

Hadoop序列化
序列化定义
把内存中的数据持久化(把内存中的对象转换为字节码文件存储带磁盘上)和网络传输。
反序列化定义
反序列化就是把接收到的字节序列(或其它协议传输的数据)或持久化的磁盘数据转换为内存对象。
为什么进行序列化操作?
一般内存对象断电时就会消失,而且只能由本地进程去使用,序列化就可以存储内存对象并将对象发送到远程计算机。
Java序列化和Hadoop序列化对比
Java的Serizable是重量级的序列化框架吗,一个对象序列化后会有很多额外的校验信息,不便在网络中传输。
hadoop序列化更加紧凑(合理使用存储空间)快速(读写数据的额外开销少)互操作(支持多种语言的交互)
hadoop自定义数据序列化
一般常用数据序列化的类型不能满足开发需要,比如自己定义一个bean类,如何对自定义的数据类型序列化呢?
(1)实现Writable接口
(2)重写序列化和反序列化方法。
(3)反序列化时要反射调用空参构造函数,要有空参构造
(4)反序列化和序列化的顺序要一致
(5)要把结果显示到文件中需要重写toString(),可用"\t"分开方便后续使用。
(6)如果想把bean作为key传输需要实现Comparable(MapReduce中的shuffule要求对key必须能排序)。
序列化案例
统计一个手机号的上行流量、下行流量和总流量
(1)输入数据
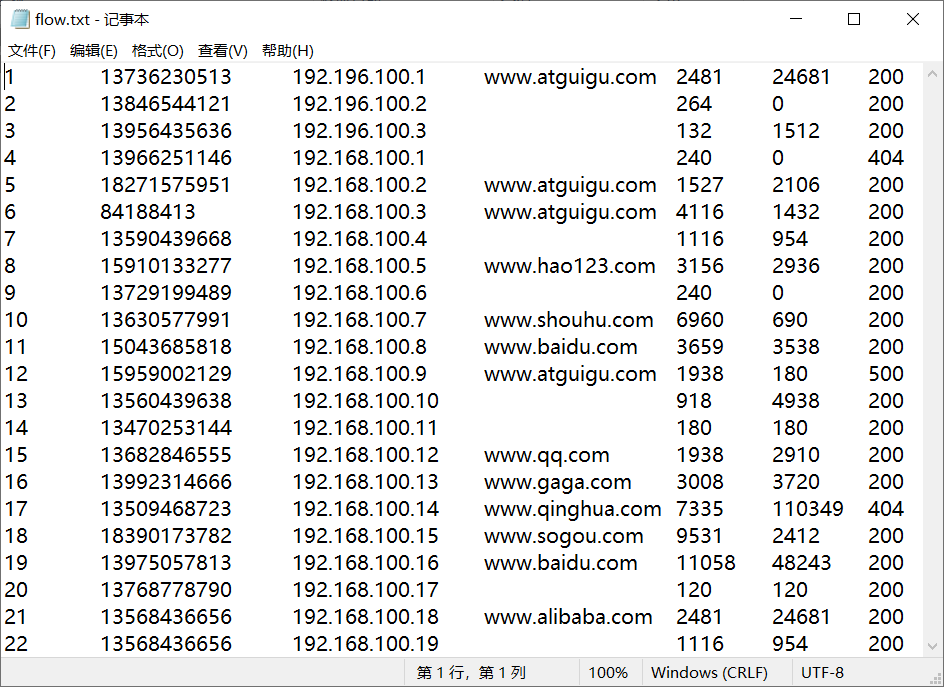
(2)输入数据格式:
id 手机号 ip 域名 上行流量 下行流量 网络状态码
(3)输出数据格式
手机号 上行流量 下行流量 总流量
(4)根据输入、输出格式分析可知
map阶段输出(reduce输入)和reduce输出的key是手机号,而map阶段输出的value要包括上行流量、下行流量、总流量,所以设计封装bean作为value以及作为reduce的输入value,然后将bean以给出的格式输出到文件中(重写toString()方法),完成操作。
(5)代码编写
FlowBean

package com.rsh.mapreduce.flow; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class FlowBean implements Writable { private long upFlow; private long downFlow; private long sumFlow; public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } public long getSumFlow() { return sumFlow; } public void setSumFlow(long sunFlow) { this.sumFlow = sunFlow; } public void setSumFlow() { this.sumFlow = this.upFlow + this.downFlow; } public FlowBean() { } @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeLong(upFlow); dataOutput.writeLong(downFlow); dataOutput.writeLong(sumFlow); } @Override public void readFields(DataInput dataInput) throws IOException { this.upFlow = dataInput.readLong(); this.downFlow = dataInput.readLong(); this.sumFlow = dataInput.readLong(); } @Override public String toString() { return upFlow + "\t" + downFlow + "\t" + sumFlow; } }
FlowMapper
package com.rsh.mapreduce.flow; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class FlowBean implements Writable { private long upFlow; private long downFlow; private long sumFlow; public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getDownFlow() { return downFlow; } public void setDownFlow(long downFlow) { this.downFlow = downFlow; } public long getSumFlow() { return sumFlow; } public void setSumFlow(long sunFlow) { this.sumFlow = sunFlow; } public void setSumFlow() { this.sumFlow = this.upFlow + this.downFlow; } public FlowBean() { } @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeLong(upFlow); dataOutput.writeLong(downFlow); dataOutput.writeLong(sumFlow); } @Override public void readFields(DataInput dataInput) throws IOException { this.upFlow = dataInput.readLong(); this.downFlow = dataInput.readLong(); this.sumFlow = dataInput.readLong(); } @Override public String toString() { return upFlow + "\t" + downFlow + "\t" + sumFlow; } }
FlowReducer
package com.rsh.mapreduce.flow; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class FlowReducer extends Reducer<Text,FlowBean,Text,FlowBean> { private FlowBean outV = new FlowBean(); @Override protected void reduce(Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context) throws IOException, InterruptedException { long totalUp = 0; long totalDown = 0; //遍历相同号码的上行、下行流量、总流量进行累加 for (FlowBean value : values) { totalUp += value.getUpFlow(); totalDown += value.getDownFlow(); } //封装outKV outV.setUpFlow(totalUp); outV.setDownFlow(totalDown); outV.setSumFlow(); //写出outK outV context.write(key,outV); } }
FlowDriver
package com.rsh.mapreduce.flow; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class FlowDriver { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { //获取job对象 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); //关联本driver类 job.setJarByClass(FlowDriver.class); //关联Mapper、Reducer类 job.setMapperClass(FlowMapper.class); job.setReducerClass(FlowReducer.class); //设置Map的outKV类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); //设置程序最终输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); //设置程序的输入输出路径 FileInputFormat.setInputPaths(job,new Path("D:\\hadoopMR\\MRInput\\flow.txt")); FileOutputFormat.setOutputPath(job,new Path("D:\\hadoopMR\\MROutput4")); //提交job boolean b = job.waitForCompletion(true); System.exit(b ? 0 : 1); } }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!