数据分析numpy科学计算模块
数据分析numpy科学计算模块
- 科普
- nump前戏
- 多维数组
- 数据类型
- 常用属性
- 运算符
- 函数、均值计算、总和与聚合函数
- 随机数
- reshape()
科普
''' 很多编程语言对数字精确度不是很敏感 python亦是如此 ''' eg: a=524552524.532523 b=str(a) print(b) # 输出可能为 524552524.5
python如何可以做到人工智能、量化分析等高精度的工作
# 程序内部是通过相应的模块实现的
numpy简介
- Numpy是高性能科学计算机和数据分析模块的基础包
- 也是pandas等其他数据分析工具的基础
- NumPy具有多维数组功能,运算更加高效快速
下载模块
在notebook中如果需要执行pip命令下载模块
!pip3 install numpy
anaconda软件也提供一个下载模块的工具:
conda使用方法与pip一致
conda install numpy
导入模块
import numpy # 更加倾向于起别名 np import numpy as np
numpy前戏
数据准备
# 调用模块 import random # 伪造数据
# h为身高 h=[]
# w为体重 w=[] # 循环构造 for i in range(10000000): # 取153到180内的数字 h.append(random.randint(153,180)) # 取51到88内数字 w.append(random.uniform(51,88))
方法1:
使用纯python代码实现BMI指数计算:
BMI指数:身体质量指数=体重(KG)/身高(m)的平方
# 调用模块 import time # for循环计算 # 开始时间 start_time = time.time() # 循环计算 for i in range(10000000): w[i]/(h[i]/100) ** 2 # 结束时间 end_time = time.time() - start_time end_time
获取运行时间
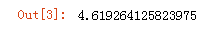
方法2:
使用numpy模块解决方案
# 调用模块,并别名为np import numpy as np # 获取身高 H = np.array(h) # 获取体重 W = np.array(w) # 数组运算 start_time = time.time() # 获取BMI BMI = W/(H/100)**2 # 计算结束时间 end_time = time.time() - start_time end_time
获取运行时间
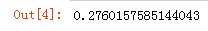
结论
numpy模块使数据计算更高效
多维数组
# numpy中同一个数组内所有数据数据类型肯定是一致的

# numpy中进行数据操作的时候同一个数组内所有的数据都挨个对应参与操作
# 数组长度一致,不一样则无法运算

一维数组
np.array([1,2,3,4,.....])
二维数组
np.array([[1,2,3,4,.....],[9,8,7,6,.....]])
数据类型
布尔型
bool_
整型
int_、int8、int16、int32、int64
int32只能表示(-2**31,2**31-1),因为它只有32个位,只能表示2**32个数
无符号整型
uint8、uint16、uint32、uint64
浮点型
float_,float16,float32,float64
复数型
complex_,complex64,complex128
numpy数据类型以数字居多的原因
因为numpy主要用于科学计算 只有数字可以参与计算
为什么有些数据类型后面加下划线
因为为了跟python数据类型关键字区分开
eg:
li1 = [ [1,2,3], [4,5,6] ] a = np.array(li1) a.T

就相当于是将行变成列,列变成行,它也是一个比较常用的方法
查看数组元素的数据类型
dtype
li1 = [ [1,2,3], [4,5,6] ] a = np.array(li1) a.dtype
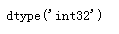
查看数组元素的个数
size
a.size

查看数组的维数
ndim
a.ndim

查看数组的维度大小(以元组形式,输出为几行几列)
shape
a.shape
结果为2行3列

常用方法
如何查看某个方法的使用说明
方式1:在方法后面跟问号执行即可
方式2:写完方法名后先按shift不松开然后按tab即可(shift+tab)
array()
将列表转换为数组,可选择显示指定dtype
li1 = [ [1,2,3], [4,5,6] ] a = np.array(li1) a

arange()
range的numpy版,支持浮点数
a=np.arange(1,10,2) b=np.arange(1.2,10,0.4) print(a) print(b)

linspace()
a=np.linspace(1,10,20) print(a)

''' 这个方法与arange有一些区别,arange是顾头不顾尾
这个方法顾头顾尾,在1到10之间生成的二十个数每个数字之间的距离相等的,前后两个数做减法肯定相等 '''
zeros()
根据指定形状和dtype创建全0数组
a=np.zeros((3,4))
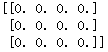
ones()
根据指定形状和dtype创建全1数组
a=np.ones((3,4))

empty()
根据指定形状和dtype创建空数组(随机值)
a=np.empty(3)
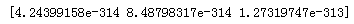
eye()
根据指定边长和dtype创建单位矩阵
a=np.eye(3)

索引切片
针对一维数组 索引与切片操作跟python中的列表完全一致
花式索引(间断索引)
依照索引值
# 生成数组
a=np.array([1,2,3,414,6,7,8,9]) # 花式索引
b=a[[0,2,5]] print(b)
![]()
布尔值索引(逻辑索引)
f=a[a>3] print(f)
![]()
针对二维数组索引与切片
语法:
res[行索引(切片),列索引(切片)]
获取二维数组的所有行或列元素,那么,对应的行索引或列索引需要用英文的冒号表示
a=np.array([[ 1, 3, 5, 7], [ 2, 4, 6, 8], [ 11, 13, 15, 17], [ 12, 14, 16, 18], [100, 101, 102, 103]]) print(a[3,3])

print(a[3,:])
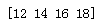
print(a[:,1])
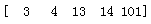
print(a[2:4,1:3])

+:数组对应元素的加和
a=np.array([ 1, 3, 5, 7],) b=np.array([4,6,5,8],) a+b
![]()
-:数组对应元素的差
*:数组对应元素的乘积
/:数组对应元素的商
//:数组对应元素商的余数
**:数组对应元素的幂指数
比较运算符
>:等价np.greater(a,b)
判断arr1的元素是否大于arr2的元素
a=np.array([ 1, 90, 5, 700]) b=np.array([4,7,5,8]) print(a>b) print(np.greater(a,b))

>=:等价np.greater_equal(,b)
判断a的元素是否大于等于b的元素
<:等价np.less(a,b)
判断a的元素是否小于arr2的元素
<=:等价np.less_equal(a,b)
判断a的元素是否小于等于b的元素
==:等价np.equal(arr1,arr2)
判断a的元素是否等于b的元素
!=:等价np.not_equal(arr1,arr2)
判断a的元素是否不等于b的元素
函数
常用数学函数
np.round(arr):
对各元素四舍五入
import numpy as np a=np.array([1.2345,1.6434,7.05]) b=np.round([a]) print(b)
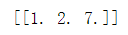
np.sqrt(arr):
计算各元素的算术平方根
np.square(arr):
计算各元素的平方值
np.exp(arr):
计算以e为底的个元素为指数
np.power(arr, α):
计算各元素的指数
a=np.array([4,9]) b=np.power(a,3) print(b)
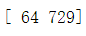
np.log2(arr):
计算以2为底各元素的对数
a=np.array([4,9]) b=np.log2(a) print(b)
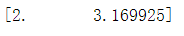
np.log10(arr):
计算以10为底各元素的对数
np.log(arr):
计算以e为底各元素的对数
常用的统计函数(必会)
''' 当axis=0时,计算数组各列的统计值 当axis=1时,计算数组各行的统计值
'''
np.min(arr,axis)
按照轴的方向计算最小值
np.max(arr,axis)
按照轴的方向计算最大值
np.mean(arr,axis)
按照轴的方向计算平均值
np.median(arr,axis )
按照轴的方向计算中位数
np.sum(arr,axis)
按照轴的方向计算和
np.std(arr,axis)
按照轴的方向计算标准差
np.var(arr,axis)
按照轴的方向计算方差
数据准备
a=np.array([[ 80.5, 60., 40.1, 20., 90.7], [ 10.5, 30., 50.4, 70.3, 90.], [ 35.2, 35., 39.8, 39., 31.], [91.2, 83.4, 85.6, 67.8, 99.]])
计算第一行的值
b=np.sum(a[0,:]) print(b)
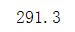
计算每一行的值
b=[] for i in range(4): b.append(np.sum(a[i,:])) print(b)

计算第二列的平均值
b=np.sum(a[:,1]) print(b)
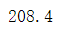
使用axis函数
求各行的和
b=a.sum(axis=1) print(b) c=np.sum(a,axis=1) print(c)

求个列的平均值
b=a.mean(axis=0) print(b) c=np.mean(a,axis=0) print(c)
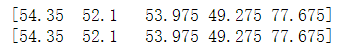
随机数
numpy中的random子模块
以np.random为前缀
rand
给定形状产生随机数组(0到1之间的数)
语法:
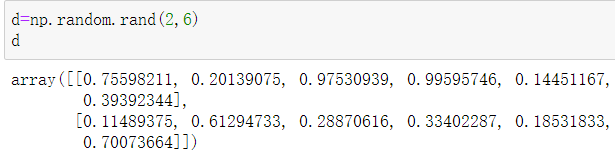
# 生成X行Y列数据组 变量=np.random.rand(X,Y)
生成2行六列的0到1之间的随机数
randint
给定形状产生随机整数
choice
给定形状产生随机选择
表示从[0,5)之间随机以等概率选取3个数
d=np.random.choice(5,3)
d
![]()
表示分别以p=[0.1, 0, 0.3, 0.6, 0]的概率从[0,1,2,3,4]这四个数中选取3个数
b=np.random.choice(5, 3, p=[0.1, 0, 0.3, 0.6, 0])
b

shuffle
与random.shuffle相同
f=np.arange(5) print(f) np.random.shuffle(f) print(f)

uniform
给定形状产生随机数组(随机均匀分布)
1到4输出六个数
b=np.random.uniform(1,4,6) print(b)
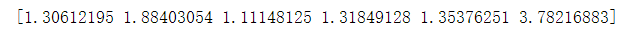
normal
随机正态分布
numpy.random.normal(loc=0,scale=1e-2,size=shape) ,意义如下:
- 参数loc(float):正态分布的均值,对应着这个分布的中心。loc=0说明这一个以Y轴为对称轴的正态分布,
- 参数scale(float):正态分布的标准差,对应分布的宽度,scale越大,正态分布的曲线越矮胖,scale越小,曲线越高瘦。
- 参数size(int 或者整数元组):输出的值赋在shape里,默认为None
reshape
reshape()函数用于改变数组对象的形状:
import numpy as np
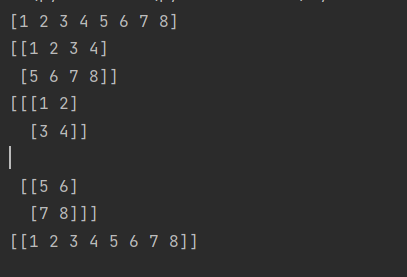
a = np.array([1,2,3,4,5,6,7,8])
print(a)
#转换成2D数组
b = a.reshape((2,4))
print(b)
#转换成3D数组
c = a.reshape((2,2,2))
print(c)
d=a.reshape((1,-1))
print(d)
结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号