梨视频爬取攻略
梨视频爬取攻略
思路
1.打开网址查看数据加载方式,具体步骤是打开网络源码查看视频数据是否存在 2.存在为直接加载,不存在为js动态申请,发现数据为js动态加载 3.打开network查看url地址,请求方式,视频文件多为get请求 4.获取首页所有详细页面地址后,执行循环向详细页面地址发送请求 5.进入详细页面时,查看视频加载方式 6.network查看url地址,请求方式,请求体或请求头文件 systemTime srcUrl 7.获取信息后,发现不是视频数据 8.再对请求结果的观察中发现真实地址与请求结果地址有相似的地方,但也有不同的地方 9.通过特定的值将请求结果地址替换为真实地址,利用视频ID与systemTIme进行替换,就可以发送求获得视频 10.梨视频存在防爬链,需要在请求返回值中查找referer键值对 11.将referer键值对,作为请求头加入请求 12.向视频的地址发送请求获取视频信息 13.最好设置时间间隔,不要太频繁
实际操作
调用模块
import requests ''' requests模块主要用于网络请求获取数据,请求方式主要为get和post,本次实验会用到get ''' from bs4 import BeautifulSoup ''' 从bs4集合中获取BeautifulSoup,其主要识别'html'和'lxml'的文本内容,并且有多个选择器可以筛选结果 ''' import os ''' os模块运用于操作文本格式的文件 '''
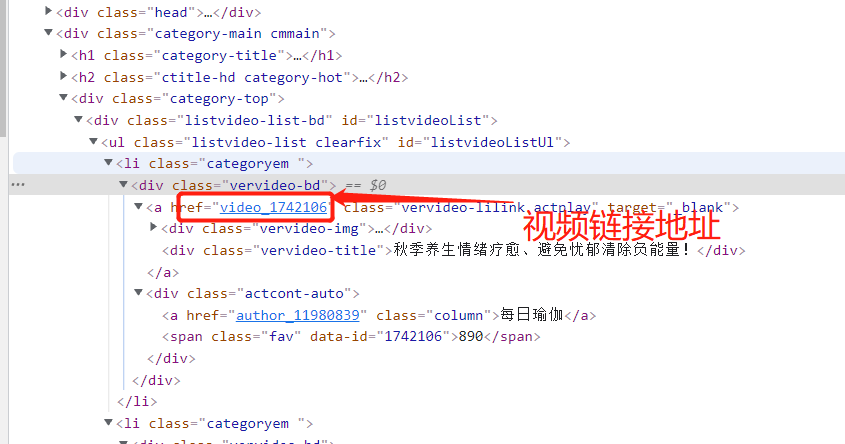
进入官网查看,查看数据请求方式,右键检查,发现是间接加载
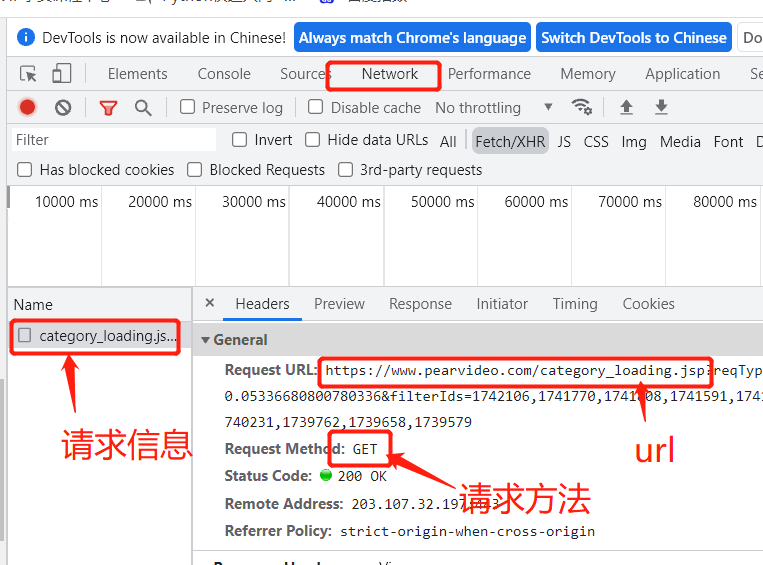
按f12或右键检查呼出后端界面。查看network,需要下拉或刷新页面获取请求信息,可以看到url和请求方式,在Paramerters中categoryld是用来定义视频的种类,start为页面视频数量,为12的倍数,我们可以通过在请求头中对这些数据进行更改,来获得多个视频的量

# 发送get请求网址 res=requests.get('https://www.pearvideo.com/category_9', params={"reqType": 5, "categoryId": 9, "start":page_id}) # 构造解析对象 soup=BeautifulSoup(res.text,'lxml')
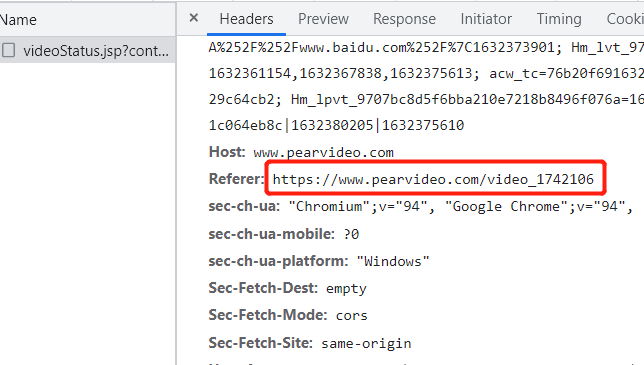
# 获取li列表中a链接标签
li_class=soup.select('.categoryem a.vervideo-lilink')
获取需要的详情ID后,要去进行ID拼接才能请求进入详情界面
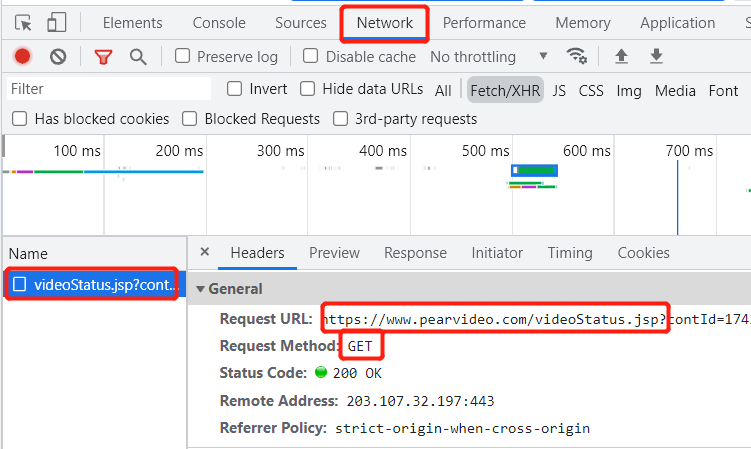
用浏览器进入详情页面后,打开后端,刷新页面,查看请求信息中的url与请求方式,获取源地址信息
# 循环获取视频地址 for a_href in li_class: # 获取网址具体地址 a_list_href=a_href.get('href') # 获取网络ID video_id=a_list_href.split('_')[-1] # print(video_id) # 发送请求 res2=requests.get('https://www.pearvideo.com/videoStatus.jsp?', # 请求体确定视频 params={"contId": video_id}, # 请求头输入防爬链 headers={"Referer": "https://www.pearvideo.com/video_%s"%video_id}, )
但是打开url地址后,并没有视频,所以这不是我么们要的视频地址

那真正的视屏地址在哪呢,首先运行视频,打开页面的网络源码后,查找video标签,那才是视频地址
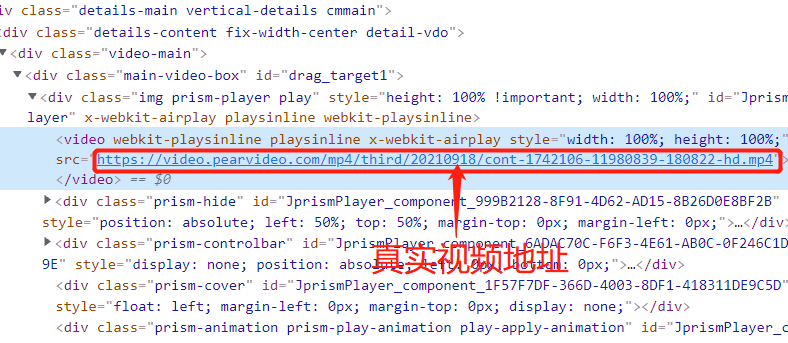
可以发现真实地址与请求的家地址存在相同却又不相似的地方,而假地址的不同数据就是请求数据中获得的systmeTime,所以把家地址中的systemTime中的数据替换成真地址中的数据即可获取事情内容,真地址的不同处为'cont-'加上述首页程序获取的video_id号,便可请求视频数据
# 因为是json格式,使用json转义对应数据,获取假的视频地址 fake_href=res2.json()["videoInfo"]["videos"]['srcUrl'] # print(fake_href) # 获取冲突值 systemtime=res2.json()["systemTime"] # 将假地址变成真地址 real_href=fake_href.replace(systemtime,'cont-%s'%video_id) # 发送请求 res4=requests.get(real_href, # 请求体确定视频 params={"contId": video_id}, # 请求头输入防爬链 headers={"Referer": "https://www.pearvideo.com/video_%s" % video_id}, )
梨视频官网存在防爬链,所以要在请求头加入该数据
# 路径拼接 file_path=os.path.join(r'视频',real_href[-8:]) # 打开路径,以二进制写入 with open(file_path,'wb') as f: # 写入数据 f.write(res4.content) # 提示成功 print("亲下载成功")
如果访问过于频繁,网站地址会把电脑IP封掉,所以最好加个访问延迟,减缓工作量避免被防封号
# 等待时间 time.sleep(1)
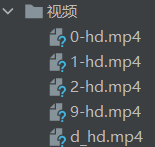
执行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号