黄婉佳---第一次个人编程作业
一、作业介绍
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | 数据采集,数据处理,数据分析 |
| 作业源代码 | https://github.com/Vongwinga/first-personal-work |
| 学号 | 211806216 |
| 二、时间分布 | |
| 步骤 | 具体做法 |
| ---------- | ----------------- |
| 需求分析 | 审题及相关参考资料的阅读 |
| 数据采集 | 用python采集腾讯视频里电视剧《在一起》的全部评论信息 |
| 数据分析与处理 | 采集的信息转为json格式,利用jieba分词处理 |
| 词云图展示 | 用WordCloud生成词云图,利用阿里云天池平台 |
| 代码上传 | 上传到github |
| 三、具体过程 | |
| 审题花了比较久的时间,确认了所需的实现方法。 | |
| 1.数据采集 |
利用上学期爬虫的基础,条件发射的想利用Jupyter Notebook来完成,由于运行作业的电脑上未安装相关插件,只能另寻出路,使用Pycharm来完成。
在编码前先是查询了爬取视频评论的相关资料,从优秀的人手上学习方法。了解后在Xpath和正则中选择了相对熟悉的正则,之后在PyCharm中进行所需库的导入。
跟上学期爬虫类似,在谷歌开发者工具的帮助下找到想要获取的内容,发现源代码格式。

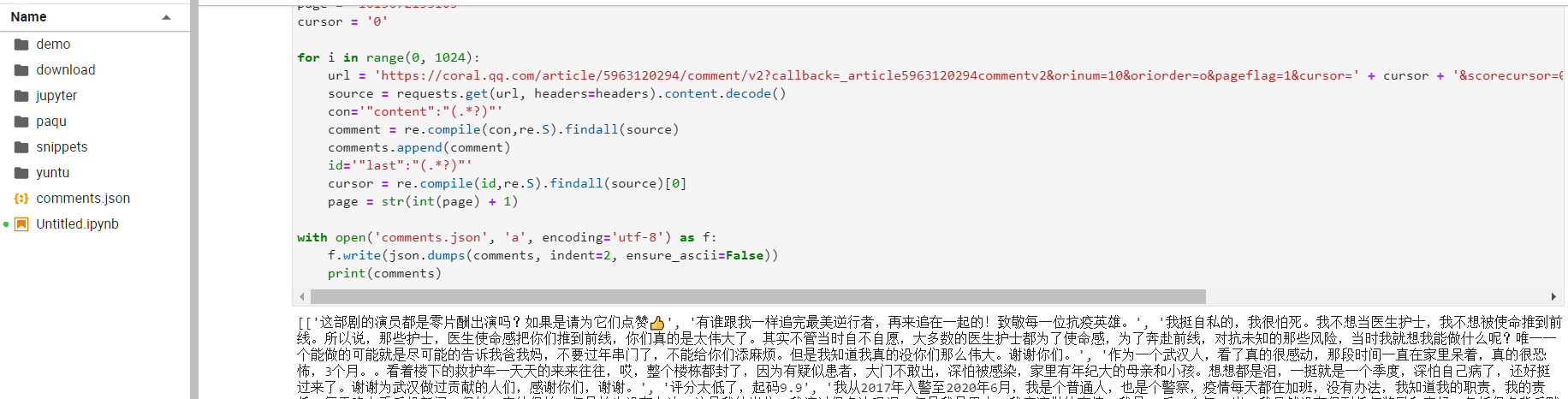
(截图是在阿里云天池平台 因为后期PyCharm操作不好报错n次!)
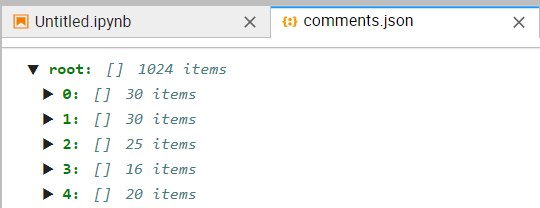
2.数据分析与处理
但是上学期爬虫习惯性保存为txt与csv的格式,这时候保存txt后需要转为json(题目所要求的格式),后来用天池做云图时都更正过来了,就删去该部分无用功代码!
期间试过直接将保存为comments.txt的代码改成 comments.json 但是报错了,后来就开始搜索资料找方法,最后发现犯了个最低级的错误没有import json
整理了一下就成功得到了json文件了,然后是开始觉得最难的,未曾接触过的jieba。(这时候记得第一步要导库了)但是代码仍然没有思路,只能去继续看看资料和询问同学能不能参考着写出一些。

3.词云图展示
导库又失败了!!PyCharm的使用实在是太坎坷了,不知道是不是和我的电脑八字不合,导了十几次一直出错,非常抓狂。被迫中断了几个小时后,想着先看看后面能做些什么,然后发现了意外之喜。
之前以为词云图是完全没有接触过的,会很难弄做不出来,但是突然脱离题目再回来看的时候,发现和上学期人工智能最后的可视化非常相像!!随之想到的就是上学期沈老师提供的阿里云天池平台,也许可以通过天池进行可视化的操作。
然后我就发现了更优秀的东西...阿里云的师兄师姐们早就有了很多词云图的模板代码甚至是应用(包含过滤器)。参考比较完整的代码却大部分依旧看不懂,最后选了个最简单的模板进行嵌套,终于成功了(泪目)。

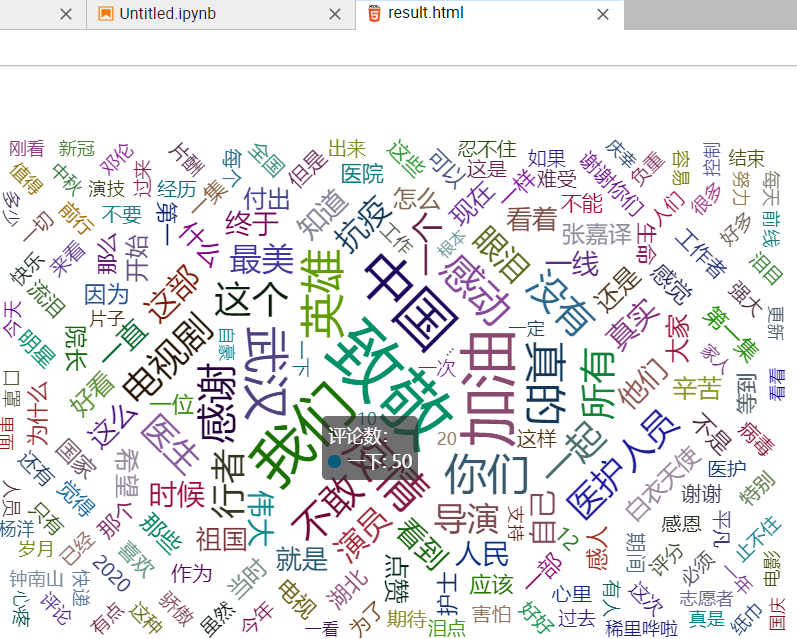
4.代码上传
没做到最后一步前我甚至怀疑这份作业我会十分悲伤我做不出来,做到最后一步却万万没想到我是倒在了这里。
首先,我的github打不开了!排版全是错乱的,于是我又打开了百度从各种论坛上面找解决办法。。。在 http://ipaddress.com/ 上查询IP再照着其他网友方法修改完本地的hosts文件仍然打不开,不死心的我又换了台电脑才能堪堪以龟速打开GitHub,时隔四个小时的泪目。
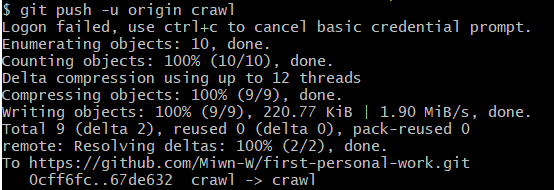
然后,参照部分同学的做法,进行了初始化与新仓库连接,切换分支以及推送操作,中途经常遇到中断和github卡住。。。(询问了其他同学好像github网页有点崩溃)
1.点击 Git Bash Here。2.git init,进行初始化。3.git remote add origin 然后连接仓库。
4.git checkout -b crawl,切换分支。 5.git add 文件名,将文件添加到暂存区。
6.git commit -m "注释",提交到版本库。7.git push -u origin crawl,推送到远程仓库。
8.git checkout main,切换分支
(部分步骤截图)