网络爬虫实战训练
网络爬虫实训
- 爬取豆瓣网特殊情况
- 爬取链家二手房数据
- 爬取汽车之家新闻数据
爬取豆瓣网特殊情况
如果经常访问豆瓣时会遇到接种结果

这是服务器端将客户端IP封锁造成的后果
方法尝试1:
在官网注册账号后,登录界面,研究登录的地址及携带数据,代码发送请求获取cookie,
结果:
操作系数高,难以找到获取信息
方法尝试2:
使用代理池方法(不推荐)
# 调用模块 import requests # 配置地址池 proxies = { 'http': '114.99.223.131:8888', 'http': '119.7.145.201:8080', 'http': '175.155.142.28:8080' } # 发送请求 res = requests.get('https://movie.douban.com/top250', # 请求头加入user—agent headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36" }, # 获取代理池 proxies=proxies )
结果:
没有成功
方法尝试3:
等待,等到豆瓣解封本地IP
缺点:
时间长
爬取链家二手房数据
思路
1.查看数据加载方式, 2.查看网络network中的获取信息,得到url、请求头、防爬链 3.向网页发送请求,获取各详情页的信息
实操
查看加载方式,确定为直接加载
调用模块
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
规律发现
网址:https://sz.lianjia.com/ershoufang/pg2/,‘sz’为城市拼音的首字母,愿意为深圳;‘pg2’控制页码,2为当前页码地址,只通过对这两个参数的修改可以获得不同城市指定量的信息
# 创建地域字典 where_place={'上海':'sh','北京':'bj','深圳':'sz','武汉':'wh'} # 获取城市名 locale_place=input('哪个城市:') # 判断字典内是否存在 if locale_place not in where_place: print('没有该城市数据') # 城市存在 else: # 获取页数 page_num=input('要几页:') # 发送请求 res=requests.get('https://%s.lianjia.com/ershoufang/https://cs.lianjia.com/ershoufang/pg%s'%(where_place[locale_place],page_num))
需求:
名称 地址 详细信息 关注人数 发布时间 单价 总价
# 构造对象 wb = Workbook() # 构造工作簿1 wb1=wb.create_sheet('房子数据',0) # 先定义表头 wb1.append(['房屋名称','小区名称','区域名称','详细信息','关注人数','发布时间', '总价', '单价']) # 创建地域字典 where_place={'上海':'sh','北京':'bj','深圳':'sz','武汉':'wh'} # 获取城市名 locale_place=input('哪个城市:') # 判断字典内是否存在 if locale_place not in where_place: print('没有该城市数据') # 城市存在 else: # 获取页数 page_num=input('要几页:') # 发送请求 res=requests.get('https://%s.lianjia.com/ershoufang/https://cs.lianjia.com/ershoufang/pg%s'%(where_place[locale_place],page_num)) # 构造对象 soup =BeautifulSoup(res.text,'lxml') # 获取指定li标签信息 li_list=soup.select('ul.sellListContent>li') # 循环获取单个li标签 for li in li_list: # 有些li标签内部是广告不是地址信息 try: # 获取名字 title=li.select('div.title>a')[0].text # 无法获取的情况下 except Exception as f: # 继续 continue # 获取地址 address=li.select('div.positionInfo')[0].text # 进行地址分割 real_add =address.split('-') # 因为有一些地址格式不统一所以要进行不同的处理 if len(real_add) ==2: # 解压赋值 add_name,add_loc=real_add # 格式不同的情况下 else: # 链式赋值结果都相同 add_name=add_loc=real_add # 获取详细信息 house_detail=li.select('div.houseInfo')[0].text # 获取时间,但是时间的文本需要分割 people_num,publish_time = li.select('div.followInfo')[0].text.split('/') # 获取总价 all_price=li.select('div.totalPrice')[0].text # 获取单价 one_price=li.select('div.unitPrice')[0].text
信息储存方式:
excel表格存储
# 写入表格 wb1.append([title,add_name,add_loc,house_detail,people_num,all_price,one_price]) # 保存文件 wb=(r'房子数据.xlsx')
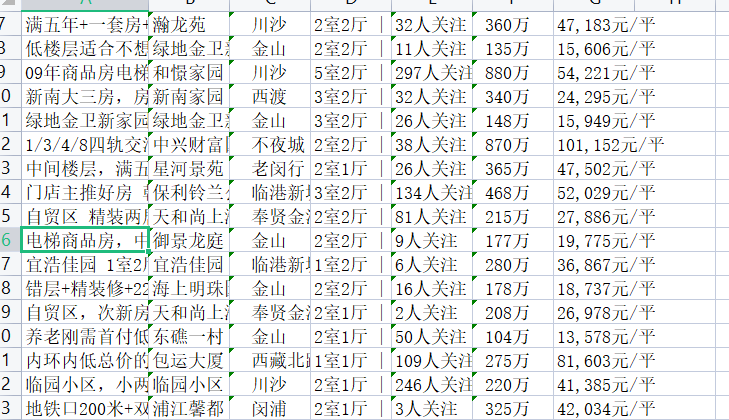
结果
爬取汽车之家新闻数据
思想
1.查看数据加载方式, 2.查看网络network中的获取信息,得到url、请求头、防爬链 3.向网页发送请求,获取各详情页的信息
实操
发现数据加载方式为直接加载

调用模块
# 调用模块 import requests from bs4 import BeautifulSoup from openpyxl import Workbook
需求分析:
新闻标题 新闻链接 新闻图标 发布时间 新闻简介
# 构造文件对象 wb=Workbook() # 构造工作簿 wb1=wb.create_sheet('汽车') # 创建表头 wb1.append(['标题','链接','图标链接','发布时间','新闻简介'])
发请求获取数据
# 发送请求,需要请求头 res = requests.get('https://www.autohome.com.cn/news/', headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36" } ) print(res.text)
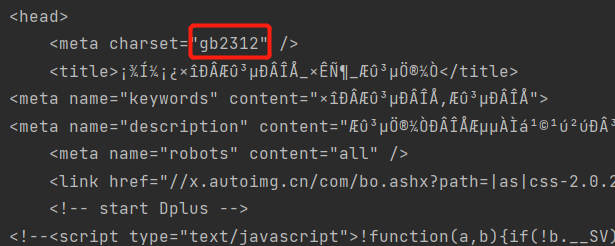
获取结果有乱码,我们查看字符编码时发现,程序使用GBK编码,所以要改变字符编码
res.encoding='gbk'
进行编码
# 字符编码 res.encoding='gbk'
获取数据
# 构造对象 soup = BeautifulSoup(res.text, 'lxml') # 查找所有的li标签 li_list=soup.select('ul.article>li') # 循环获取li标签 for li in li_list: # 获取详情链接 a_tag=li.find('a') # 判断标签是否有意义 if not a_tag: # 标签不是所要内容时,结束循环 continue # 获取新闻链接 link='https:'+a_tag.get('href') # 获取标题 news_title=li.find('h3') # 判断标签是否有意义 if not news_title: # 标签不是所要内容时,结束循环 continue # 获取标签 news_title=news_title.text # 获取图片链接 img_src=li.find('img') if not img_src: # 标签不是所要内容时,结束循环 continue # 获取图片链接 news_img=img_src.get('src') # 获取发布时间 news_title_time=li.find('span').text # 获取简介 news_detail=li.find('p').text # 获取观看次数 news_watch=li.find('em').text # 获取评论次数 news_resp=li.find('em',attrs={'data-class':'icon12 icon12-infor'}).text
保存数据
# 写入数据 wb1.append([news_title,link,news_img,news_title_time,news_detail,news_watch,news_resp]) # 保存数据 wb.save(r'汽车数据.xlsx')
执行结果

