数据清洗
数据清洗概念
- 数据清洗
- 实战案例
- 新增列
数据清洗
数据分析流程
需求分析——获取数据——数据清洗——探索数据——建模分析——撰写分析报告+数据可视化
什么是数据清洗
从记录表、表格、数据库中检测、纠正或删除损坏或不准确记录的过程
专业名词
脏数据:没有经过处含有一定问题的数据,如:缺失、异常、重复...
干净数据:经过处理完全符合规范要求的数据
数据清理使用方法
1.读取外部数据
read_csv:读取txt和csv文件,read_excel:读取excel文件, read_sql:读取数据库,read_html:读取网页
2.数据概览
index 行索引值,columns 列索引,head 前头5个数据,tail 尾部5个数据,shape 表格行数和列数,describe 显示快速统计数据,info 查看数据整体信息,dtypes 看数据类型
3.简单处理
移除首尾空格 大小写转换...
4.重复值处理
duplicated()查看是否含有重复数据
drop_duplicates()删除重复数据
5.缺失值处理
删除缺失值、填充缺失值
6.异常值处理
删除异常值、修正异常值(当作缺失值处理)
7.字符串处理
切割、筛选...
8.时间格式处理
将时间字符串转换为时间格式 Y m d H M S
补充用代码监测数据库存在重复值
查看数据库
select * from blog;
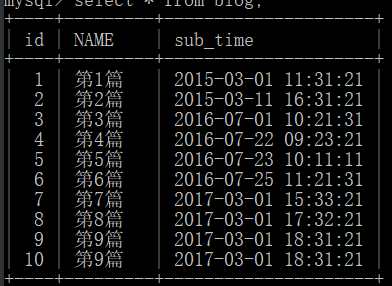
获取数据量
select count('NAME') from blog;
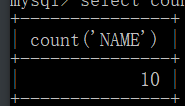
获取不重复的数据
select count(distinct(NAME)) from blog;

得出结论有重复数据
实战案例
获取数据
# 调用模块 import numpy as np import pandas as pd import matplotlib.pyplot as plt # 获取数据 df = pd.read_csv(r'qunar_freetrip.csv')
数据概览
# 1.查看前五条数据 掌握大概 print(df.head()) # 2.查看表的行列总数 print(df.shape) # 3.查看所有的列字段 print(df.columns) # 4.查看数据整体信息 print(df.info()) # 5.快速统计 print(df.describe())



列字段处理
查看数列时发现一段无用列
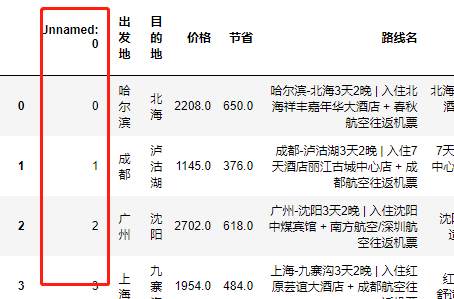
删除无用列字段
df.drop(['Unnamed: 0'],axis=1,inplace=True)
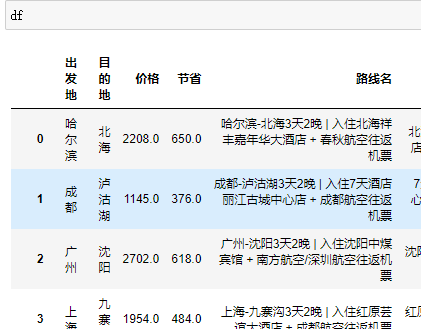
发现列字段有空格,这导致格式不统一

方法1:
for循环依次取出,列字段首位的空格
# 申明变量 css=[] # 循环获取 for col in df.columns: # 去除空格 css.append(col.strip()) # 修改数据 df.columns=css df.columns
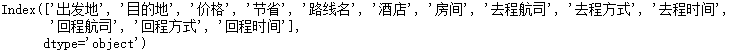
方法2:
改进代码用列表生成式
df.columns=[col.strip() for col in df.columns]
重复值处理
查询重复值
df.duplicated()
发现存在重复值
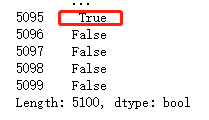
查看具体信息
df[df.duplicated()]

针对重复的数据一般情况下都是直接删除的
df.drop_duplicates(inplace=True)
df[df.duplicated()].count()

行索引会不会因为数据的删除而自动重置(删除完数据之后行索引是不会自动重置的)
修改行索引
df.index=range(0,df.shape[0])
df
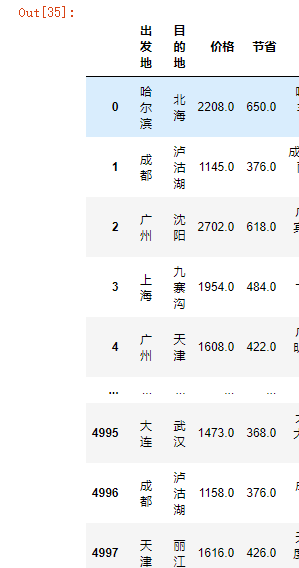
异常值处理
利用快速统计大致筛选出可能有异常数据的字段
df.describe()
发现价格小于节省 那么可能是价格有问题或者节省有问题
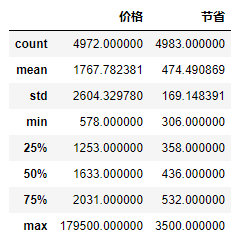
利用公式可以获取异常的数据
df[abs((df['价格'] - df['价格'].mean()) / df['价格'].std())>3]

推荐下列方法(简单)
df[df['节省'] > df['价格']]
删除异常数据
方式1:
拼接索引值,再删除
# 造变量 res=[] # 纵向合并数据 res=pd.concat([df[df['节省']>df['价格']],sd]) del_index=res.index # 删除数据 df.drop(index=del_index,inplace=True)
方式2:
得出一个结果就删一个(不推荐)
1.占比过小可以直接删除 2.利用均值、统一值直接填充 3.根据不同的情况采用不同的计算公式填充 常用的四个方法 isnull 判断 notnull 判断 fillna 填充 dropna 删除 保留几位小数 round(数据,保留几位)
方法1:删除
删除’价格‘为空的数据
# 获取价格空的索引值 wroin=df[df['价格'].isnull()].index # 删除 df.drop(index=wroin,inplace=True)
删除’节省‘为空的数据
# 获取节省空的索引值 wroless=df[df['节省'].isnull()].index # 删除 df.drop(index=wroless,inplace=True)
重置行索引值
df.index = range(0,df.shape[0])
方法2:
直接利用价格的均值填充缺失数据
价格缺失处理
# 求平均值 df['价格'].mean() # 1732.5140901771338 # 四舍五入数据 round(df['价格'].mean(),1) # 填充数据 df['价格'].fillna(round(df['价格'].mean(),1),inplace=True)
节省缺失处理
同理针对节省的数据也做中位数填充(其实应该结合实际采用不同的方法) df['节省'].fillna(round(df['节省'].mean(),1),inplace=True)
验证
df.isnull().sum()

重置行索引值
df.index = range(0,df.shape[0])
出发地缺失数据值处理
# 查早有缺失的数据 df.isnull().sum()

发现有数据缺失
# 利用布尔值索引筛选出出发地有缺失的数据 df[df.出发地.isnull()]
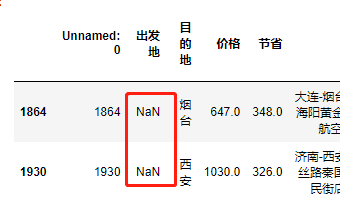
# 获取缺失位置的路线数据 df.loc[df.出发地.isnull(),'路线名'].values

方法1:
使用正则
# 调用模块 import re # 利用正则重路线中获取出发地址 df.loc[df.出发地.isnull(),'出发地']=[re.findall('(.*?)-',i) for i in df.loc[df.出发地.isnull(),'路线名'].values]
方法2:
使用字符切割
df.loc[df.出发地.isnull(),'出发地'] = [i.split('-')[0] for i in df.loc[df.出发地.isnull(),'路线名'].values]
针对缺失值的处理
''' 1.操作数据的列字段需要使用loc方法 2.采用数学公式依据其他数据填充 3.缺失值可能在其他单元格中含有 4.如果缺失值数量展示很小可删除 '''
获取目的地缺失的路线数据
df.loc[df.目的地.isnull(),'路线名'].values
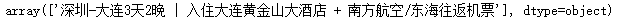
使用正则
# 调用模块 import re # 利用正则重路线中获取出发地址 df.loc[df.目的地.isnull(),'目的地']=[re.findall('-(.*?)\d',i) for i in df.loc[df.目的地.isnull(),'路线名'].values]
新增列
新增酒店类型
思路:
1.从酒店信息中获取数据 2.使用正则方法 3.创建新列赋值赋值
代码:
# 变量 restaur=[] # 循环获取 for info in df['酒店'].values: # 如果缺失数据 if not re.findall(' (.*?) ',info): # 设置默认值 restaur.append(['经济型']) # 进行下一次循环 continue # 正则方法数据 restaur.append(re.findall(' (.*?型)',info)) # 赋值 df['酒店类型']=np.array(restaur) df
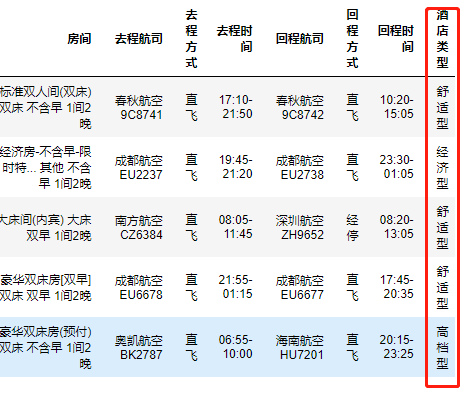
新增酒店评分
思路:同上
代码:
# 变量 restaura=[] # 循环获取 for info in df['酒店'].values: # 正则方法数据 restaura.append(re.findall('(\d.\d)分',info)) # 赋值 df['酒店评分']=np.array(restaura)
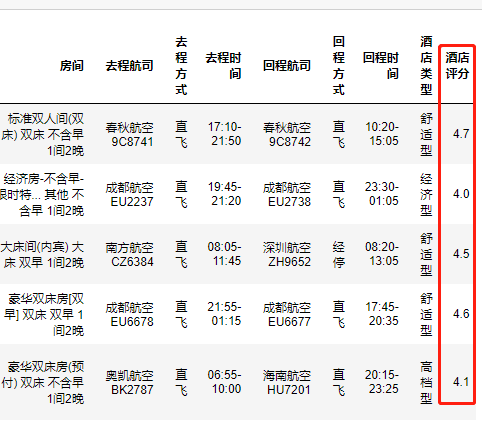
监测数据是否存在空的
df['酒店评分'].isnull().sum()
输出:0
新增游玩时间
思路:同上
代码:
# 变量 restaura=[] # 循环获取 for info in df['路线名'].values: # # 如果缺失数据 # if not re.findall(' (.*?)分 ',info): # # 设置默认值 # restaura.append(['经济型']) # 进行下一次循环 # continue # 正则方法数据 restaura.append(re.findall('(\d.\d晚)',info)) # 赋值 df['游玩时间']=np.array(restaura) df

监测数据是否存在空的
df['游玩时间'].isnull().sum()
输出为:0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号