

- Hive数据模型
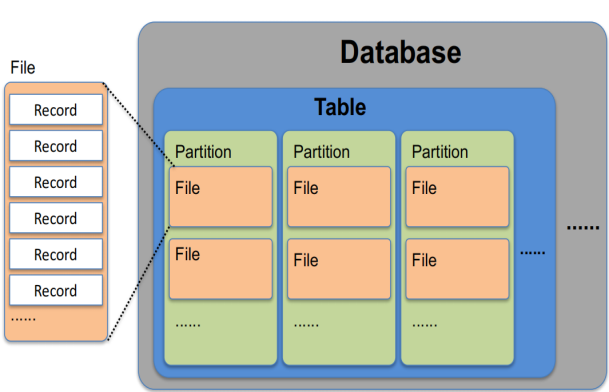
DataBases:和关系型数据库中的数据库一样
Tables:和关系型数据库中的表一样
Partitions(可选):一些特殊的列,用于优化数据的存储和查询
Files:实际数据的物理存储单元
- 数据类型


支持的很多类型同一般的数据库大部分相同,但是里边有特殊类型:如struct、map、array
- 数据定义语句(DDL)
Create/Drop/Alter Database
Create/Drop/Truncate Table
Alter Table/Partition/Column
Create/Drop/Alter View
Create/Drop/Alter Index
Create/Drop Function
Create/Drop/Grant/Revoke Roles and Privileges
Show
Describe
- 数据加载与插入语句
Load data
1 load data [local] inpath 'filepath' [OVERWRITE] into table tablename[PARTITION(partol1=val1,partcol2=val2...)]
如果文件在本地,需要加[local],如果文件在hdfs上不需要添加
filepath:表示文件路径
overwrite:可选的,是否要覆盖数据
tablename:表的名字
Load data:当数据被加载至表中时,不会对数据进行任何转换,Load操作只是将数据复制/移动至Hive表对应的位置。
默认每个表一个目录,比如数据库dbtest中,表名为tbtest,则数据存放位置为:${metastore.warehose.dir}/dbtest.db/tbtest,metastore.warehouse.dir默认值是/user/hive/warehouse
Insert
1 insert overwrite table tablename[PARTITION(partcol1=val1,partcol2=val2...)] select_statement FROM from_statement
从from_statement中将数据查询处理,插入到tablename表中
- 数据模型-分区
为减少不必要的暴力数据扫描,可以对表进行分区
为避免产生过多小文件,建议只对离散字段进行分区(比如年龄可做分区)
partitioned语法:
1 create table employess( 2 name string, 3 salary float, 4 subordinates array<string>, 5 deductions map<string,float>, 6 address struct<street:string,city:string,state:string,zip:int> 7 ) 8 partitioned by (country string,state string);
根据country、state进行分区
.../employess/country=CA/state=AB
.../employess/country=CA/state=BC
.../employess/country=US/state=AK
.../employess/country=US/state=AL
最常用的是:记录日志,用每月/每天作为partition
partition字段是存在目录名中,并不是真正的存储在数据表中
示例:
1 CREATE TABLE IF NOT EXISTS stcoks ( 2 ymd DATE, 3 price_open FLOAT, 4 price_high FLOAT, 5 price_low FLOAT, 6 price_close FLOAT, 7 volume INT, 8 price_adj_close FLOAT 9 ) 10 PARTITIONED BY (exchanger STRING, symbol STRING) 11 ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
创建一张stocks表,以exchanger、symbol为partition,
导入数据:Load(导入数据之前需要将数据按照partition整理好)
1 load data local inpath '/home/zhangc/application/hivedata/stocks/NASDAQ/AAPL/stocks.csv' into table stocks partition(exchanger='NASDAQ',symbol='AAPL');
stocks.csv表示本机需要导入表中的数据;
exchanger='NASDAQ',symbol='AAPL'表示需要将数据导入到hive中的partition
导入数据:insert(指定按照哪一列动态分partition)
创建一个新的分区表record_partition,按照trancation_date进行分区
1 create table if not exists record_partition( 2 rid string, 3 uid string, 4 bid string, 5 price int, 6 source_province string, 7 target_province string, 8 site string, 9 express_number string, 10 express_company string 11 ) 12 partitioned by (trancation_date date);
将原有的record表数据按照trancation_date动态进行分区,导入record_partition表中
1 set hive.exec.dynamic.partition.mode=nonstrict;(这句很重要,否则在执行下面命令时报错) 2 insert into table record_partition partition(trancation_date) select * from record;
partition(trancation_date):表示按照trancation_date动态进行分区
- 外部表
external关键字
删除表时,外部表只删除元数据,不删除数据
数据更加安全
例子:
首先将外部表用到的数据先上传到hdfs上
1 hdfs dfs -put stocks /user/zhangc
创建外部表:
1 create external table if not exists stocks_external( 2 ymd date, 3 price_open float, 4 price_high float, 5 price_low float, 6 price_close float, 7 volume int, 8 price_adj_close float 9 ) 10 partitioned by (exchanger string,symbol string) 11 row format delimited 12 fields terminated by ',' 13 location '/user/zhangc/stocks';
添加外部表关键字:external
location表示:外部表数据在HDFS上的存放位置
载入数据:
1 alter table stocks_external add partition(exchanger='NASDAQ',symbol='AAPL') 2 location '/user/zhangc/stocks/NASDAQ/AAPL/'
表示将外表stocks_external的partition与HDFS上的数据进行关联
- 如何创建ORC表
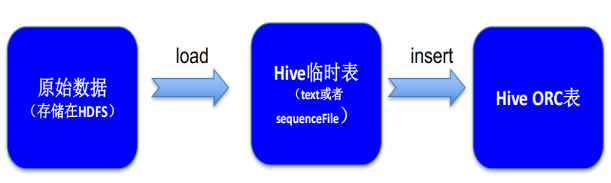
建表:
1 create table if not exists record_ord( 2 rid string, 3 uid string, 4 bid string 5 price int, 6 source_province string, 7 target_province string, 8 site string, 9 express_number string, 10 express_company string, 11 trancation_date date 12 ) 13 stored as orc;
导入数据(从另外一个表中导入数据)
1 insert into table record_orc select * from record;

