,姓名,经验值,并存入集合

5. 实现用排序显示最高分、最低分、平均分并保存为txt文件

6. 获取网址并存入数组;获取名字,学号,经验值并存入对象集合
7. 通过正则表达式获取想要的信息
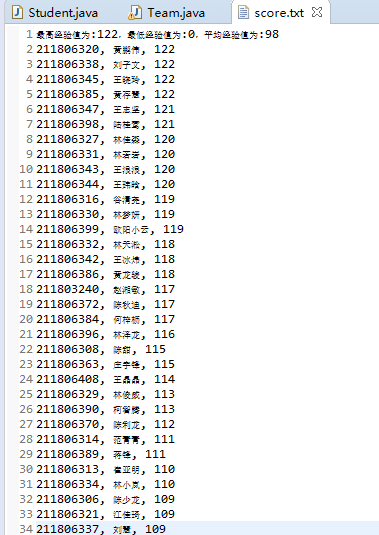
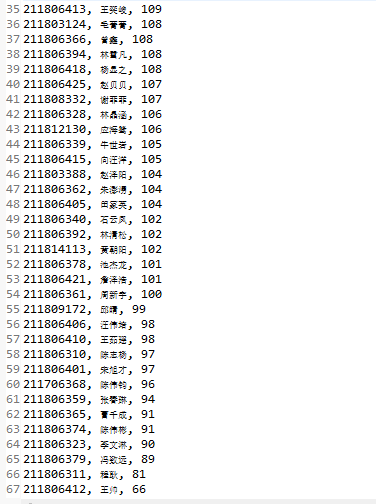
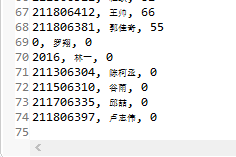
8. 最终显示结果如图:
遇到的困难
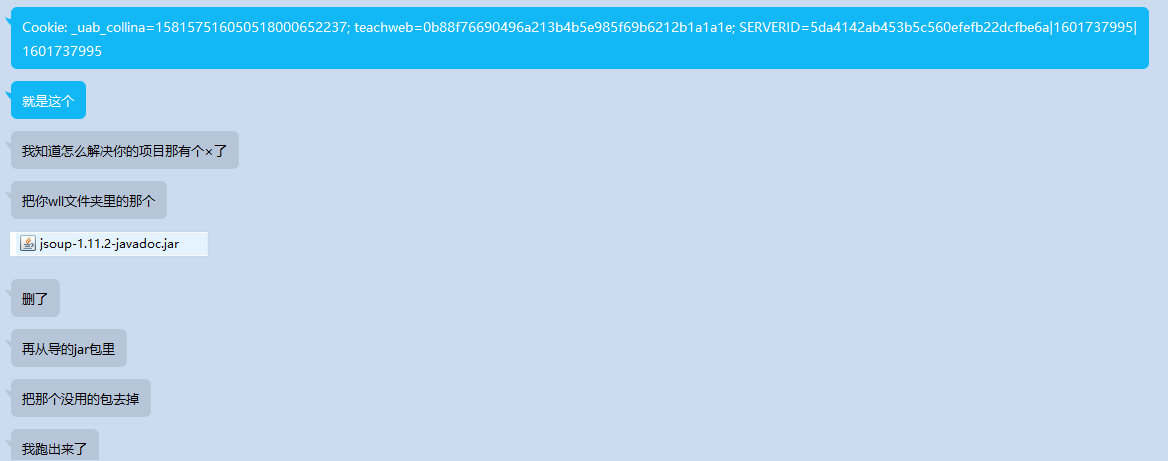
cookie跑会报错
这个问题费了我们很大的时间,但是感谢林佳森同学的热心解答,在将近半小时后终于找到了问题所在!!!
附上解答截图:
参考链接
[导入cookie]:(https://www.cnblogs.com/jamaler/p/11645569.html)
[java爬虫遇到的困难]:(https://blog.csdn.net/z694644032/article/details/102452844)
[林佳森]:(https://gitee.com/houdini/pair/tree/master)
鸣谢
在这里要真诚感谢林佳森同学的热心解答,这次的作业出现的问题他可以很耐心地回答,这个精神令人感动,牺牲了自己的假期时间帮助别人!我们一定向他学习!!!