吴晋杰---第一次个人编程作业
作业介绍
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | 爬取腾讯视频《在一起》评论,并进行分词及统计,最后以词云图的形式展现在HTML,并上传到Github |
| 作业源代码 | https://github.com/Wujinejie/first-personal-work |
| 学号 | 211806186 |
| 时间安排 | |
| 步骤 | 花费时间 |
| ---------- | -------------------------------------- |
| 爬取评论数据 | 3h |
| 使用jieba分词进行分词并统计数量 | 2h |
| 将处理完的数据在hbuilder上制成词云图 | 4h |
| 上传到远程仓库Github | 3h |
具体步骤
1.数据采集
首先进入链接之后再进入全部评论信息F12打开开发者模式,通过比对网页的url, 只有last_id是不同的
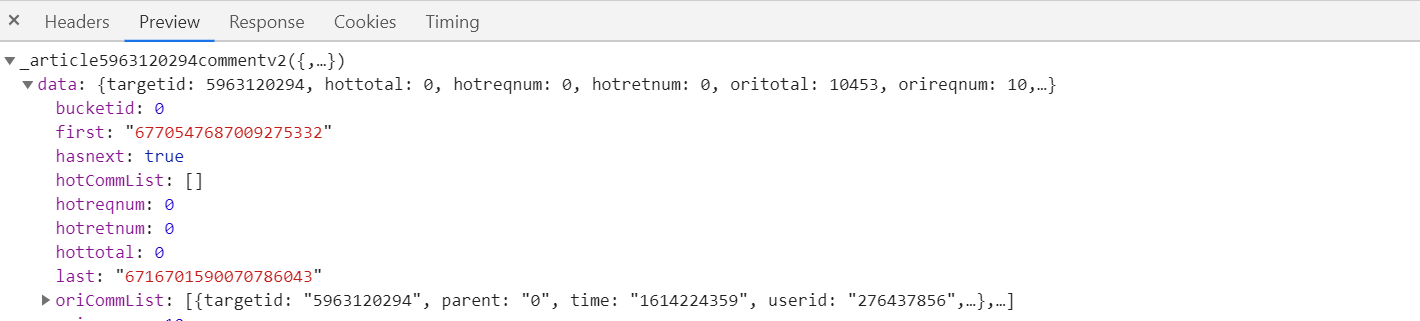
找到网页代码的规律后,开始编写代码
这里使用的是正则匹配
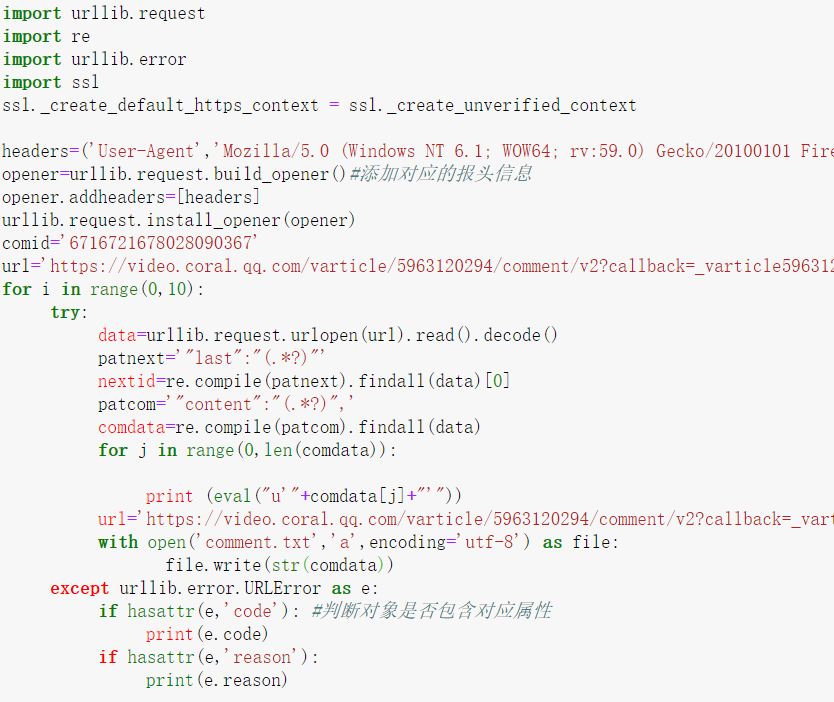
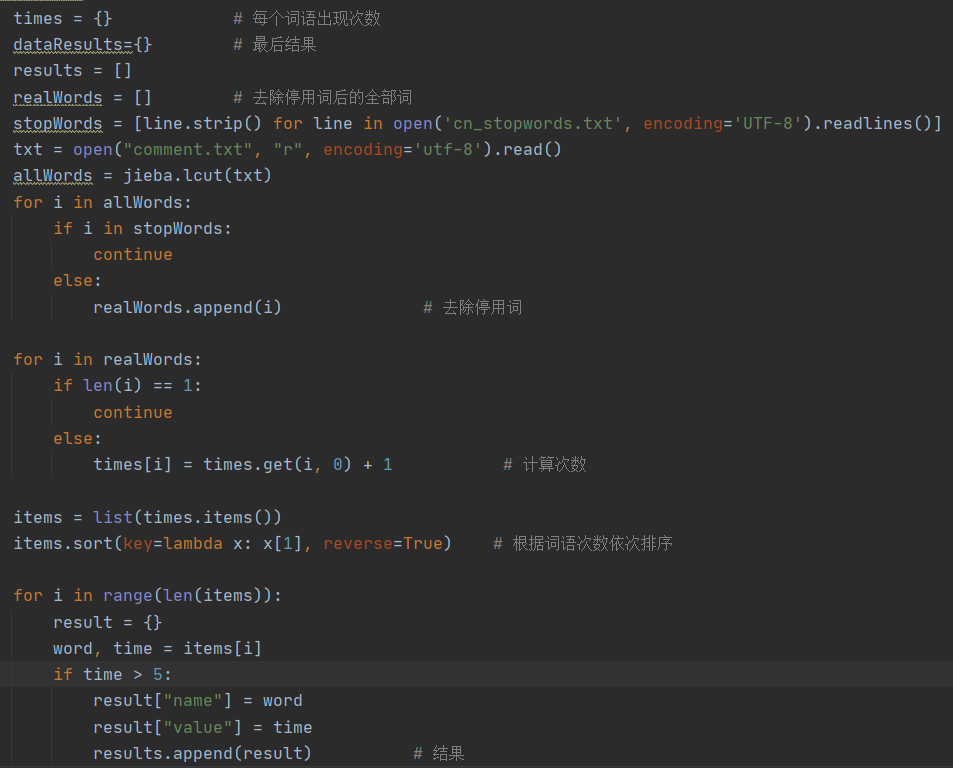
2.数据处理
导入jieba分词库进行分词处理,一开始处理时,无法下手只能请教了同学,到这里里面找到国内常用停用词表,并且去除停用词,最后按每个词的次数依次排列。
3.数据分析展示
自己在之前自学过一点前端,大部分时间花在了对echarts.js的了解上。了解之后,查找了相关代码模板,套入完成!

4.遇到的问题
(1)一开始因为爬虫知识的忘记,导致了花了大量时间在爬虫的语法上面了。
(2)在进行分词处理不知道要处理成什么样的数据。
(3)最后就是echarts的插件使用上面的问题了。

