
钟宏鸣---第一次个人编程作业
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/ |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | 爬取腾讯视频《在一起》评论,用jieba处理数据并生成词云图 |
| 作业源代码 | https://github.com/784034506b/first-personal-work |
| 学号 | 211806149 |
| 步骤 | 时长 |
|---|---|
| 分析网页 | 1h |
| 爬虫编写 | 2h |
| 数据处理 | 2h |
| 生成词云图 | 2h |
| 上传代码 | 1h |
一、 数据采集
代码行数:26
- 进入《在一起》的评论页面,发现评论页是采用异步加载。
- 在浏览器中获取到评论数据的url
- 通过比较发现只有cursor=以及最后_=后面的数字不一样。
第一页:https://video.coral.qq.com/varticle/5963120294/comment/v2?callback=_varticle5963120294commentv2&orinum=10&oriorder=o&pageflag=1&cursor=0&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1614230005291
第二页:https://video.coral.qq.com/varticle/5963120294/comment/v2?callback=_varticle5963120294commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6716701590070786043&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=132&_=1614230005294
在浏览器中查找,发现在获取到的数据中的last就是下一个url链接中的cursor数据,第一页的coursor是0 - 编写爬虫数据保存为comments.json文件
import requests
import re
import json
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.74'
}
comment = []
comments = []
source = '1614192110983'
cursor = '0' #第一页last:0
n = 12709//10
for i in range(0,n):
url = 'https://coral.qq.com/article/5963120294/comment/v2?callback=_article5963120294commentv2&orinum=10&oriorder=o&pageflag=1&cursor=' + cursor + '&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=1&_=' + str(source)
html = requests.get(url, headers=headers).content.decode()
connent='"content":"(.*?)"'
comment = re.compile(connent,re.S).findall(html)
comments.append(comment)
id='"last":"(.*?)"'
cursor = re.compile(id,re.S).findall(html)[0]
page = str(int(source) + 1)
with open('comments.json', 'a', encoding='utf-8') as f:
f.write(json.dumps(comments, indent=2, ensure_ascii=False))

二、 数据处理
代码行数:30
- 打开comments.json文件去除评论中的特殊字母字符,并使用精确模式进行分词
cut_words = ""
for line in open('./comments.json',encoding='utf-8'):
line.strip('\n')
line = re.sub("[A-Za-z0-9\“\”\,\。\:]", "", line)
seg_list=jieba.cut(line)
cut_words += (" ".join(seg_list))
words = cut_words.split()
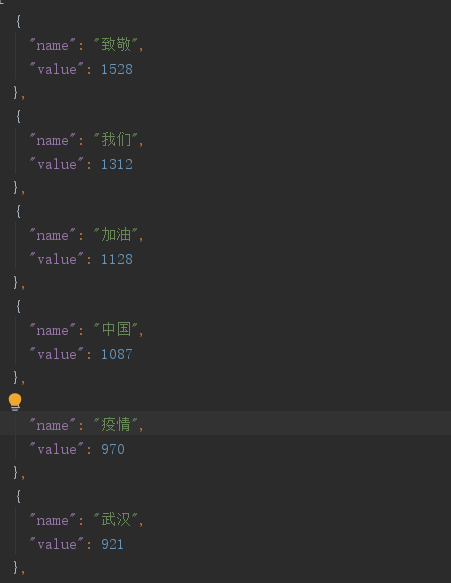
- 获取数量最多的前200个元素,最后保存到wordCount.json中
for k,v in c.most_common(200):
comment = {}
comment["name"] = k
comment["value"] = v
comments.append(comment)
三、 数据分析展示
代码行数:863
- 创建index.html文件,导入echarts.js、echarts-wordcloud.js
- 获取图片的base64编码,结合上一步的json文件,套用模板生成词云图

四、代码上传
git init初始化git remote add origin 仓库地址,本地仓库与远程仓库建立连接git clone 仓库地址,从github上克隆一个仓库git checkout -b chart,创建并切换到新分支git add 文件名,将文件添加到暂存区git commit -m "注释",把该文件提交到版本库git push -u origin chart,推送到远程仓库- 重复5-7,上传chart分支部分
- 改变参数重复4-8,上传crawl分支部分
git checkout master,切换到主分支,若没有则-b创建git merge crawl和git merge chart然后git push -u origin master,将内容合并到master分支

五、总结
- 数据采集时由于评论数量过大,只对部分评论进行了爬取,但效率依然很低下
- 没有进行过系统的前端学习,编写html时需要大量查阅资料
- 生成词云图引用json数据时,直接复制粘贴,没有用插件导入文件

