
陈伟超---第一次个人编程作业
| 博客班级 | <2018级计算机和综合实验班> |
|---|---|
| 作业要求 | <第一次个人编程作业> |
| 作业目标 | <采集腾讯视频里电视剧《在一起》的全部评论信息,使用jieba进行分词,最后在index.html中使用eacharts制作词云图> |
| 作业源代码 | <GitHub地址> |
| 学号 | <211806107> |
大概过程
| 实现过程 | 花费时间 |
|---|---|
| 获取数据 | 1h |
| jieba分词 | 1h |
| 制作词云图 | 2h |
| 上传文件 | 1h |
一、获取数据
这里附上评论信息网址:《在一起》评论
这里用的是python爬虫,一个较快的爬取方法就是获取json数据页面,本来打算用selenium模拟点击“加载更多”爬取的,但是发现太慢,直接放弃。
正常流程:
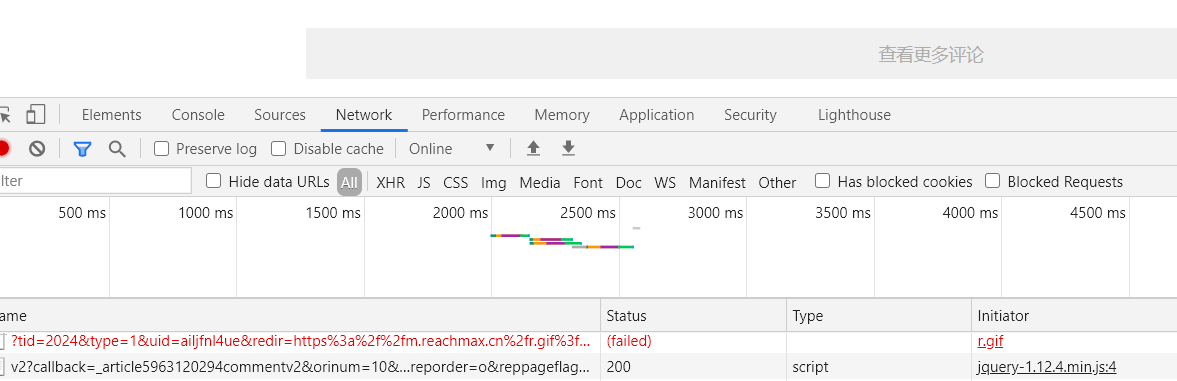
(1)打开开发者工具,刷新页面后选择“Network”栏,在下方一栏选择“ALL”,找到含有json数据的内容,如下图的“v2?”开头的一栏。

(2)分析网址规律,这里举两个例子:
https://coral.qq.com/article/5963120294/comment/v2?
callback=article5963120294commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6716701590070786043&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=1&=1613895952942
https://coral.qq.com/article/5963120294/comment/v2?callback=article5963120294commentv2&orinum=10&oriorder=o&pageflag=1&cursor=6716700710031311078&scorecursor=0&orirepnum=2&reporder=o&reppageflag=1&source=1&=1613895952943
仔细观察,差别在于“cursor”和“_”的值,后一个很明显是简单的累加,而cursor这里也是请教了爬虫老师,要去数据页面内找,很容易发现,last就是下一个json网址的cursor。
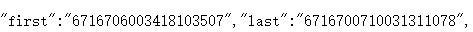
这里提醒一下,谷歌浏览器不会显示第一页的网址(害得我去百度了半天又问了半天,结果在360安全浏览器里看到了),第一页cursor为0,而且后来发现“_”的值我取任意数都可以,很怪。
(3)正则提取保存,没什么好说的。
二、数据处理(jieba分词)
下载jieba(pip install jieba,这里我加了豆瓣的源),使用时import jieba即可,首先得知道需要什么样的数据,老规矩,上网查,自学一部分,发现大部分的echarts代码的data部分基本都是{"name":,"value":}形式的json格式数据,所以分词成类似格式的数据,保存成json文件(词云图要用)。
附上完整下载命令:pip install jieba -i https://pypi.doubanio.com/simple/
三、eacharts制作词云图
这里我用了两种方式制作词云图:python和echarts
(1)python:下载wordcloud(pip install wordcloud),学习网上的词云教程,较容易。(由于作业是指定echarts制作,所以python方式我只使用了少量数据)


(2)echarts:html文件没学过,对JavaScript也不熟,查了半天没看懂,毫无基础的我真的学起来很吃力,只能借鉴了网上的模板进行修改,像上面说的把保存的json数据代进去,完成。

四、上传文件至github
看了其他文章,发现很多人都用VScode连接github,去下载学习了一下,确实是挺方便的,但是作业还是用代码形式提交吧,因为只操作过一次所以这次基本又重新学了一遍。。但是效率高多了。
(1)仓库新建分支
(2)仓库克隆到本地

(3)切换到chart分支进行数据展示代码的提交
同样方法提交全部文件,最后push
(4)切换到crawl分支进行数据采集和处理代码的提交
同样方法提交全部文件,最后push

(5)切换到main合并分支
如果commit注释错的话,可以git commit --amend进到vi编辑器里修改注释就可以(记住是还没push的情况下!push完就只能删了重新提交)
总结
全都是新东西,学起来挺吃力,但是收获也不小。。自学真的累人,求求老师下次讲讲再布置作业,还有寒假别再布置作业了。

