本周总结
-
字符编码
电脑只识别低电平和高电平状态,人为的把低电平定义为0、高电平为1这也是二进制
现今人类的数字和字符之间存在对应关系
字符编码发展史
美国最先发明了电脑,为了计算机能识别英语发明了:
ASCII码
内部记录了英文与数字的对应关系
中国:GBK码
内部记录英文、中文与数字的对应关系,现国内windows默认
韩国:Euc_kr码
日本:shift_JIS码
unicode码(万国码)
内部记录各个国家与数字的对应关系
utf8(万国码优化版)
目前默认使用的编码
编码与解码
编码:变量.encode(‘字符编码’)
解码:变量.decode(‘字符解码’)
-
文件操作
文件路径
相对路径:需要一个参考物才可以,例如:隔壁,在前面......
绝对路径:不需要有参考物,例如:GPS
转义字符
\n # 换行符,功能为空行 \t # 制表符,功能为空格 r # 可以取消转义
文件打开
# 推荐用法 with open(文件路劲,读写模式,字符编码) as 变量名 # 不推荐用法 变量名= open(文件路径,读写模式,字符编码) 命令 变量名.close
读写模式
''' r 只读模式 文件路径不存在无法读取文件,会报错 文件路径存在,可以打开文件开始读 开始读文件时,光标在开头,读完时光标在结尾 ''' with open(r'aaa.txt','r',encoding='utf8') as f: print(f.read()) # 一次性读取文件内容 ''' w 只写模式 文件路径不存在会自动创建 文件路径存在,会清空文件再开始写 ''' with open(r'aaa.txt','w',encoding='utf8') as f: f.write('文件内容') ''' a 只追加模式 文件路径不存在会自动创建 文件路径存在,光标会移动到末尾再开始写 ''' with open(r'aaa.txt','a',encoding='utf8') as f: f.write('文件内容') 补充:读取优化 with open(r'aaa.txt','r',encoding='utf8') as f: # 逐行输出文件内容,避免内存空间不够使用 for num in f: print(num)
操作模式
t模式 文本模式(为上述三种模式的默认模式) rt,wt,at 1.该模式只能操作文本文件 2.该模式下需要有encoding字符编码 3.读写都以字符串为单位 b模式 二进制模式,没有字符编码 rb,wb,ab 1.该模式可以操作任意类型文件
文件操作补充
for循环补充: for...in..: else: # 没有被break打断for之后可以执行else语句 文件补充 1.flush() 功能: 将内存中的数据立即刷到硬盘里,类似于Ctrl+s 语法: with open(..,..,...) as f: f.flush() 2.readable(),writeable() 功能: 判断文件是否可执行某写操作,readable()判断是否可读,writeable()判断是否可写 语法: with open(..,..,...) as f: f.readable() f.writeable() 3.writelines() 功能: 用于w,a模式下,逐行写入 语法: with open(..,..,...) as f: f.writelines() 4.seek() 功能: 移动光标 seek(a,b) a是光标移动次数,以整数为次数 b为操作模式,有三个操作模式 b=0: 可以再文本文件和二进制文件执行 光标移动到文件开头 b=1: 只能在二进制文件执行 光标处于当前位置 b=2: 只能在二进制文件执行 光标移动到文档末尾 语法: with open(..,..,...) as f: f.seek(a,b)
补充:
f.read(x)
'''
在文件模式下,输出几个字符
在二进制模式下,输出几个字节
'''
-
函数
''' 提前定义末端代码,类似于把它定义为某种工具,使用时直接使用该工具,不需要,再重新输入代码 函数使用前要先定义 '''
语法: def 函数名(参数1,参数2): '函数注释' 函数体代码 return函数的返回值
函数返回值
返回值的性质?
当函数执行结束时,会返回一个值
如何获得返回值?
变量名 = 方法/函数()
当函数没有可执行代码,函数为空
return+数据,该数据就是函数返回的类型
return返回多个数字,会以元组形式返回
函数中的代码遇到return立即结束整个函数运行
函数的类型
1.无参函数 函数在定义阶段没有参数调用阶段也不需要参数 2.有参函数数 函数在定义阶段有参数,调用阶段需要参数 3.空函数 没有代码 输出为None
函数参数
由函数定义的参数且能运用到括号内书写的参数成为形式参数
简称为形参
函数在调用时在括号内书写的函数为实际参数
简称为实参
形参和实参在函数调用时绑定,运行结束后分开
1.位置参数
按照位置把数据输入,多一少一都不行
2.关键字参数
指名道姓的给形参专职 可以打破位置限制
3.默认参数:函数在定义阶段给形参赋的值
4.可变长参数
使用*+形参,函数就可以接受多个数据的位置参数,输出结果为元组
使用**+形参,函数就可以接受多个关键字参数,输出结果为字典
'''
在可变长函数中的形参的变量名推荐为
*args **kwargs
def 变量名(*args,**kwargs):
pass
'''
*与**在实参中的作用
l=[12,3123,2,43,5] d={'use':'jj','pwd':123} def ind(*a,**k): print(a,k) ''' 将列表或元组的数据,一元组性质输出 ''' ind(*l) # 输出 (12, 3123, 2, 43, 5) {} ''' 接受键值对,将字典输出 ''' ind(**d) # 输出() {'use': 'jj', 'pwd': 123}
-
内置函数
abs(-111) # 取绝对值 111 all([1,23,0]) # 有元素布尔值为False,就输出False any([1,0,4,5])# 有元素布尔值为True,就输出True callable() # 判断元素变量是否可以有实际功能,没有输出False eg: a='1' def i(): pass callable(a) # 输出 False callable(i) # 输出 True chr(65) # 返回ASCII码中数字对应字母 ''' 65-90 对应小写字母 97-122 对应大写字母 ''' format print('name:{},age:{}'.format('jj',18) # 输出name:jj,age:18 print('name:{1}{0}{1},age:{0}{1}'.format('jj',18)) ''' 输出为 name:18jj18,age:jj18 '''
-
模块
import time # print(time.time()) # 输出为时间戳 ''' 时间戳:是从1970年1月1日 ''' print(time.strftime('%Y-%m-%d')) # 输出当前日期2021-08-19 print(time.strftime('%H:%M:%S')) # 12:11:32 ''' X 可以表示 时,分,秒 ''' time.sleep(3) # 让程序停止3秒 import datetime # print(datetime.data.today()) # 当前日期 # print(datetime.datatime.today()) # 当前日期和时间 # 获得本地日期 年月日 tday = datetime.data.today() # 定义操作时间 day=1 也就是可以对另一个时间对象加1天 td = datetime.timedelta(days=1) # 加一天 td = datetime.timedelta(days=-1) # 减一天
-
函数名称和作用域
函数名称
1.内置名称空间
python解释器启动立刻创建结束立刻销毁
2.全局名称空间
代码运行时,实参,变量名和值存储的地方,在文件执行时产生,结束是销毁
3.局部名称空间
类似与函数调用时,形参和实参绑定关系所存储的空间,函数体代码运行时产生、结束后销毁
# 加载循序:
内置名称空间>全局名称空间 > 局部名称空间
作用域
全局作用域
内置名称空间 全局名称空间
局部作用域
局部名称空间
作用域的查看顺序一定要先明确你当前在哪里

在局部时,查看作用域的循序为: 局部名称空间 到 全局名称空间 到 内置名称空间
在全局时,查看作用域的循序为: 全局名称空间 到 内置名称空间
在内置时,作用域为本身
从图来看是由内而外,不接逆序
-
列表生成式
l1 = [1,2,3,4,5] 1. # 通过循环将列表中每个元素加一 # 列表生成式方法 new_list =[i + 1 for i in l1] print(new_list) # 输出[2,3,4,5,6] 2. # 筛选出加一之后大于3的元素 list1 = [i for i in l1 if i+1 > 3] print(list1) # 输出[4,5]
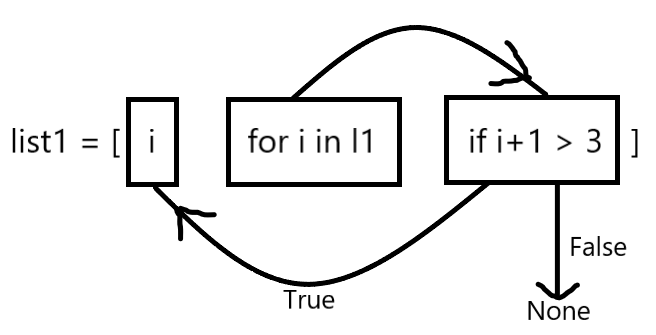
''' 生成式列表里只能存在for 和 i ''' name=['jj','kk','tt','oo'] # 列表生成式 # 在字符后加上'_NB' list = [name+'_NB' for name in name_list] print(list) # 输出['jj_NB','kk_NB','tt_NB','oo_NB'] ''' 生成式优点:减少代码量,代码冗余 '''
-
匿名函数
匿名函数
既没有函数名的函数
语法结构
lanbda 形参:返回值
# 匿名函数一般单独使用 需要结合内置函数/自定义函数等一起使用 l =[1,2,3,4,5,6,7] res = map(lambda x:x+1,1) # 给列表中的每个元素加一 print(list(res))# 遇上述功能相同的函数def index(x): return X + 10res1 = map(index,1)print(list(res1))'''匿名函数主要用于一些比较简单的业务 减少代码量''' map函数 map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每一个元素,并把结果作为新的Iterable返回。其语法格式为: map(function,iterable...) function---函数名 iterable---一个或多个序列
-
三元表达式
'''
补充:
name = 'jj'
if name == 'jj': print('jason登录成功') # 当if语句运行程序只有一段时,可以整体写在一行
'''
#用三元表达式可以简化为 da = input('enter a number:') answer = '大' if da > 4 else '小' print(res) 语法: A if 条件 else B 当if后面的条件为True的时候使用A 为False使用else后面的B
-
内置模块
# 模块
具有一定功能的代码集合
一般是以.py为格式的文件,也可以由多个py文件组成的文件夹,这也叫包
# 导入模块的本质
执行模块内代码并产生一个模块的名称空间,之后将代码执行过程中的变量名或函数存放在该名称空间中
然后给导入模块的语句一个模块名,当时用模块的功能时,该模块指向模块的名称空间
#语法: import 文件名 可以通过模块名使用所有该模块功能 form 文件名 import 变量名,函数名... 只能使用inport模块被导入的功能 from句式主要用于模块与文件在同一级目录下使用 form 路径1.路径2 import 文件名 通过现对路径获取模块 # 为了解决模块名字过长可以起别名,之后依旧可以使用 import 文件名 as 别名 form ... import 文件名 as 别名
-
常用模块
os模块
# 在同级目录下创建 单级目录 os.mkdir(r'文件夹1') # 可以创建多节文件夹 os.makedirs(r'文件夹2\文件夹3') # 也可以创建单级文件夹 os.makedirs(r'文件夹03') # 删除文件夹 os.rmdir(r'文件夹1') # 报错,默认只能删除一级空目录 os.rmdir(r'文件夹02\文件夹03') # 删除多节目录,目录必须为空 os.removedirs(r'文件夹02\文件夹03\文件夹04')
# 查看当前路径下所有文件夹
print(os.listdir())
# 查看指定路径下所有文件夹
print(os.listdir('D:\\'))
# 查看当前所在的路径
print(os.getcwd())
# 切换当前操作路径
os.chdir(r'路径')
#结果输出为布尔值 # 判断是否为文件 print(os.path.isdir(r'文件名.txt')) # 判断是否为文件夹 print(os.path.isfile(r'文件夹名')) # 判断当前路径是否存在 print(os.path.exists(r'路径') )
# 该方法可以针对不同的操作系统会自动切换分割符
res = os.path.join('D:\\',' ')
'''
各操作系统的路径分隔符不一样
windows: \
mac: \
'''
# a 内容为 'hello日' # 输出8 判断文件大小 输出为字节数 print(os.path.getsize(r.'a.txt' ))
random模块
# 随机输出1到6数字 print(random.randint(1,6)) # 随机抽取一个 print(random.choice(['1','2','TT'])) print(random.choices(['1','2','TT'])) #样本有指定个数 #输出一个元素个数为3的随机数列 print(random.sample([111,22,4,5,6,78,13,4],3)) # 随机打乱元素 l=[1,23,4,53,543,62,53] random.shuffle(l) # 随机打乱序列,洗牌 print(l) # 输出为打乱的元素
hashlib模块
加密模块
将明文数据通过一定逻辑变成密文数据,由数字和字符随机组成
加密算法
将明文数据按照一定的逻辑(每个算法内部逻辑都不一样)
加密之后的密文不能反解密出文明
# 选择加密算法 md5 = hashlib.md5() # 将代加密的数据传入算法 # 数据必须是bytes类型(二进制) md5.update(b'hello 123') # 获取加密后的密文 res=md5.hexdigest() # 选择加密算法 md5 = hashlib.md5() # 将待加密的数据传入算法中 actx=input('动态数据:') md5.updat(actx.encode('utf8')) md5.update(b'hello') res = md5.hexdigest() print(res)
logging模块
功能
该模块主要运用于监控监管等
日志级别
logging.debug() # 调试 logging.info() # 通知 logging.warning() # 警告 logging.error() # 出错 logging.critical() # 严重事故 等级最高
级别大小(从左到右,由大到小):
debug < info < warming < error < critical
json模块
语法: json.dumps(变量) #序列化 json.loads(变量) #反序列化 语法: json.dump(序列化变量,存储目标) #文件序列化 json.load(变量) # 文件反序列化
