
如需大数据开发整套视频(hadoop\hive\hbase\flume\sqoop\kafka\zookeeper\presto\spark):请联系QQ:1974983704
Hadoop分为伪集群模式和主从节点集群模式,本文搭建主从节点模式集群,主要有3个节点(master,slave1,slave2),其中master为主节点,slave1、slave2为子节点。

所需软件hadoop2.7.3,MobaXterm_v8.1,jdk1.8
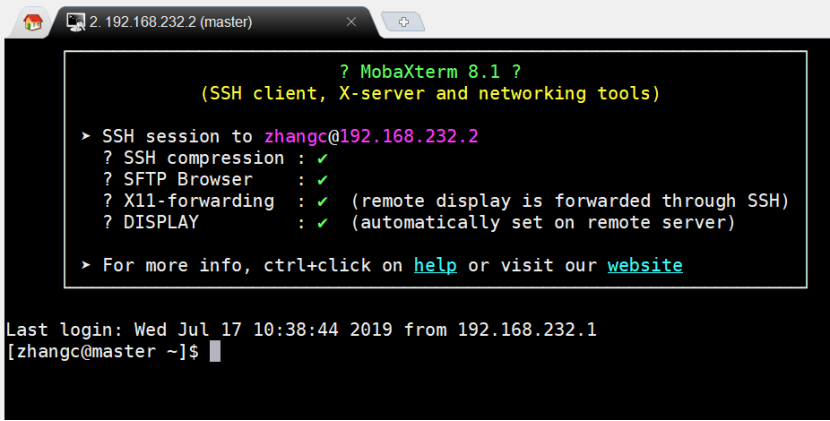
1、通过MobaXterm_v8.1连接CentOS虚拟机
点击左上角”Session”,再点击“SSH”,输入“Remobte host”(CentOS虚拟机IP)

输入“Specify username”(CentOS虚拟机用户名),修改“Session name”为虚拟机IP(master),完成后点击“OK”
2、安装JDK
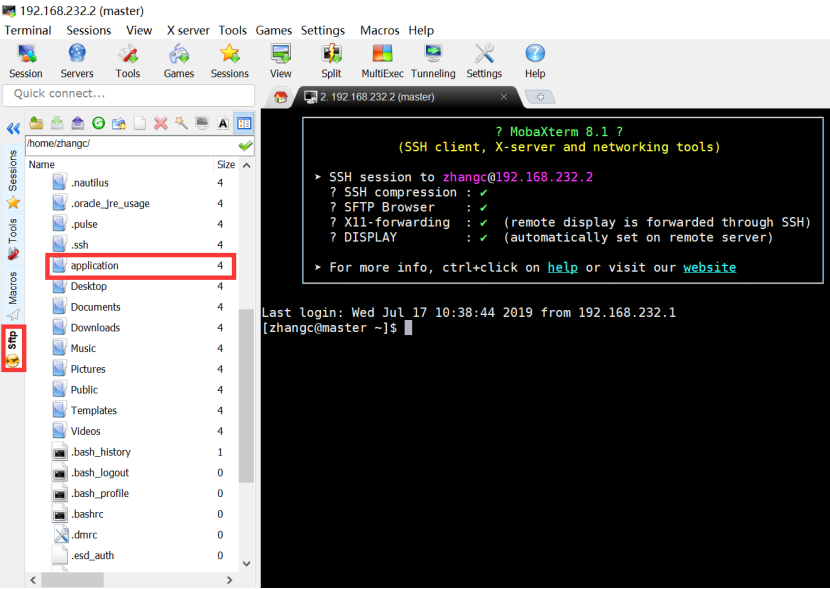
新建文件夹application(后续所有的安装文件都放在该文件夹下)
将下载的jdk-8u111-linux-x64.tar.gz拖动到application文件夹下。
解压JDK包
进入application文件下:
cd application
解压jdk包:
tar -zxvf jdk-8u111-linux-x64.tar.gz
将解压后的文件夹重命名:
mv jdk1.8.0_XXX jdk1.8
打开~/.bash_profile文件:
vi ~/.bash_profile
添加jdk路径配置:
export JAVA_HOME=/home/zhangc/application/jdk1.8(表示jdk所在路径)
export PATH=.:$JAVA_HOME/bin:$PATH
保存~/.bash_profile文件,执行
source ~/.bahs_profile
验证jkd是否正确:
java -version

3、安装hadoop2.7.3
将下载的hadoop-2.7.3.tar.gz拖动到application文件夹下
进入application文件夹:
cd application
解压hadoop包:
tar -zxvf hadoop-2.7.3.tar.gz
重命名解压后的hadoop文件:
mv hadoop-2.7.3.XXX hadoop-2.7.3
修改~/.bash_profile文件:
vi ~/.bash_profile
添加hadoop路径配置:
export HADOOP_HOME=/home/zhangc/application/hadoop-2.7.3(hadoop所在路径)
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
保存~/.bash_profile文件,执行
source ~/.bahs_profile
4、修改hadoop的配置文件
进入application下的hadoop-2.7.3/etc/hadoop文件夹
cd hadoop-2.7.3/etc/hadoop/
修改hadoop-env.sh、core-site.xml、hdfs-site.xml、yarn-site.xml、map-site.xml五个配置文件
(1)hadoop-env.sh
修改JAVA_HOME为JDK的绝对路径
JAVA_HOME=/home/zhangc/application/jdk1.8
(2)core-site.xml
添加内容:
1 <configuration> 2 <property> 3 <name>fs.defaultFS</name> 4 <value>hdfs://master:9000</value> 5 </property> 6 <property> 7 <name>hadoop.tmp.dir</name> 8 <value>/home/zhangc/application/hadoopdata</value> 9 </property> 10 </configuration>
解释:
fs.defaultFS是设置的hadoop默认的文件系统地址,可以修改端口,机器名需要跟虚拟机一致(我的是master)
hadoop.tmp.dir是这只hadoop存放临时文件的目录地址
(3)hdfs-site.xml
添加内容:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/zhangc/application/tmp/hdfs/namenode/</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/zhangc/application/tmp/hdfs/datanode/</value> </property> </configuration>
解释:
dfs.replication是设置存储副本数量,可根据子节的虚拟节点来设置,默认是3,此处我把改为了1.
dfs.namenode.name.dir是设置namenode信息的存放位置,默认是在/tmp下。
dfs.datanode.data.dir是设置datanode的实际数据的存放位置,默认是在/tmp下。
(4)yarn-site.xml
添加内容:
1 <configuration> 2 <!-- Site specific YARN configuration properties --> 3 <property> 4 <name>yarn.nodemanager.aux-services</name> 5 <value>mapreduce_shuffle</value> 6 </property> 7 <property> 8 <name>yarn.resourcemanager.address</name> 9 <value>master:18040</value> 10 </property> 11 <property> 12 <name>yarn.resourcemanager.scheduler.address</name> 13 <value>master:18030</value> 14 </property> 15 <property> 16 <name>yarn.resourcemanager.resource-tracker.address</name> 17 <value>master:18025</value> 18 </property> 19 <property> 20 <name>yarn.resourcemanager.admin.address</name> 21 <value>master:18141</value> 22 </property> 23 <property> 24 <name>yarn.resourcemanager.webapp.address</name> 25 <value>master:18088</value> 26 </property> 27 <property> 28 <name>yarn.log.server.url</name> 29 <value>http://master:19888/jobhistory/logs</value> 30 </property> 31 <property> 32 <name>yarn.nodemanager.vmem-check-enabled</name> 33 <value>false</value> 34 </property> 35 </configuration>
解释:
设置yarn各个服务的端口,我们常用的是webapp地址
设置yarn的日志服务
(5)mapred-site.xml
因为没有mapred-site.xml文件,需要从mapred-site.xml.tamplate复制一份
cp mapred-site.xml.template map-site.xml
添加内容:
1 <configuration> 2 <property> 3 <name>mapreduce.framework.name</name> 4 <value>yarn</value> 5 </property> 6 </configuration>
解释:
设置mapreduce运行在yarn平台上
检查以上内容是否正确。
5、设置/etc/hosts文件,需要用到root权限
su root
vi /etc/hosts
输入:(将ip hostname一一对应,有几个节点填写几个)
192.168.232.2 master
192.168.232.3 slave1
192.168.232.4 slave2
6、检查ip、hostname、防火墙是否关闭,关闭虚拟机
7、Master虚拟机克隆(Slave1,Slave2)
右击“Master”=》“管理”=》“克隆”
下一步
下一步

选择“创建完整克隆”,下一步
填写虚拟机名称Slave1,选择位置,完成
8、设置Slave1和Slave2的IP、hostname(每个子节点都要修改)
修改network文件,需要用到root权限
su root
vi /etc/sysconfig/network
输入:
NETWORKING=yes
HOSTNAME=slave1
再执行:
hostname slave1(子节点名称)
设置完成后,在slave1和slave2中ping master或者ping master的IP

9、设置hadoop集群节点之间SSH免密码登陆(请查看下一篇文章)
https://www.cnblogs.com/20kuaiqian/p/11202330.html
此处一定要设置免密码登陆
10、设置3个虚拟机中的hadoop的slaves文件
cd /home/zhangc/application/hadoop-2.7.3/etc/hadoop/
vi slaves
输入:
master slave1 slave2 (有多少子节点输入多少)
可以一个个节点修改,也可以使用scp
11、格式化HDFS
hadoop namenode -format
12、启动hadoop命令
启动hdfs:
start-dfs.sh
启动yarn:
start-yarn.sh
或者使用start-all.sh,一次启动HDFS和yarn
停止stop-all.sh
启动成功后查看进程:jps
Master主节点:

Slave1和Slave2子节点

到此hadoop集群3个节点搭建完成。
