python的文件操作和函数
昨日内容回顾和改进
1.阐述字符编码由来及发展史
字符编码是为了把人的字符编译成,计算机能识别的二进制数据,字符编码记录了字符和数字对应的关系 用于把人类字符转化成二进制数字 最早由美国发明ACSII编码,中记录英语对二进制一一对应的关系 每八位二进制对应一个字符,即8bit也是一字节对应一个字符 ''' 所有英文符号加起来不超过127种及7字节 为什么多加一位备用 1.多加一位可以作为备用 2.单位换算更加简陋 ''' 中国发明了GBK编码,中记录中文对二进制一一对应的关系,现今国内windows默认编码 在GBK中英文字符占8位(1bit) 中文字符占16位(2bit) ''' 中国纯在许多生僻字,需要多内容的bit表示:例如占用3字节或更多 ''' 韩国发明了Euc_kr编码,中记录韩文对二进制一一对应的关系 日本发明了shift_jis编码,中记录日文对二进制一一对应的关系 unicode编码(万国码)诞生,中记录各个国家的语言对二进制一一对应的关系 所有字符至少要2字节表示 缺点:英文占用过多存储空间,运行效率低 utf-8编码,现在默认使用的编码,是unicode的升级版本 英文使用1字节存储 中文采用3字节存储 # 结论 目前所有的文本文件默认的编码是Utf8 若出现乱码可能是编码和解码的字符编码不一样导致程序无法编译
2.编码与解码理论,python代码如何实现
编码: # 只有字符串类型可以编码 语法: 字符串.encode('字符编码') 解码: # 只有字节数据类型可以编码 语法: 字节型数据.decode('字符编码') ''' 字节型数据例如:b + '字符串' 二进制 '''
3.文件操作语法结构及读写模型,操作模式细节
语法: with open(r'文件相对路径或绝对路径','操作模式',字符编码) as 变量: 命令操作 with open(r'文件相对路径或绝对路径','操作模式',字符编码) as 变量1, open(r'文件相对路径或绝对路径','操作模式',字符编码) as 变量2: 命令操作 ''' r 为读模式 无法读取不存在的文件 一次读完 开始时光标在开头,读完在结尾 w 写模式 不存在的文件直接创造 存在,则清空文件再写内容 a 追加模式 不存在的文件直接创造 存在,则光标在末尾 文件模式 t rt,wt,at此为默认模式与上诉相同 只能操作文本文件 需要声明字符编码 b 二进制模式 rb,wb,ab 此模式不必须申明字符编码 只能输出和输入二进制 可识别所有文件内容 '''
作业改进
1.
利用文件操作编写一个简易的文件拷贝系统
让用户输入需要拷贝的文件路径
然后再获取即将拷贝到哪儿的路径
way=input('请输入拷贝文件路径:') deter_way=input('请输入目的文件路径:') # 原来代码 # with open(way,'r',encoding='utf8') as f: # content = f.read() # with open(deter_way,'w',encoding='utf8') as f: # f.write(content) #读文件和打开文件声明不同变量 with open(r'%s' % way,'r',encoding='utf8') as f,open(r'%s' % deter_way,'w',encoding='utf8') as white_in: for content in f: write_in.write(content) ''' 改进后的优点: 逐行读取和复制,避免了文件过大导致的内存溢出 '''
2.
利用文件操作完成用户的注册 登录
userinfo.txt
基本要求
用户注册获取用户名和密码然后写入文件 jason|123
登录获取用户名和密码之后去文件中比对
# 上述操作完成一次就算成功
拔高练习
用户注册可以多次注册并且校验用户名是否重复
登录需要逐行比对
while True: # 选择功能 request = input('注册还是登录,退出请输入q:') # 注册界面 if request == '注册': allow = True # 用户名不重复时为True,可以执行注册输入信息 load_allow = True # 整个注册的循环,以保证注册成功 while load_allow: # 输入注册用户、密码 username = input('请输入注册用户名:') password = input('请输入注册密码:') with open(r'userinfo.txt','r',encoding='utf8') as f: # 辨认用户名是否重复 for line in f: if username == line.split("|")[0]: print('用户名重复') # 用户名重复则结束 allow = False break else: # 允许注册内容输入 allow = True if allow: # 将输入内容 with open(r'userinfo.txt', 'a', encoding='utf8') as write_in: write_in.write('%s|%s\n' % (username,password)) print('注册成功') load_allow = False # 登录界面 elif request == '登录': # 输入登录信息 username = input('请输入用户名:').strip() password = input('请输入密码:').strip() with open(r'userinfo.txt', 'r', encoding='utf8') as f: # 对登录的循环,登陆成功不循环,登录失败循环 for ex_info in f: real_username,real_password=ex_info.split('|') # 与注册信息匹配 if username == real_username and password == real_password.strip('\n'): print('登录成功') break # else可以与for连用,无break可以实行功能 else: # 若无法匹配到信息,则失败 print('用户或密码错误') # 推出操作系统 elif request =='q': break # 输入其他结果 else: print('输入错误') continue

文件操作补充
for循环补充: for...in..: else: # 没有被break打断for之后可以执行else语句 文件补充 1.flush() 功能: 将内存中的数据立即刷到硬盘里,类似于Ctrl+s 语法: with open(..,..,...) as f: f.flush() 2.readable(),writeable() 功能: 判断文件是否可执行某写操作,readable()判断是否可读,writeable()判断是否可写 语法: with open(..,..,...) as f: f.readable() f.writeable() 3.writelines() 功能: 用于w,a模式下,逐行写入 语法: with open(..,..,...) as f: f.writelines() 4.seek() 功能: 移动光标 seek(a,b) a是光标移动次数,以整数为次数 b为操作模式,有三个操作模式 b=0: 可以再文本文件和二进制文件执行 光标移动到文件开头 b=1: 只能在二进制文件执行 光标处于当前位置 b=2: 只能在二进制文件执行 光标移动到文档末尾 语法: with open(..,..,...) as f: f.seek(a,b) eg: with open(r'aaa.txt','r',encoding='utf8') as f: print(f.read()) f.seek(5,0) print(f.read()) with open(r'aaa.txt','rb') as f: print(f.read())
# 二进制模式下移动的是字节 f.seek(-3,2) print(f.read()) f.seek(-5,1) print(f.read())
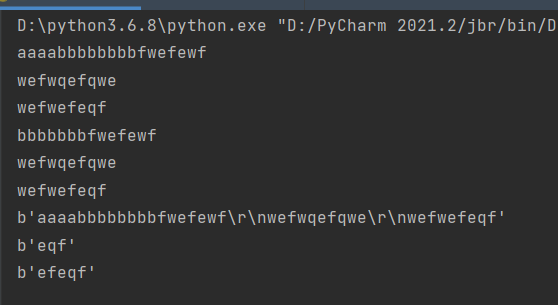
补充:
f.read(x)
'''
在文件模式下,输出几个字符
在二进制模式下,输出几个字节
'''
补充小知识:
硬盘中的数据被删除时,数据是被标记为可占用空间,并没有被完全删除,为了避免这种问题,可以在删除后,再下载垃圾文件覆盖
文件修该
第一种方法 with open(...,'r',encoding='utf8') as f: data=f.read() with open(...,'w',encoding='utf8') as f: f.write(data.replace(....)) ''' 缺点:当文件过大时,会导致内存溢出,降低效率 ''' 第二种方法 ''' 建一个新文件,将老文件内容写入新文件,过程中完成修改,之后,删除老文件,把新文件改名为老文件,词方法要用到模块 ''' import os with open(r'old.txt','r',encoding='utf8')as old,open open(r'new.txt','w',encoding='utf8')as new: for line in old: new.write(line.replace(....)) os.remove(r'old.txt') os.remove(r'new.txt',r'old.txt')
函数
''' 提前定义末端代码,类似于把它定义为某种工具,使用时直接使用该工具,不需要,再重新输入代码 函数使用前要先定义 ''' 语法: def 函数名(参数1,参数2): '函数注释' 函数体代码 return函数的返回值 ''' def:用于定义函数关键字的作用 函数名:性质与变量名一致,使用函数时要调用该函数即可 参数:函数与外界的联系,用于赋值,取值时可以用到 代码:就是被定义的代码,执行函数时就是在执行该代码 return:确定函数返回值,可以不存在
'''
eg:
def printMore (a,b):
print(a+'快回家吃饭')
print(b+'洗澡去')
printMore('小明','小红')
输出结果为:
小明快回家吃饭
小红洗澡去
