陈为靖---第一次个人编程作业
课程实况
| 博客班级 | 2018级计算机和综合实验班 |
|---|---|
| 作业要求 | 第一次个人编程作业 |
| 作业目标 | 爬取腾讯视频《在一起》评论、利用分词器对评论做词频统计、通过echarts绘制词云图 |
| 作业源代码 | GitHub源码地址 |
| 学号 | 211806158 |
时间安排
| 过程 | 预计时间 | 实际时间 |
|---|---|---|
| 分析网页爬取规律 | 0.5h | 0.5h |
| 编写评论爬取代码 | 1.5h | 2.5h |
| 爬取评论数据 | 5h | 10h |
| 将评论进行词频处理 | 2h | 3h |
| 绘制词云图 | 2h | 3h |
| 上传相关材料到github | 1h | 3h |
爬虫实现过程
一、分析网页URL结构
打开腾讯视频《在一起》网页查看网页,每次点击“查看更多评论”可在原网页基础上出现更多的评论,可以很明显的发现网页数据属于异步加载
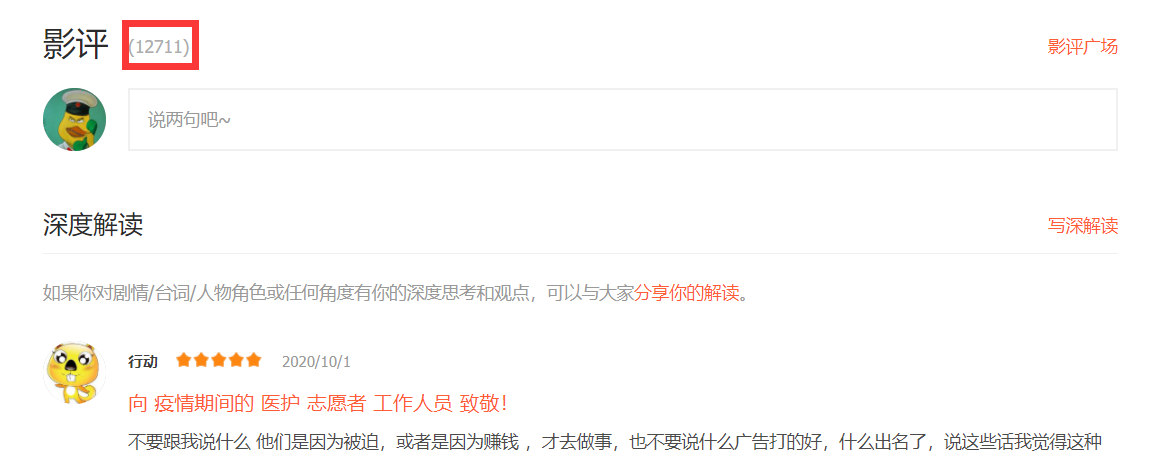
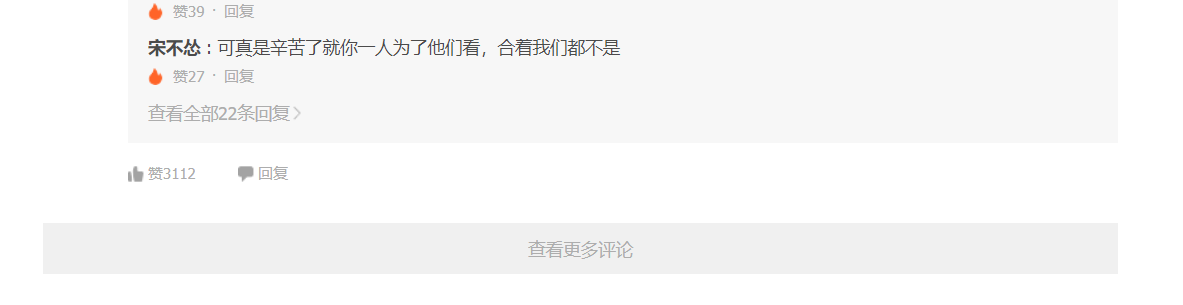
点击影评旁的红框标出的评论数,可以进入评论的网页
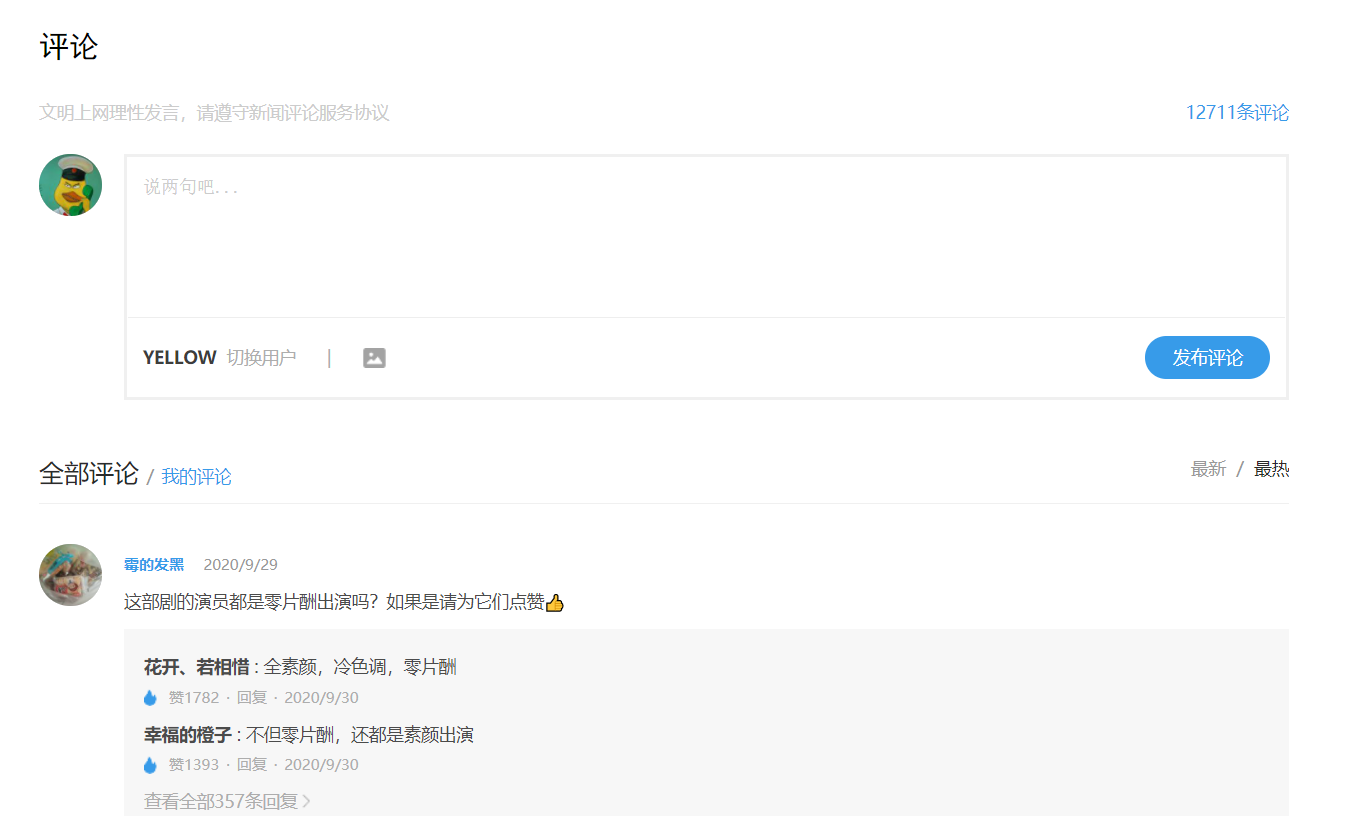
通过F12进入开发者模式,重新刷新网页,会发现当前评论存放的地址

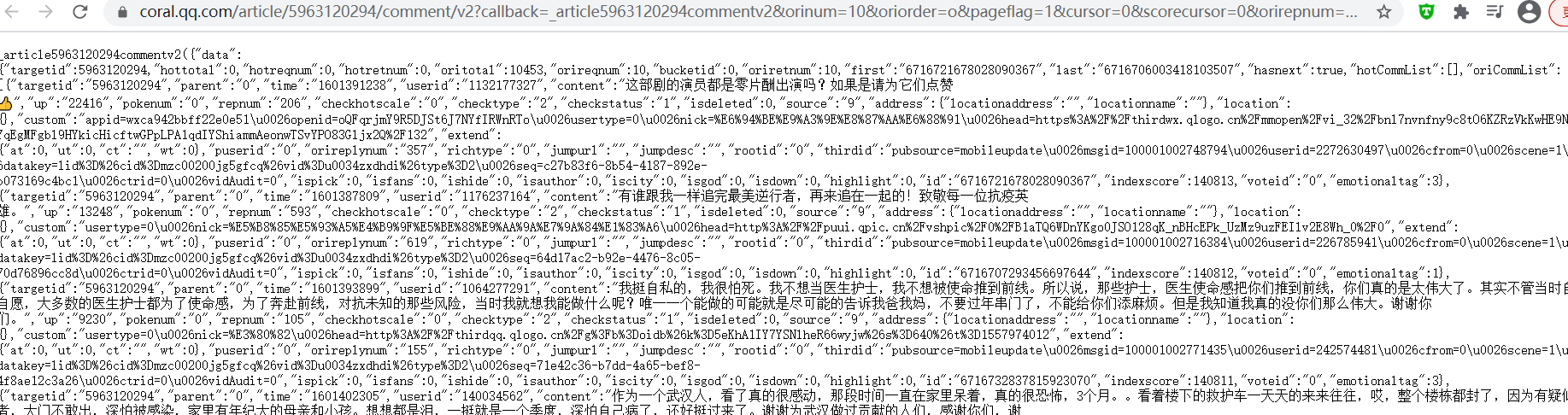
在评论网页点击“查看更多评论”,会发现每多点击一次,会多生成一个以v2?callback=_article 命名的文件,其中Request URL是新显示评论的源网址

对比两个不同的Request URL 会发现:

- 两个article后面红框的数字:确定《在一起》每集评论的地址
- 黄框cursor后的数字确定单集评论中部分评论(一般为10条评论)的地址
- 值得注意的是,每集最初的评论网页中cursor的值为0(cursor=0)
- 蓝框部分在构造爬取地址时可以直接舍去,对爬取过程没有影响
单个评论网页可以构造为:
url = 'https://coral.qq.com/article/'+id+'/comment/v2?callback=_article'+id\
+'commentv2&orinum=10&oriorder=o&pageflag=1&cursor=' +cursor
在单个网页中可以发现:
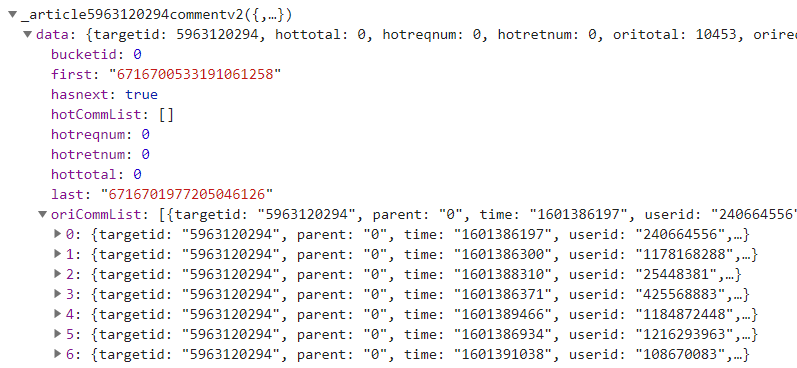

- last: 数字对应网址URL中cursor中的数字
- oricommitList:存放评论内容(基本为10条)
在构造20集不同的地址时,出于偷懒直接将控制20集地址不同的数值直接保存下来,用作循环
ID = ['5963120294','5963137527','5963276398','5963339045','5963339045','5974620716','5979269414',
'5979342237','5979747069','5979699081','5980549863','5980559005','5990521528','5984189515',
'5984155079','5984165842','5995355954','5995862740','5991853633','5991863028'] #《在一起》20集集评论不同的地址
for id in ID: # 循环得到20集全部评论
url = 'https://coral.qq.com/article/'+id+'/comment/v2?callback=_article'+id\
+'commentv2&orinum=10&oriorder=o&pageflag=1&cursor=0' # 构造每一集评论的初始地址
二、在爬取数据时产生的问题和部分解决
- 部分网页没有10条评论数,所以需通过每个网页中orireqnum来确定该网页的评论数

num = json1["data"]["oriretnum"] #确定每页评论数
with open('comments.json', 'a+', encoding='utf-8') as file: # 每页评论写入json文件
for i in range(int(num)):
comments = str(json1["data"]["oriCommList"][i]["content"]).replace("(","").replace(")","")
file.write(json.dumps(comments, ensure_ascii=False)+'\n')
- 单集评论数可能出现部分遗漏,且github上传评论数据集时,好像大于1MB便不能直接查看,故上传时将评论数据集分成了3份,如需要使用,将三份数据合并后使用。
3.《在一起》评论数太多,故在深夜爬取,睡一觉起来还没爬完...所幸的是没有遭到防爬。
数据处理及生成词频
在分词处理过程中,采用了jieba分词器,详细可以查看结巴中文分词
1. 将每条评论进行关键词的提取并做词频统计
seg_list = jieba.analyse.extract_tags(jsonstr, topK=10) #关键词过滤
2. 筛选关键词,通过导入停用词表将没用的标点符号和部分中文去除,同时排除出现次数<=5的词(PS:个人觉得出现次数太少不具代表性)
for key in list(dic.keys()):
if key in stop_keyword or dic[key] <= 5:
del dic[key] #出现次数小于等于5的词没有较大的参考意义,故删除
continue
++这里我采用了中文常用停用词表中的哈工大停用词表,同时可以先跑一边程序,如果部分显出出来的词不尽人意,可以手动添加到停用词表中++
3. 将词频格式设置成echarts可用的格式。
commentlist = []
for key in dic.keys():
comment = {}
comment["name"] = key
comment["value"] = dic[key] #将单个词和出现次数组成键值对
commentlist.append(comment)
生成词云图
-
当前echarts官网中没有词云图的相关使用文档,故在官网中扩展下载中选择词云图(字符云)
-
根据词云图(字符云)提供的词云图模板
-
将我们自己的词频数据导入,就可以很快生成所需的词云图
var option = {
tooltip: {},
series: [ {
type: 'wordCloud',
gridSize: 2,
sizeRange: [12, 50],
rotationRange: [-90, 90],
shape: 'pentagon',
width: 600,
height: 400,
drawOutOfBound: true,
textStyle: {
color: function () {
return 'rgb(' + [
Math.round(Math.random() * 160),
Math.round(Math.random() * 160),
Math.round(Math.random() * 160)
].join(',') + ')';
}
},
emphasis: {
textStyle: {
shadowBlur: 10,
shadowColor: '#333'
}
},
data: [{'name': '点赞', 'value': 487}, {'name': '片酬', 'value': 94}, {'name': '出演', 'value': 111}, {'name': '这部', 'value': 681}, {'name': '演员', 'value': 566}, {'name': '追完', 'value': 52}, {'name': '抗疫', 'value': 696}, {'name': '致敬', 'value': 2421}, {'name': '最美', 'value': 657}, {'name': '再来', 'value': 35}, {'name': '英雄', 'value': 1411}, {'name': '行者', 'value': 733}, {'name': '一位', 'value': 221}, {'name': '一起', 'value': 737}, {'name': '护士', 'value': 315}, {'name': '使命感', 'value': 16}, {'name': '医生', 'value': 613}, {'name': '前线', 'value': 134}, {'name': '伟大', 'value': 805}, {'name': '不想', 'value': 87}]
} ]
};
chart.setOption(option);
window.onresize = chart.resize;
</script>
</body>
效果图

GitHub上传
在做作业的过程中,发现将代码和文档上传至GitHub也是难题之一。(还是GitHub使用的太少了)所以看了一些廖雪峰老师的教程和万能的百度
单文件上传过程如下:

git checkout chart #切换到chart分支
git add index.html #将index.html文件添加到暂存区
git commit -m "xx:xxx" #将文件交暂存区到本地仓库并填写备注信息
git push -u origin chart # 将本地版本库的分支推送到远程服务器上对应的分支
将两个分支分别合并到主分支
git merge chart #将chart分支合并到主分支
git push # 推送到对应分支
git在pull或者合并分支的时候可能会遇到这个界面
- 按键盘左上角"Esc"
- 输入:wq 按回车键即可(保存退出)
遇到的问题
- 爬取评论的过程中,没有将各个评论下的回复等一并爬取,造成了爬取信息的不完整。
- 由于遍完善代码边上传代码文件到GitHub,导致文件多时,部分文件命名可能没按要求且较为复杂,下次应认真避免。
- echarts运用不熟练,在绘制时基本按照他人模板修改。
参考资料
廖雪峰-Git教程
Commit message 和 Change log 编写指南
关于Echarts词云图自定义形状如何实现
结巴分词原理及使用
