Xpath模块使用和实战猪八戒
Xpath模块使用和实战猪八戒
- 豆瓣数据改进爬取
- xpath的模块使用
- xpath的了解知识
- 实战猪八戒
豆瓣数据改进爬取
思路
1.查看数据加载方式 2.查看网络network中的获取信息,得到url、请求头、防爬链 3.查看多页查询的方式,结合网址和请求获取信息观察 4.向网址请求信息,获取数据 5.通过bs4模块或者正则方法查找数据
执行
本次实验只获取一个数据、以防被封IP
# 调用函数 import time import requests from openpyxl import Workbook from bs4 import BeautifulSoup import re # 创建对象 wb=Workbook() # 创建工作簿 wb1=wb.create_sheet('豆瓣250') # 创建表单 wb1.append(['名称','导演','评分','评分人数','座右铭']) #获取页数指令 page_num=int(input('要几页:')) # 循环获取每页信息 for i in range(page_num): # 进行赋值 page_id=i*25 # print(page_id) # 发送请求 res=requests.get('https://movie.douban.com/top250?start=%s'%page_id, # 加入user—agent和防爬链 headers={"referer":"https://movie.douban.com/top250?start=0", "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36" }) # 构造计息对象 soup=BeautifulSoup(res.text,'lxml') # 查找信息位置 film_list=soup.select('ol.grid_view div.item') # 循环获取每个电影的信息 for film_info in film_list: # 获取电影名 filmname=film_info.img.attrs.get('alt') # 获取职工成员 filmmake=film_info.find(name='div',attrs={'class':'bd'}).find(name='p') # print(filmmake.text) # 获取导演名,有空格的 makername=re.findall('导演: (.*?) ',filmmake.text) # 获取评分 film_code=film_info.find(name='span',class_='rating_num').text # 获取评分人数位置 code_num=film_info.select('div.star span') # 获取评分人数 code_nonum=code_num[3].text # 获取座右铭 try: film_word=film_info.select("p.quote span")[0].text # 如果操作错误,赋值为0 except Exception as f: film_word=None #申明首行 rows=1 # 写入数据 if rows<=len(film_list): # 某行第一列 wb1.cell(column=1,row=rows,value=filmname) # 某行第二列 wb1.cell(column=2,row=rows,value=str(makername)) # 某行第三列 wb1.cell(column=3,row=rows,value=film_code) # 某行第四列 wb1.cell(column=4,row=rows,value=code_nonum) # 某行第五列 wb1.cell(column=5,row=rows,value=film_word) # 行数加一 rows+=1 # wb1.append([filmname,str(makername),film_code,code_nonum,film_word]) # 在此是实验一次 break # 停顿一秒 time.sleep(1) # 保存文件 wb.save(r'电影.xlsx')

xpath模块使用
实验准备
该代码用于下列实验操作
doc = ''' <html> <head> <base href='http://example.com/' /> <title id='t1'>Example website</title> </head> <body> <div id='images'> <a href='image1.html' a="xxx">Name: My image 1 <br /><img src='image1_thumb.jpg' /></a> <a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a> <a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a> <a href='image4.html' class='li'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a> <a href='image5.html' class='li li-item' name='items'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a> <a href='image6.html' name='items'><span><h5>test</h5></span>Name: My image 6 <br /><img src='image6_thumb.jpg' /></a> </div> </body> </html> '''
xpath的特点
效率高,使用广
调用模块
导入xpath所在模块
from lxml import etree
生成对象
将待匹配的文本传入etree生成一个对象
语法:
html = etree.HTML(变量名)
eg:
html = etree.HTML(doc)
获取标签
1.所有标签
eg:
a = html.xpath('//*') print(a)

2.指定节点(结果为列表)
语法:
a = html.xpath('//标签名')
eg:
a = html.xpath('//a') print(a)
3.子节点,子孙节点
eg:
匹配div标签内部所有的儿子a标签
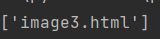
a = html.xpath('//div/a')
![]()
匹配body标签内部所有的儿子a标签
a = html.xpath('//body/a')
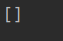
匹配body标签内容所有的后代a标签
a = html.xpath('//body//a')
![]()
4.父节点
获取body内部所有href=image1.html的后代a
a = html.xpath('//body//a[@href="image1.html"]') print(a)

..表示查找上一级父标签,获取body内部所有href=image1.html的后代a的父标签
a = html.xpath('//body//a[@href="image1.html"]/..') print(a)

获取所有id="t1"的title的父标签
a = html.xpath('//title[@id="t1"]/..') print(a)

匹配body标签内容所有的后代a标签的第一个
''' xpath返回列表值从1开始取值 ''' a = html.xpath('//body//a[1]')
print(a)

也可以这样(了解)
匹配body标签内容所有的后代a标签的第一个的父亲标签
a = html.xpath('//body//a[1]/parent::*')
print(a)

5.文本获取
获取body内部所有href=image1.html的后代a的文本内容
a = html.xpath('//body//a[@href="image1.html"]/text()') print(a)

获取body内部所有后代a内部文本(一次性获取不需要循环)
a = html.xpath('//body//a/text()')

6 属性获取
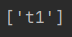
获取title标签id属性值
a = html.xpath('//title/@id')
注意从1 开始取(不是从0),获取body中儿子a标签的href属性值
a = html.xpath('//body//a/@href')

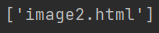
注意从1 开始取(不是从0),获取body中儿子a标签的第二个的href属性值
a = html.xpath('//body//a[2]/@href')
7 属性多值匹配
a = html.xpath('//body//a[@class="li"]') print(a)

有些a标签有多个class类,直接匹配就不可以了,需要用contains
a = html.xpath('//body//a[contains(@class,"li")]') print(a)

8 多属性匹配
查找body标签内部所有class含有li或者name=items的a标签
a = html.xpath('//body//a[contains(@class,"li")or@name="items"]')

查找body标签内部所有class含有li并且name=items的a标签的内部文本
a = html.xpath('//body//a[contains(@class,"li")and @name="items"]')

9 按序选择
爬取a标签中的最后一个的href的属性值
a = html.xpath('//a[last()]/@href')

position
position()关键字,用于定位
爬取a标签中位置小于3的href问题
a=html.xpath('//a[position()<3]/@href')

倒数第三个
a=html.xpath('//a[last()-2]/@href')

xpath的了解知识
ancestor:祖先节点
获取a标签的所有祖先结点
# 使用了* 获取所有祖先节点
a=html.xpath('//a/ancestor::*')

获取祖先节点中的div
a=html.xpath('//a/ancestor::div')

attribute:属性值
查找a标签内部第一个的属性值
a=html.xpath('//a[1]/attribute::*')

child:直接子节点
查找a标签内部第一个的儿子节点
a=html.xpath('//a[1]/child::*')

descendant:所有子孙节点
查找div标签内部所有的子孙节点
a=html.xpath('//div[@id='images']/descendant::*')

following:当前节点之后所有节点
获取a标签的第一个之后的节点
a=html.xpath('//a[1]/following::*')

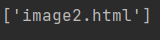
获取a标签的第一个之后的节点中第一个的href属性内容
a=html.xpath('//a[1]/following::*[1]/@href')
following-sibling:当前节点之后同级节点
获取a标签的第一个之后的同级节点
a=html.xpath('//a[1]/following-sibling::*')

获取a标签的第一个之后的同级a节点
a = html.xpath('//a[1]/following-sibling::a')
获取a标签的第一个之后的同级节点中的第二个的文本
a=html.xpath('//a[1]/following-sibling::*[2]/text()')

获取a标签的第一个之后的同级节点中的第二个的href属性值
a=html.xpath('//a[1]/following-sibling::*[2]/@href')
实战猪八戒网
思路
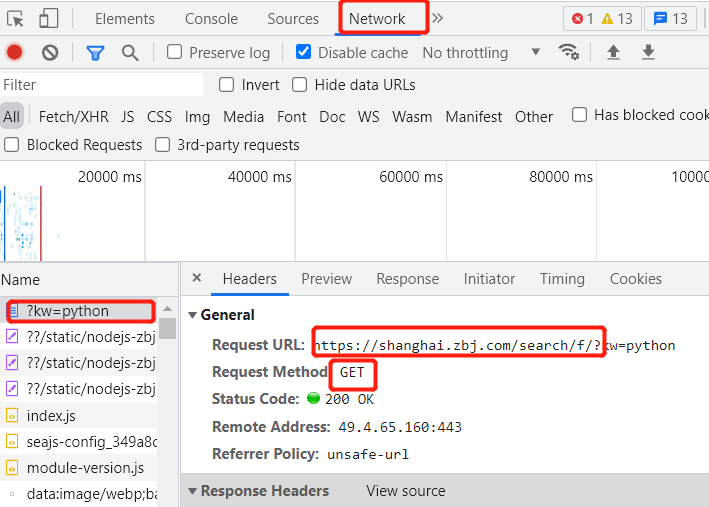
网址:https://shanghai.zbj.com/search/f/?kw=python
1.打开网址,查看数据加载方式

2.发现是直接加载,查看请求方式,可以直接向网址发送请求,获取相关请求体信息

3.获取数据后,选用喜欢的模块来获取相关数据
执行代码
# 代用模块 import requests from bs4 import BeautifulSoup from lxml import etree # 发送get请求 res=requests.get('https://shanghai.zbj.com/search/f/?', params={"kw": "python"} ) # 构造对象 zhu_html=etree.HTML(res.text) # 先查找所有的外部div标签 zhu_div=zhu_html.xpath('/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div') print(zhu_div)

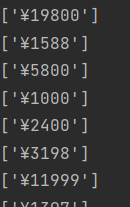
# 循环获取div for div in zhu_div: # 获取价格 zhu_price=div.xpath('.//span[@class="price"]/text()') print(zhu_price)
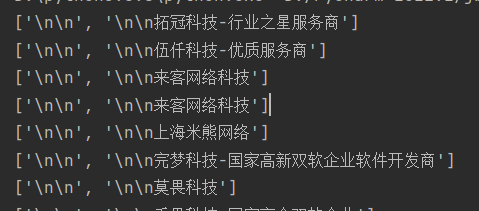
# 获取公司名 zhu_name=div.xpath('./div/div/a[1]/div[1]/p/text()') print(zhu_name)
# 获取接单数 zhu_num =div.xpath('./div/div/a[2]/div[2]/div[1]/span[2]/text()') print(zhu_num)
# 获取详细信息 zhu_info=div.xpath('.//div/a[2]/div[2]/div[2]/p/text()')

