
1. 总结linux安全模型
1.1资源分派
Authentication:认证,验证用户身份
Authorization:授权,不同的用户设置不同的权限
Accouting|Audition:审计
当用户登陆成功时,系统自动分配令牌token,包括用户标识和组等信息
1.2用户
a.Linux中每个用户是通过User Id(UID)
b.管理员:root,0
c.普通用户:1-6000自动分配:
系统用户:1-999(CentOS 7以后) ,对守护进程获取资源进行权限分配
登陆用户:1000+(CentOS 7以后) ,给用户进行交互式登陆使用
1.3用户组
Linux中可以将一个或多个用户加入用户组中,用户组是通过Group ID(GID)来做唯一标识
a.管理员组:root,0
b.普通组:
系统组:1-499(CentOS 6以前), 1-999(CentOS7以后), 对守护进程获取资源进行权限分配.
普通组:500+(CentOS 6以前), 1000+(CentOS7以后), 给用户使用.
1.4用户和组的关系
用户的主要组(primary group):用户必须属于一个且只有一个主组,默认创建用户时会自动创建和用户名同名的组,作为用户的主要组,由于此组中只有一个用户,又称为私有组.
用户的附加组(supplementart group):一个用户可以属于零个或多个辅助组,附属组.
例:
[root@rocky8 ~]#id c
uid=1000(c) gid=1000(c) groups=1000(c),1003(m4)
1.5安全上下文
Linux安全上下文context:运行中的程序,即进程(process),以进程发起者的身份,运行所能够访问资源的权限取决于进程的运行者身份.
例如分别以root和wang的账号运行/bin/cat /etc/shadow
[root@rocky8 ~]#/bin/cat /etc/shadow
root:$6$CeT0BvDVozDEh0om$OqW/99jTO4/vYcr2DOnqQaQSeO3Y09X14oqJAkISdDIJbOEi3DwGJkk4pitUTdHs/nHcfxYidg9TNQkQvCKnc.::0:99999:7:::
bin:*:19326:0:99999:7:::
daemon:*:19326:0:99999:7:::
adm:*:19326:0:99999:7:::
lp:*:19326:0:99999:7:::
[cz@rocky8 root]$/bin/cat /etc/shadow
/bin/cat: /etc/shadow: Permission denied
2. 总结学过的权限,属性及ACL相关命令及选项,示例。
2.1 总结
对于一个 Linux 系统中的文件来说,它的权限一般可以分为三种:读的权限、写的权限和执行的权限,分别用 r、w 和 x 表示。不同的用户具有不同的读、写和执行的权限。
对于一个文件来说,它都有一个特定的所有者,也就是对文件具有所有权的用户。同时,由于在Linux系统中,用户是按组分类的,一个用户属于一个或多个组。文件所有者以外的用户又可以分为文件所有者的同组用户和其它用户。因此,Linux 系统按文件所有者、文件所有者同组用户和其它用户三类规定不同的文件访问权限。
Linux中的文件能否被访问和工具(程序)无关,和访问的用户身份有关(谁去运行这个程序)
进程的发起者若是文件的所有者: 拥有文件的属主权限
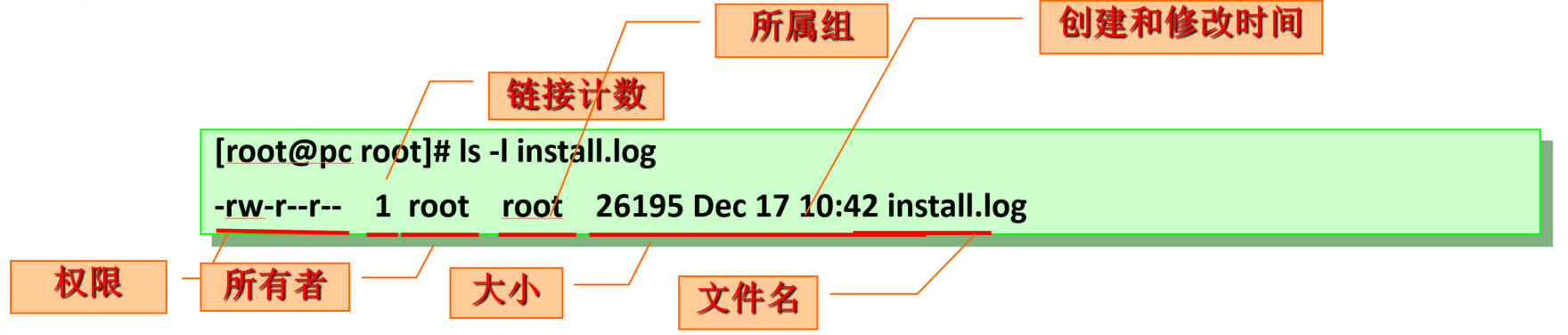
2.2 属性及ACL相关命令及选项
a. chown 命令可以修改文件的属主,也可以修改文件属组
格式 chown [OPTION]... [OWNER][:[GROUP]] FILE...
chown [OPTION]... --reference=RFILE FILE...
用法说明:
OWNER #只修改所有者
OWNER:GROUP #同时修改所有者和属组
:GROUP #只修改属组,冒号也可用 . 替换
--reference=RFILE #参考指定的的属性,来修改
-R #递归,此选项慎用,非常危险!范例:
[root@rocky8 ~]#ll 1.txt
-rw-r--r-- 1 root root 0 Oct 9 01:24 1.txt
[root@rocky8 ~]#chown wang:wang 1.txt
[root@rocky8 ~]#ll 1.txt
-rw-r--r-- 1 wang wang 0 Oct 9 01:24 1.txt
b. 修改文件权限chmod
格式
chmod [OPTION]... MODE[,MODE]... FILE...
chmod [OPTION]... OCTAL-MODE FILE...
#参考RFILE文件的权限,将FILE的修改为同RFILE
chmod [OPTION]... --reference=RFILE FILE
说明:模式法格式
who:u,g,o,a
opt:+,-,=
permission:r,w,x
修改指定一类用户的所有权限
u= u+ u-
g= g+ g-
o= o+ o-
a= a+ a-
-R 递归修改
例:
[root@rocky8 data]#ll 1.txt
-rw-r--r-- 1 wang wang 0 Oct 9 01:24 1.txt
[root@rocky8 data]#chmod u=rwx,g=w,o+w 1.txt
[root@rocky8 data]#ll 1.txt
-rwx-w-rw- 1 wang wang 0 Oct 9 01:24 1.txt
[root@rocky8 data]#chmod -R 700 /root/data
[root@rocky8 data]#ll /root/data
total 0
-rwx------ 1 wang wang 0 Oct 9 01:24 1.txt
-rwx------ 1 wang wang 0 Oct 9 12:14 2.txt面试题:
执行cp /etc/issue /data/dir/ 所需的最小权限?
/bin/cp 命令的x权限
/etc/ 的x权限
/etc/issue的r权限
/data/ 的x权限
/data/dir/的wx权限
c. ACL相关命令
[root@rocky8 data]#su wang
[wang@rocky8 data]$echo 3 > 1
[wang@rocky8 data]$cat 1
3
[wang@rocky8 data]$exit
[root@rocky8 data]#setfacl -m u:wang:- 1
[root@rocky8 data]#getfacl 1
# file: 1
# owner: root
# group: root
user::rw-
user:wang:---
group::rw-
mask::rw-
other::rw-
[root@rocky8 data]#su wang
[wang@rocky8 data]$echo 4 > 1
bash: 1: Permission denied
3. 结合vim几种模式,学会使用vim几个常见操作。
1)如何打开文件。并在打开文件(命令模式)之后如何退出文件。
vim 1.txt
输入:q退出文件
2)打开文件(命令模式)之后,进入插入模式。并在插入模式中如何回到打开文件的状态(命令模式),并在命令模式之后如何退出文件。
按i进入插入模式,按esc回到命令模式,输入:q退出文件.
3)打开文件(命令模式)之后,进入插入模式,编写一段话,"马哥出品,必属精品", 之后从插入模式中如何回到打开文件的状态(命令模式),并在命令模式之后如何退出文件。
vim 1.txt
按i,输入"马哥出品,必属精品",
按esc,输入:wq
4)使用cat命令验证文件内容,是刚刚自己写的内容。
cat 1.txt
5)(可选),命令模式下,光标在单词,句子上进行前后,上下跳转。行复制粘贴。行删除。
方向键控制光标移动
快速移动至行首行尾 ^ $
复制游标所在的那一行(常用) yy
粘贴 p/P
剪切光标所在行 dd
4. 总结学过的文本处理工具,文件查找工具,文本处理三剑客, 文本格式化命令(printf)的相关命令及选项,示例。
4.1文本处理工具
cat
格式 cat [OPTION]...[FILE]
选项-E:显示行结束符$
-A:显示所有控制符
-n:对显示出的每一行进行编号
-b:非空行编号
-s:压缩连续的空行成一行
[root@rocky8 data]#cat -Anbs 1.txt
$
1 3asdf$
2 asdf$
3 asd$
4 asd$
5 asd$
6 asd$
tac 逆向显示,竖
[root@rocky8 data]#cat 1.txt
1
2
3
4
5
[root@rocky8 data]#tac 1.txt
5
4
3
2
1
rev 同行逆向,横向
[root@rocky8 data]#echo {a..d}
a b c d
[root@rocky8 data]#echo {a..d}|rev
d c b a
more 可以实现分页查看文件,可以配合管道实现输出信息的分页
less 相比more可以上下键控制方向,也可以实现分页查看文件或STDIN输出,less 命令是man命令使用的分页器
cut可以提取文本文件或stdin数据的指定列
-d DELIMITER: 指明分隔符,默认tab
-f FILEDS:
#: 第#个字段,例如:3
#,#[,#]:离散的多个字段,例如:1,3,6
#-#:连续的多个字段, 例如:1-6
混合使用:1-3,7
-c 按字符切割
--output-delimiter=STRING指定输出分隔符范例:
[root@rocky8 ~]#cut -d: -f1,3-4,7 /etc/passwd|head -n3
root:0:0:/bin/bash
bin:1:1:/sbin/nologin
daemon:2:2:/sbin/nologin
[root@rocky8 ~]#ifconfig | head -n2|tail -n1|cut -d" " -f10
10.0.0.128
paste 合并多个文件同行号的列到一行
常用选项: -d #分隔符:指定分隔符,默认用TAB
-s #所有行合成一行显示
[root@rocky8 data]#paste 1.txt 2.txt
1 a
2 b
3 c
4 d
wc命令可统计行总数,单词总数,字节总数,和字符总数,可以对文件火STDIN中的数据统计
常用选项
-l 只计行数
-w 只计单词总数
-c 只计字节总数
-m 只计数字符总数
-L 显示文件中最长长度
例
[root@rocky8 data]#cat 3.txt
1 a
2 b
3 c
4 d
5
[root@rocky8 data]#wc 3.txt
5 9 19 3.txt
[root@rocky8 data]#wc -l 3.txt
5 3.txt
[root@rocky8 data]#wc -w 3.txt
9 3.txt
[root@rocky8 data]#wc -c 3.txt
19 3.txt
[root@rocky8 data]#wc -m 3.txt
19 3.txt
[root@rocky8 data]#wc -L 3.txt
9 3.txt
sort 文本排序,只显示,不修改原文件
常用选项
-r 执行反方向(上至下)整理
-R 随机排序
-n 执行按数字大小整理
-h 人类可读排序,如2K 1G
-f 选项忽略(fold)字符串中的字符大小写
-u 去重,(独特,unique),合并重复项
-t c 选项是用c作为字段界定符
-k # 选项按照使用c字符分隔的#列来整理能够使用多次
例:
[root@rocky8 data]#sort -r 3.txt
5
4 d
3 c
2 b
1 a
[root@rocky8 data]#sort -R 3.txt
3 c
2 b
4 d
1 a
5
uniq去重,删除前后相接重复的行
常见选项:
-c 显示每行重复出现的次数
-d 仅显示重复过的行
-u 仅显示不曾重复的行
[root@rocky8 data]#sort 1.txt
1
1
2
2
3
3
4
4
5
5
[root@rocky8 data]#sort 1.txt | uniq
1
2
3
4
5
[root@rocky8 data]#sort 1.txt | uniq -c
2 1
2 2
2 3
2 4
2 5
#取文件的不同行
[root@rocky8 data]#cat 1.txt 3.txt| sort|uniq -u
1 a
2 b
3 c
4 d
5
diff 比较文件之间的区别
-u 输出"统一的(unified)"diff格式文件,最适用于补丁文件
例:
[root@rocky8 data]#diff 1.txt 2.txt
1,2c1,2
< mage
< zhang
---
> magedu
> zhang sir
5c5
<
---
> shi
5. 总结文本处理的grep命令相关的基本正则和扩展正则表达式。
5.1 grep
常见选项:
--colotr=auto 对匹配到的文本着色显示
-m # 匹配#次后停止
-v 显示不被pattern匹配到的行,取反
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after,显示后#行
-B # before,显示前#行
-C # context,前后各#行
-e 实现多个选项间的逻辑or关系,如grep -e 'cat' -e 'dog' file
-w 匹配整个单词
-E 使用ERE,相当于egerp
-F不支持正则表达式,相当于fgrep
-P 支持perl格式的正则表达式
-f file根据模式文件处理
-r 递归目录,但不处理软链接
-R 递归目录,但处理软链接例:
[root@rocky8 ~]#grep root -C2 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
--
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
基本正则表达式元字符
. 匹配任意单个字符(除了\n),可以是一个汉字或其他国家的文字
[] 匹配指定范围内的任意单个字符,实例:[wang] [0-9] [a-z] [a-zA-Z]
[^] 匹配指定方位外的任意单个字符,示例[^wang]
[:alnum:] 匹配所有字母和数字
[:alpha:] 代表任何英文大小写字符,亦即A-Z a-z
[:lower:] 小写字母,示例:[[:lower:]],相当与[a-z]任意单个字符
[:upper:] 大写字幕
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格,制表符(水平和垂直),换行符,回车符等各种类型的空白,比[:blank:]包含的范围广
[:cntrl:] 不可打印的控制字符(退格键,删除,警铃...)
[:digit:] 十进制数字
[:xdigit:] 十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
\s #匹配任何空白字符,包括空格,制表符,换页符等.等价于[\f\r\t\v].注意unicode正则表达式会匹配全角空格符
\S #匹配任何非空白字符,等价于[^\f\r\t\v]
\w #匹配一个字母,数字,下划线,汉字,其他国家文字的字符,等价于[_[:alnum:]字]
\W #匹配一个非字母,数字,下划线,汉字,其他国家文字的字符[^_[:alnum:]字]
匹配次数
* 匹配前面字符人一次,包括0次,贪婪模式:尽可能长的匹配
.* 匹配任意长度的任意字符
\? 匹配前面字符出现0次或1次,即可有可无
\+ 至少出现1次
\{n\} 匹配前面的字符n次
\{m,n\} 匹配至少m次,最多n次
\{,n\} 匹配至多n次,
\{n,\} 匹配至少n次位置锚定
^ 行首锚定,用与模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN$ 'PATTERN'为内容,用于模式匹配整行
^$ 匹配空行
^[[:space:]]*$ 空白行
\<或\b 词首锚定,用于单词模式的左侧
\>或\b 词尾锚定,用于单词模式的右侧
\PATTERN\ 'PATTERN'为内容,匹配整个单词
注意:单词是有字母,数字,下划线组成.
例子:排除空行和#开头的行
grep '^$' /etc/fstab|grep -v '^#'
grep '^[^#]' /etc/profile [^#]指排开头为#的行
grep -v '^$\|#' /etc/profile
分组
分组()将多个字符捆绑在一起,当作一个整体处理,如:\(root\)+
后向引用:分组括号中的模式匹配到的内容,会被正则表达式引擎记录与内部的变量中,这些变量的命名方式为\1,\2,\3,...
\1表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
注意:\0标识正则表达式匹配的所有字符
例:
\(string1\(string2\)\)
\1 :string1\(string2\)
\2 :string2注意:后向引用引用前面的分组括号中的模式所匹配的字符,而分模式本身.
6. 总结变量命名规则,不同类型变量(环境变量,位置变量,只读变量,局部变量,状态变量)如何使用。
7. 通过shell编程完成,30鸡和兔的头,80鸡和兔的脚,分别有几只鸡,几只兔?
8. 结合编程的for循环,条件测试,条件组合,完成批量创建100个用户,
1)for遍历1..100
2)先id判断是否存在
3)用户存在则说明存在,用户不存在则添加用户并说明已添加。
9. 磁盘存储术语总结: head, track, sector, sylinder.
10. 总结MBR,GPT结构。
11. 总结学过的分区,文件系统管理,SWAP管理相关的命令及选项,示例
fdisk, parted, mkfs, tune2fs, xfs_info, fsck, mount, umount, swapon, swapoff
12. 总结raid 0, 1, 5, 10, 01的工作原理。总结各自的利用率,冗余性,性能,至少几个硬盘实现。
13. 完成不影响业务对LVM磁盘扩容及缩容示例。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义