第二次结对作业:班级成绩表
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzzcxy/2018SE1 |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018SE1/homework/11250 |
| 作业目标 | 通过网络爬取云班课的数据 |
| 作业源代码 | https://gitee.com/wang-bingwei/pair |
| 王冰炜 | 211806342 |
| 徐笑龙 | 211806354 |
| 预估时间(小时) | 实际时间(小时) | |
|---|---|---|
| 计划 | ||
| 需求分析 | 5分钟 | 5分钟 |
| 具体设计 | 1 | 1 |
| 开发 | ||
| 编码 | 8 | 5 |
| 测试 | 0.5 | 2 |
| 记录与总结 | 1 | 1.5 |
| 合计花费时间 | 10.5 | 9.5 |
代码行数:315
1.结对的感受
徐:此次结对,由于是第二次结对合作编程,一回生两回熟,比第一次合作更加默契了。
王: 逆境是人生最好的导师;逆境中人,往往受到了环境和逆势的极限考验,深深地领悟了什么叫生杀予夺,什么叫山重水复疑无路,柳暗花明又一村。这是一次紧张的极限编程挑战,带来全新的体验,项目进展速度令人惊喜。
2.对对方的评价
徐:“哪里有天才,我是把别人睡觉的工夫都用在写代码上的。”队友王冰炜如是说。强如阿伟,通宵完成了代码,我认为他是个非常认真负责兢兢业业的队友,为他的努力点赞
王:“感激每一个新的挑战,因为它会锻造你的意志和品格。”队友徐笑龙如是说。共同的项目,共同的难题,可以使人产生忍受一切的力量。为队友不畏艰险迎难而上精神点赞!
3.需求分析
-
需求分析
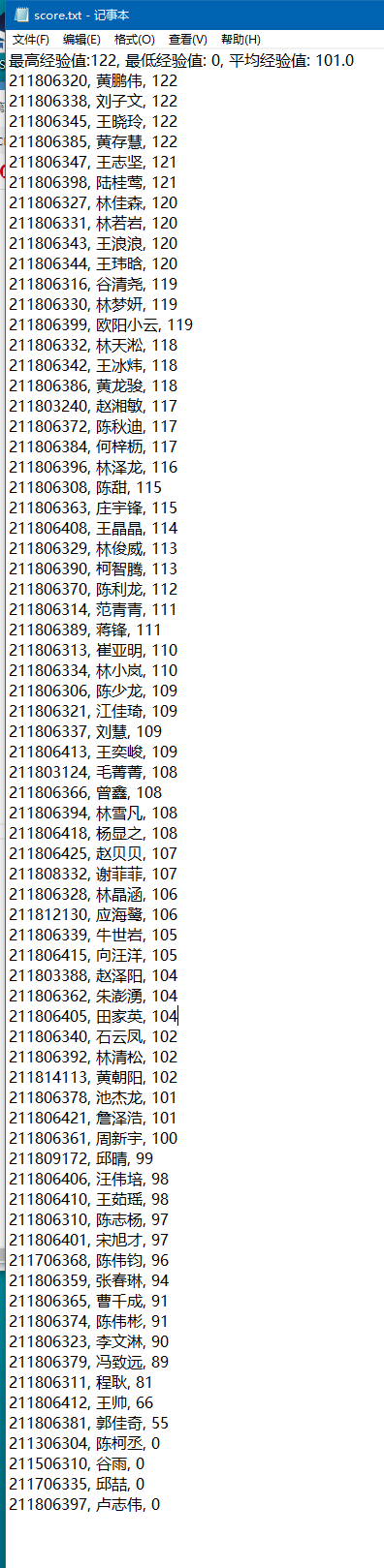
通过网络爬取云班课上,全班的课堂完成部分的经验值,根据经验值排序,同时计算出平均经验、最低经验、最高经验。最终输出至文本文件score.txt
-
9月28日
- 制定流程,明确有几个步骤;

-
与搭档进行短暂沟通,确认思路无误;
-
与助教沟通,再次确认思路无误;
- 9月29日
- 推送第一版程序,实现作业要求;
- 第一版对一些步骤没有进行封装,可读性不够强,后续继续跟进优化;
- 对HttpClient的使用仅停留在能完成作业的水平上,后续要继续学习;
- 此次为初试极限编程,还不太适应这种高强度的工作方式,以后可多加训练;
-
结对照片

4.记录不会的知识的学习过程,记录修改优化的过程
1. 初期:针对目标数据进行静态抓取
经过第一次的编程作业,面对抓取页面特定区域的信息已是手到擒来;故在这一阶段直接上手,保存几个目标页面的html文件至本地,格式化代码后立即进行分析。
这次作业要筛选的数据有三,它们分别是:
-
活动页面各章节:课堂完成页面的URL地址
Elements es1 = document.getElementsByAttributeValue("class", "interaction-rows"); for (Element element1 : es1) { Elements es2 = element1.getElementsByAttributeValue("class", "interaction-row"); for (Element element2 : es2) { if (element2.toString().contains("课堂完成部分")) { //获得某一次课堂完成活动页面的URL String url = element2.attr("data-url"); } } } -
成员页面的个人信息:学号、姓名
Document document = Jsoup.parse(file, "UTF-8"); Elements es = document.getElementsByAttributeValue("class", "full-name"); Elements es2 = document.getElementsByAttributeValue("class", "members-list-data").first().getElementsByAttributeValue("class", "student-no"); for (int i = 0; i < es.size() - 3; i++) { //学生姓名 String name = es.get(i + 1).text().toString(); //学生学号 int number = new Scanner(es2.get(i).text()).nextInt(); } -
某一个课堂完成页面的信息:姓名、对应的经验值
//使用jsoup查找分值并统计 Document document = Jsoup.parse(file, "UTF-8"); Elements es = document.getElementsByAttributeValue("class", "homework-item"); for (int i = 0; i < es.size(); i++) { if (!es.get(i).toString().contains("未提交")) { //学生姓名 String name = es.get(i).select("span").get(0).text().toString(); //多一个判断,是否是"尚无评分"的特殊情况 if (es.get(i).getElementsByAttributeValue("class", "appraised-box cl").select("span").get(3).toString().contains("尚无评分")) {continue;} //学生经验值 int score = new Scanner(es.get(i).getElementsByAttributeValue("class", "appraised-box cl").select("span").get(3).text()).nextInt(); } else continue; }
- 中期:在eclipse上对前面三个目标数据分别实现查模块化查找功能,数据源采用静态html文件,同时远程推送至仓库
- 后期:学习完基础的爬虫知识后决定将项目转移至在IJ上(引入HttpClient的依赖非常方便),整合模块代码,查缺补漏,完成目标。
-
过程中遇到的一些问题:
-
如何“爬取”网页信息?
使用Java的HTTP协议客户端 HttpClient,即可实现抓取网页数据。
-
什么是Cookie?它在哪?我能用它做什么?
每次访问需授权的网址时,带上 Cookie 作为通行证,即可代替输入账号密码;使用Cookie可实现模拟登陆的功能,获得目标网页的源码。
-
评分情况多变问题
普通情况1:此时有两个评分,“助教/学生评分” 和 “最终得分”

普通情况2:此时没有评分,显示未提交
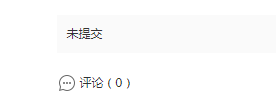
特殊情况1:此时仅有一个评分,““最终得分”

特殊情况2:此时两个评分都没有经验值

使用jsoup筛选时要多加留意,避免筛选逻辑出错 -
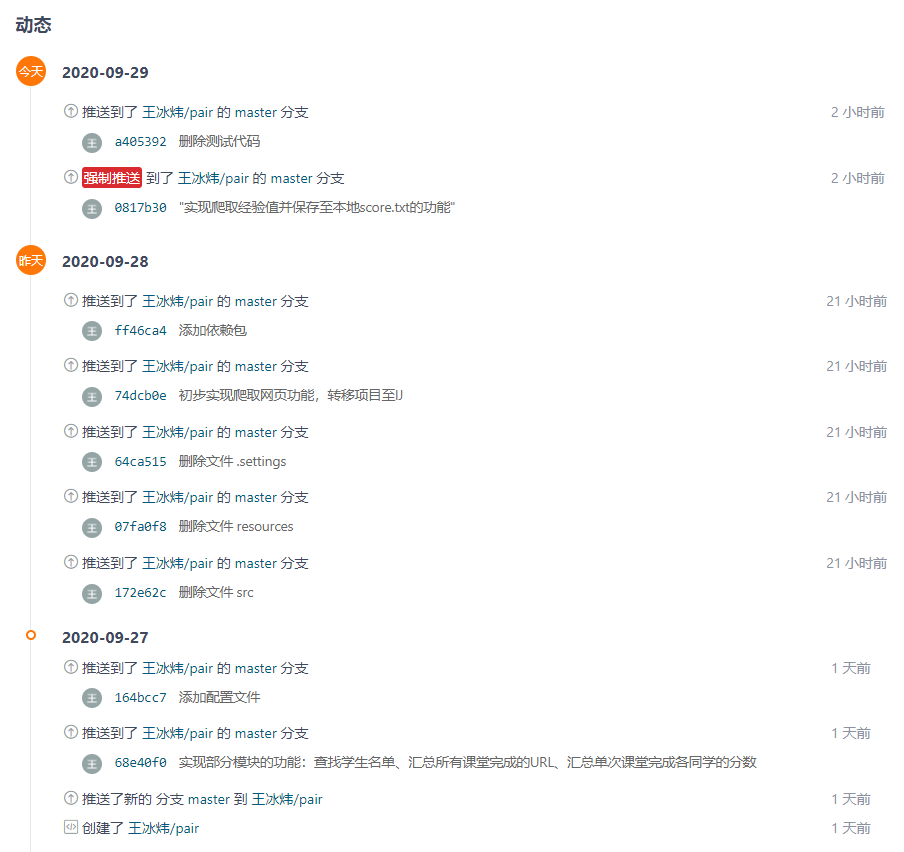
5.最终结果与git记录
参考资料:
java下载html页面---把网页内容保存成本地html:
https://blog.csdn.net/zzq900503/article/details/44035901/
Java通过httpclient获取cookie模拟登录:
https://www.cnblogs.com/zeze/p/4953414.html
HttpClient详细使用示例:
https://blog.csdn.net/justry_deng/article/details/81042379
Maven存储库:
本文作者:给时光以生命,给岁月以文明
本文链接:https://www.cnblogs.com/211806342wbw/p/13747783.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步