梁剑煌---第一次个人编程作业
| 博客班级 | https://edu.cnblogs.com/campus/fzzcxy/2018CS |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzzcxy/2018CS/homework/11732 |
| 作业目标 | <爬取腾讯视频《在一起》并且进行高频词统计和词云图展示> |
| 作业源代码 | https://github.com/liangjianhuang/first-personal-work |
| 学号 | <211806119> |
| 过程 | 花费时间 |
|---|---|
| 分析网页 | 2h |
| 编写代码 | 2h |
| 爬取评论 | 1h |
| 分词 | 2h |
| 词云图 | 2h |
| 上传代码 | 3h |
第一步:数据采集
代码行数:24
看到需要爬虫的题目就选择了爬虫的题目,毕竟上个学期也有学到一点基础,顺便对爬虫进行一下复习,因为下个学期还有要上数据挖掘这门课。
1、下拉到评论进行刷新可以看到v2?callback=_varticle这个网址点开可以看到里面的评论
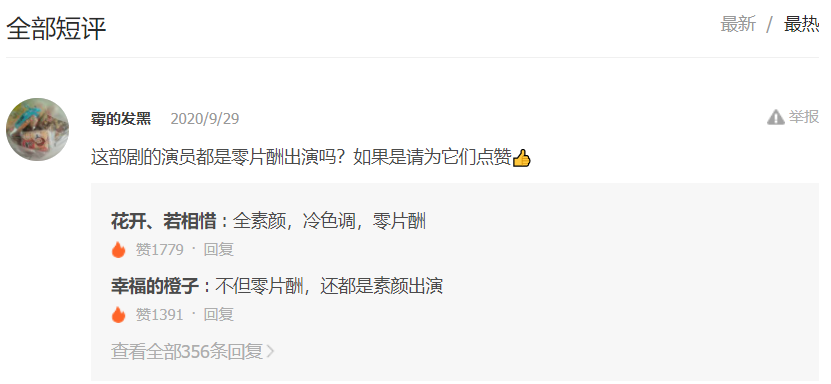

2、分析了几个小时只发现了一集里面的查看更多评论可以在上面那个网址里面找到(“last”),所以我只好一集一集爬取。
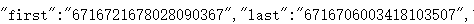
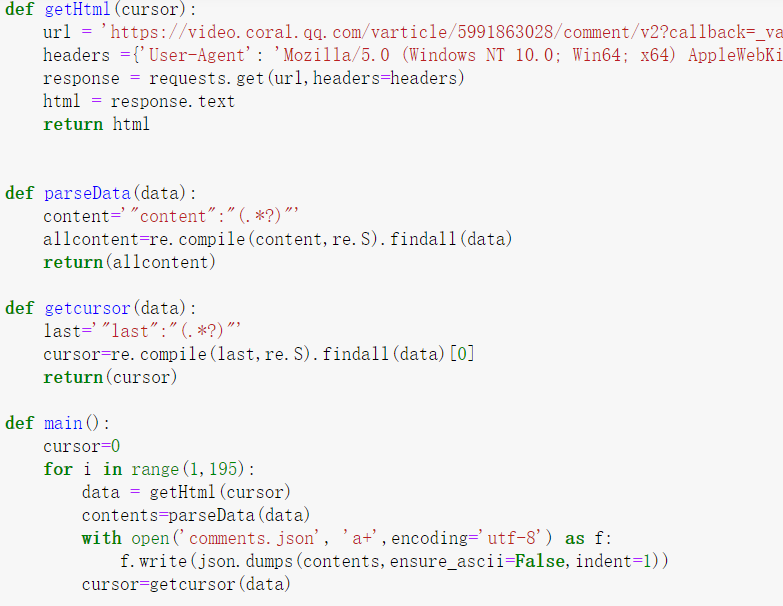
3、代码展示
第二步:数据处理
代码行数:18
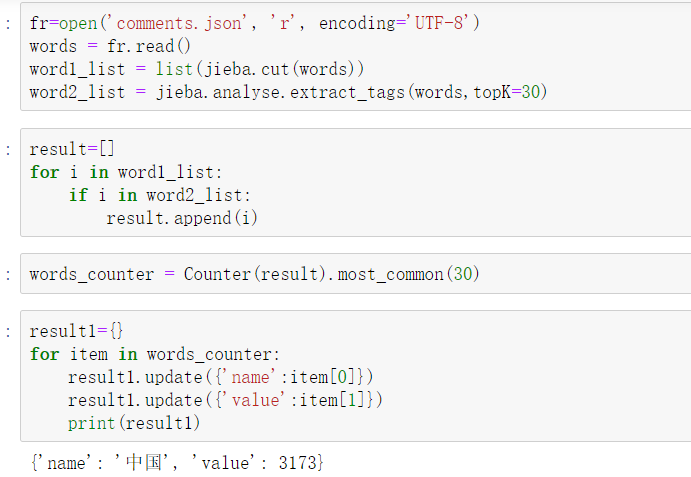
尝试了thulac分词工具包发现不知道该怎么用,只好用jieba分词,分词完了利用jieba.analyse找出高频词并且用Counter统计词数。
1、代码展示
第三步:数据展示
代码行数:92
对这个完全没有接触过的东西一点都不懂,只能一步步百度遇到的问题,最后勉强完成了要求。
1、了解Echarts,下载echarts.min.js和echarts-wordcloud.min.js

2、创建index.html并且了解如何编写,但也只能是模仿别人怎么写。

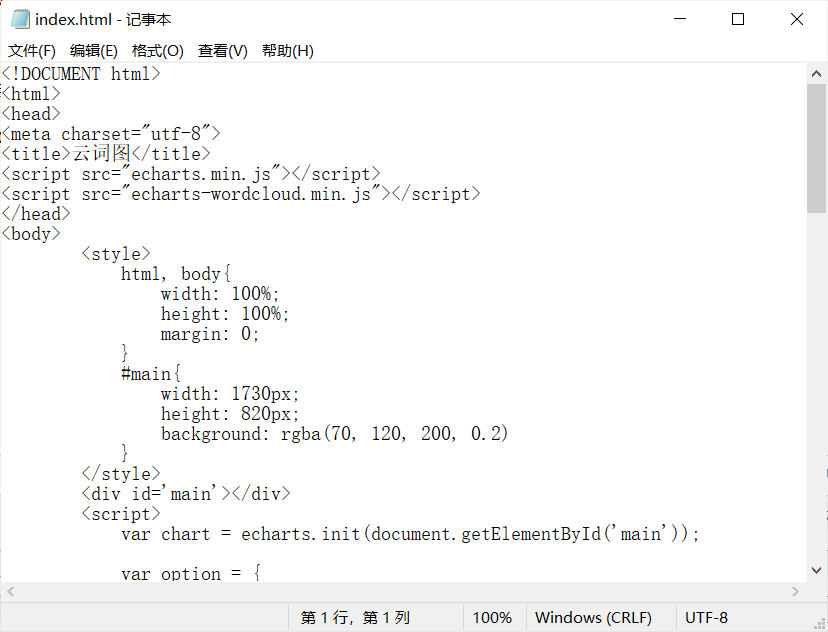
3、词云图

第四步:上传代码到github
代码行数:n
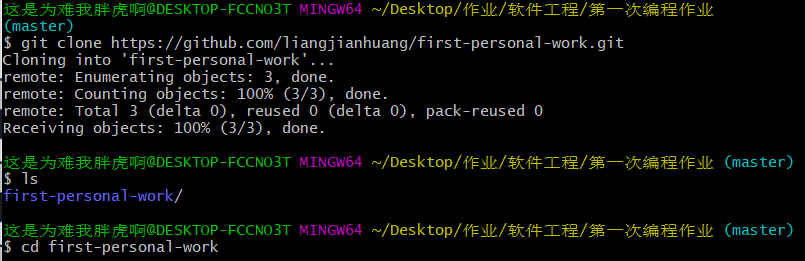
1、先创建一个仓库

2、利用克隆获取仓库
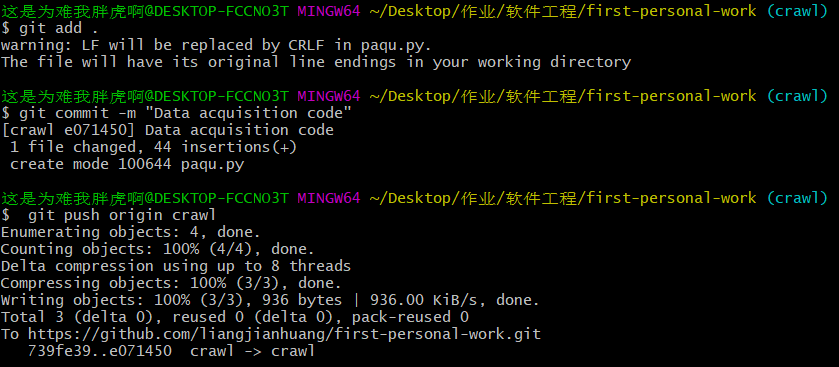
3、创建本地分支添加本地commit并且上传代码
4、合并分支并且保留分支

总结
这次的作业接触到了没有接触过的东西,还是了解到了一些有趣的知识,希望开学后能更加全面的学习这些知识。
