
VGG详解_基于up主总结
其发表的原论文地址:https://arxiv.org/abs/1409.1556
参考来自:
up主的b站链接:https://space.bilibili.com/18161609/channel/index
up主的CSDN博客:https://blog.csdn.net/qq_37541097/article/details/103482003
up主GitHub:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing
VGG 在2014年由牛津大学著名研究组 VGG(Visual Geometry Group)提出,斩获该年 ImageNet 竞赛中 Localization Task(定位任务)第一名和 Classification Task(分类任务)第二名。共提及出了四种不同深度层次的网络结构,分别是11、13、16、19层。
这些网络结构如图所示
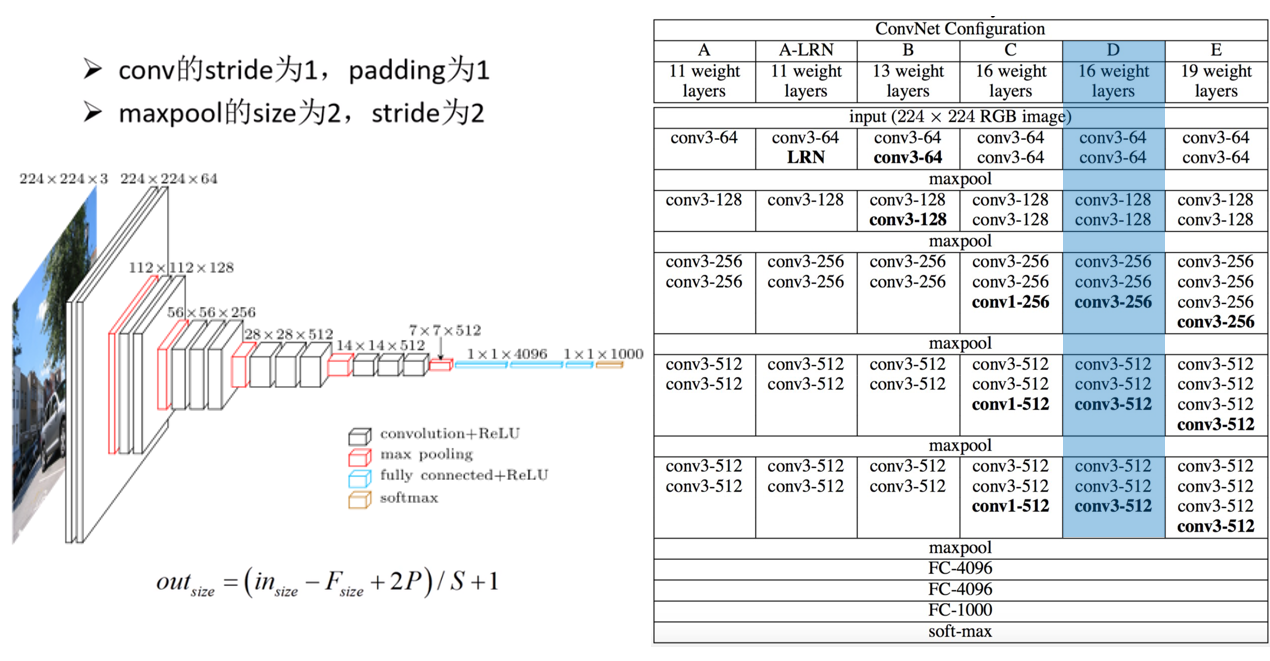
conv3-64表示使用64个3×3的卷积核 ,maxpool表示使用2×2的最大值池化核,FC-4096表示具有4096个神经元的全连接层(其中FC-1000未使用ReLU激活函数,前两个有使用),注意,对于卷积核,默认stride为1,spadding为1,size为3*3,采用的池化核是2*2,
最常用的网络结构有两个,分别是:VGG16(图中的D)和VGG19(图中的E),二者最大的差别就是网络深度的不同。
感受野
输出feature map上的一个单元 对应 输入层上的区域大小。以如下图为例,输出层 layer3 中一个单元 对应 输入层 layer2 上区域大小为2×2(池化操作),对应输入层 layer1 上大小为5×5
计算公式为:F(i)=(F(i+1)−1)×Stride +Ksize
- F(i)为第 i层感受野
- Stride为第 i层的步距
- Ksize为 卷积核 或 池化核 尺寸

以图中计算:
Feature map:F(3)=1
Pool1:F(2)=(1−1)×2+2=2
Conv1: F(1)=(2−1)×2+3=5
论证:两个3×3的卷积核感受野相当于一个5x5的卷积核,三个3×3的卷积核感受野相当于一个7x7的卷积核
Feature map: F=1
Conv3x3(3): F=(1−1)×1+3=3
Conv3x3(2): F=(3−1)×1+3=5
Conv3x3(1): F=(5−1)×1+3=7
pytorch搭建VGG网络:
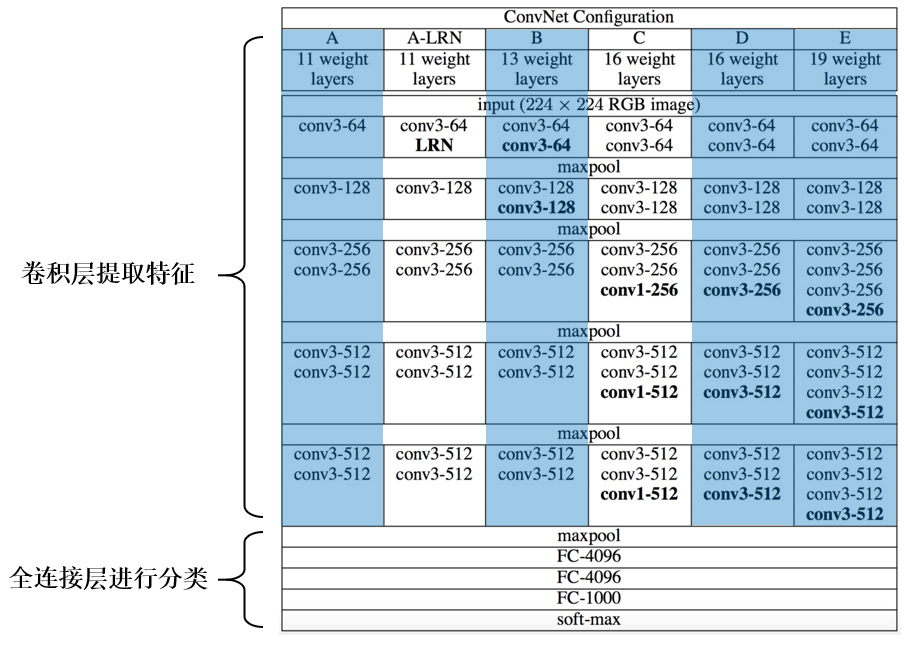
分为卷积层提取特征和全连接层分类两个模块:
代码如下:


import torch.nn as nn import torch class VGG(nn.Module): def __init__(self, features, num_classes=1000, init_weights=False): super(VGG, self).__init__() self.features = features # 卷积层提取特征 self.classifier = nn.Sequential( # 全连接层进行分类 nn.Dropout(p=0.5), nn.Linear(512*7*7, 2048), nn.ReLU(True), nn.Dropout(p=0.5), nn.Linear(2048, 2048), nn.ReLU(True), nn.Linear(2048, num_classes) ) if init_weights: self._initialize_weights() def forward(self, x): # N x 3 x 224 x 224 x = self.features(x) # N x 512 x 7 x 7 x = torch.flatten(x, start_dim=1) # N x 512*7*7 x = self.classifier(x) return x def _initialize_weights(self): for m in self.modules(): if isinstance(m, nn.Conv2d): # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') nn.init.xavier_uniform_(m.weight) if m.bias is not None: nn.init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): nn.init.xavier_uniform_(m.weight) # nn.init.normal_(m.weight, 0, 0.01) nn.init.constant_(m.bias, 0)
其他内容待补充。。。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号