

温佳超---第一次个人编程作业
作业介绍
| 博客班级 | 2018级计算机和综合实验班 |
|---|---|
| 作业要求 | 第一次个人编程作业 |
| 作业目标 | Python爬取腾讯视频《在一起》评论,利用分词器处理数据,生成词云,将代码上传到Github |
| 作业源代码 | 第一次个人编程代码 |
| 学号 | 211806133 |
时间记录
| 步骤 | 具体做法 | 时间 |
|---|
- 进行数据采集 | 采集腾讯视频里电视剧《在一起》的全部评论信息 | 2h
2.进行数据处理 | 把所有数据下载到本地保存到json文件里面comments.json, 页面用js读取文件 | 5h
3.数据分析展示 | 将采集到的评论信息做成词云图 | Nh
4.代码上传到Github | 上传到Github | 30min
代码介绍
1.Python爬虫
前言
在某些网站 ,当我们滑下去的时候才会显示出后面的内容,就像淘宝一样,滑下去才逐渐显示其他商品,这个就是采用 Ajax 做的,然后我们现在就是要编写这样的爬虫。
主要内容
规律分析
我们需要分析加载评论的规律
1.首先使用谷歌浏览器打开腾讯视频里电视剧《在一起》的全部评论信息
2.然后再多次点击查看更多评论

3.按下F12键,可以得到多个变化的网址
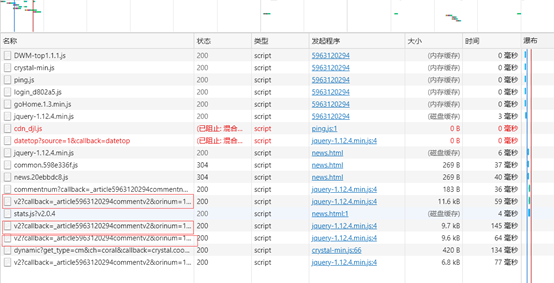
4.经过多次寻找规律,可以发下如下规律(请求URL 中只有 cursor 和 source 进行了改变,其他是不变的:cursor 其实是上一个用户data中的last所对应的数值; source 是在第一个的基础上进行加一操作)
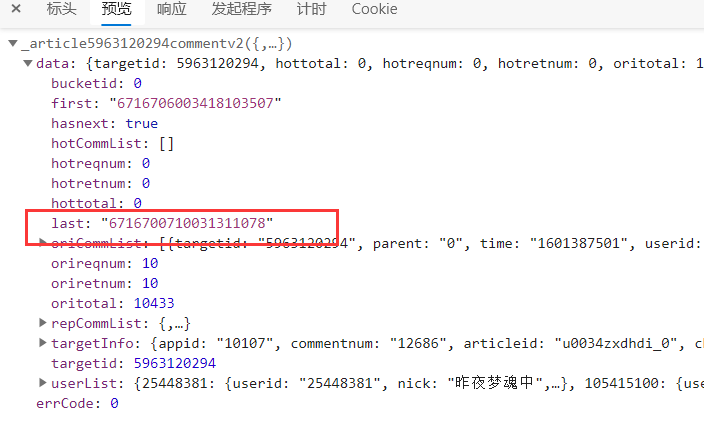


5.发现评论网址 的规律后,接下来就是评论内容
发现评论内容在 content 里面

只抓取一页的评论
知道规律后,可以试试抓取评论内容
接下来我们尝试只抓取一个链接里面的内容

自动抓取全部评论
由于上学期所学的大数据信息采集与预处理课程中,多次出现了403Forbidden的现象,知道大多数网站都会采取的反爬虫措施。
为防止此现象的出现,借助某种方式来伪装我们的IP,让服务器识别不出是由我们本机发起的请求。一种有效的方式就是使用代理。
还采取了异常处理,但还不是很全面,仍然是需要改进的。
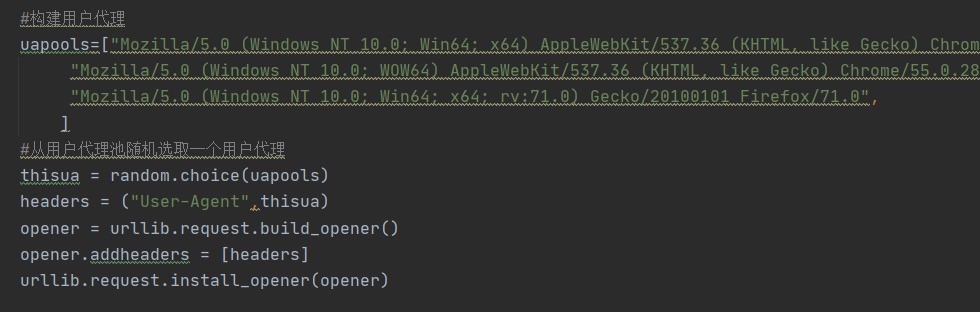
总结
在爬取数据时,由于利用循环来一页一页的采集腾讯视频里电视剧《在一起》的评论信息,所以需要知道总的评论数来大致得到总的页数,由此会出现少部分评论信息的丢失
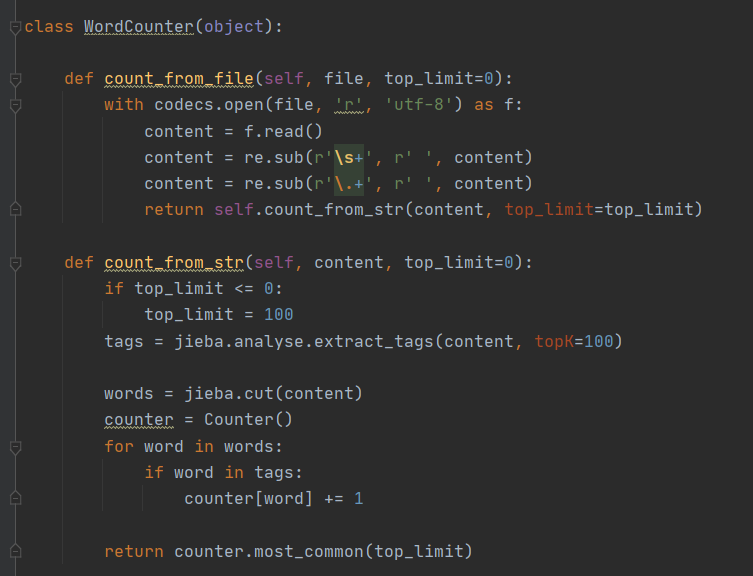
2.数据的处理
首先从一个文本文件读入文本,并作了一些简单的替换,比如替换多个空格为单空格等。
使用关键词提取功能,提取权重最高的10个关键词。
使用精确模式对文件内容分词。
根据关键词和分词结果,统计词频。
排序并返回词频最高的单词和出现次数。
3.数据分析展示
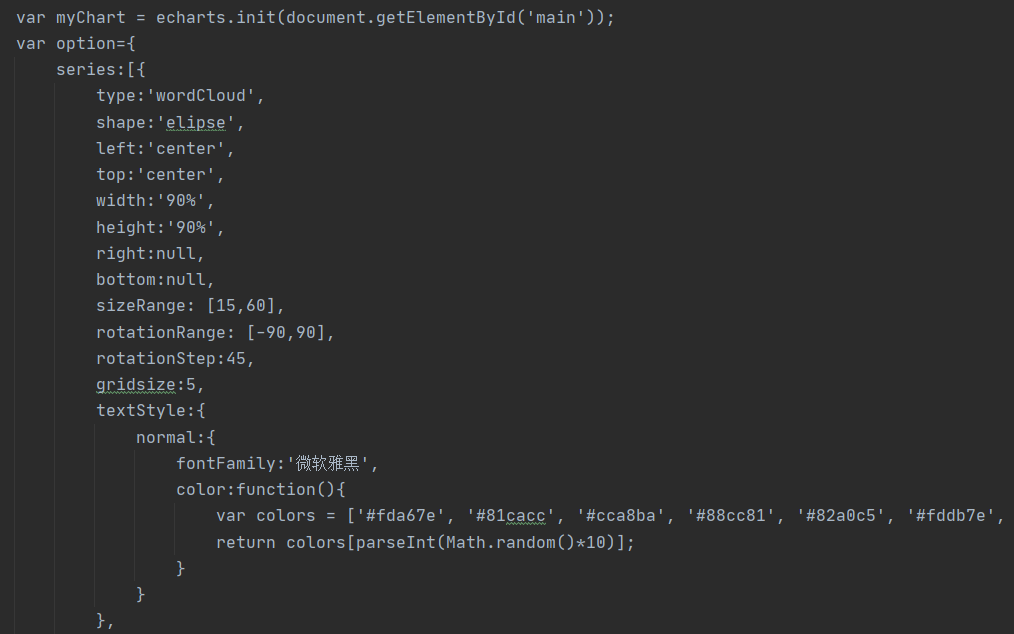
利用echarts.js制作词云

4.代码上传到Github
Git具体步骤:
(a).新建一个“第一次编程”文件夹,里面添加几个文件。右击“第一次编程”文件夹根目录,点击“Git Bash Here”,打开git命令行。
(b).在命令行中,输入“git init”,使“第一次编程”文件夹加入git管理

(c).输入“git remote add origin xxxx“ (git remote add origin 你自己的https地址),连接你的guthub仓库。

(d).将Git中的仓库内容复制到该文件夹中,这是文件夹会新建一个first-personal-work文件
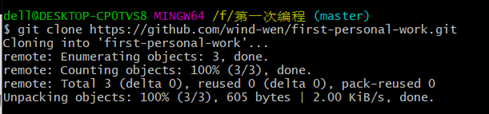
(e).进去first-personal-work文件,查看所有分支,如需更换(输入 “git checkout crawl”)

(f).输入“git add .”(不要漏了“.”),将文件夹全部内容添加到git;也可以输入“git add 上传文件的名字” ,将此文件内容添加到git

(g).输入“git commit -m "first"”(“git commit -m "提交信息"”)

(h).输入“git push -u origin master(可以更换其他分支)”,上传项目到Github。这里会要求输入Github的账号密码,按要求输入就可以。

(i).将两个分支分别合并到主分支,合并后的分支不要删除
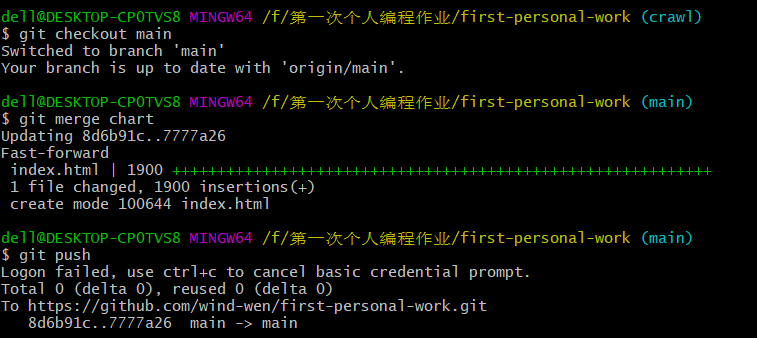
从当前分支切换到主干main上("git checkout main");合并某个分支到主干master("git merge chart");上传代码(git push)
遇到的问题
1.当爬取腾讯视频的评论太多次导致出现反爬的现象,故参考网上的方法,采取IP代理,虽然上学期有学过一点,但学艺不精。
2.第一次接触词云,通过多次在百度搜索各种相关资料来了解,但学习还是比较少,希望以后有时间可以再深入学习下。

