《Unix/Linux系统编程》课上学习内容
9.8学习
一、知识点

二、代码段
♥重要代码♥
gcc -Iinclude src/*.c -o bin/hello2 #链接include中的头文件并编译src中的所有.c文件为hello2
# gcc -I(头文件位置) .c文件 -o a.out文件
gcc -E hello.c -o hello.i #1.预处理
gcc -S hello.i -o hello.s #2.编译
gcc -c hello.s -o hello.o #3.汇编
gcc hello.o -o hello #4.链接
./hello #5.运行
ls #列出目录内容
mkdir shiyanlou #创建目录shiyanlou
ls
cd shiyanlou #更改到shiyanlou目录
mkdir src #创建目录src
mkdir bin #创建目录bin
mkdir docs #创建目录docs
mkdir include #创建目录include
tree #以树状格式列出目录内容

emacs hello.c #用emacs编辑器创建并编辑hello.c
touch makefile #创建makefile文件
touch readme.md #创建readme.md文件
mv hello.c src #移动hello.c文件到src文件夹


gcc src/hello.c -o bin/hello #将src文件夹中的hello.c编译为bin文件夹中的hello
tree
bin/hello #运行bin文件夹中的hello
mv src/hello.c src/main.c #将src中的hello.c重命名为main.c
cp src/main.c src/hello.c #复制src中的main.c为hello.c
tree

emacs src/main.c
emacs src/hello.c
emacs include/hello.h #创建头文件hello.h
tree
main.c

hello.c

hello.h


gcc src/*.c -o bin/hello2 #编译src中的所有.c文件为hello2(错误)
gcc -Iinclude src/*.c -o bin/hello2 #链接include中的头文件并编译src中的所有.c文件为hello2
# gcc -I(头文件位置) .c文件 -o a.out文件
bin/hello2
tree

cd .. #返回上一目录
emacs hello.c
ls
gcc -E hello.c -o hello.i #1.预处理
gcc -S hello.i -o hello.s #2.编译
gcc -c hello.s -o hello.o #3.汇编
gcc hello.o -o hello #4.链接
./hello #5.运行

ls
od -tx1 hello.o #查看二进制文件

file hello.o #辨识文件类型
file hello

9.15学习
一、知识点
1. 模块:(高内聚,低耦合)
- 结构化、面向对象、函数式
2. 静态库、动态库
| 实现 | 声明 | |
|---|---|---|
| 源文件 | xx.c | xx.h |
| 静态库 | libxx.a (libxx.lib) | xx.h |
| 动态库 | libxx.so (libxx.dll) | xx.h |
二、代码段
♥重要代码♥
## 1.静态:
ar rcs libhello.a hello.o #创建静态链接库
gcc main.c -Llib -lhello -o hello #使用静态链接库
#-L+库位置: -L.当前位置; -Llib:lib文件夹
#-l+xx:调用libxx.a
## 2.动态:
gcc -shared -fPIC -o libhello.so hello.c #创建动态链接库
gcc main.c -L. -lhello -o hello #使用动态链接库
export LD_LIBRARY_PATH=./ #此方式仅在当前终端有效,关闭终端后无效
#export LD_LIBRARY_PATH=动态库路径
#sudo cp libhello.so /usr/lib 即可长期使用
(一)静态链接库(浪费内存)
ls
gcc -c *.c
ls
ar rcs libhello.a hello.o #创建静态链接库
ls


mkdir lib
mv libhello.a lib
tree
gcc main.c -Llib -lhello -o hello #使用静态链接库
#-L+库位置: -L.当前位置; -Llib:lib文件夹
#-l+xx:调用libxx.a
ls
./hello

(二)动态链接库
ls
gcc -c *.c
ls
gcc -shared -fPIC -o libhello.so hello.c #创建动态链接库
ls

gcc main.c -L. -lhello -o hello #使用动态链接库
./hello #执行过程中无法找到 libhello.so 动态链接库
ls
export LD_LIBRARY_PATH=./ #此方式仅在当前终端有效,关闭终端后无效
#cp libhello.so /usr/lib 即可长期使用
./hello

(三)makefile
ls
make #默认运行makefile或Makefile
make
ls
make clean
ls



ls
mv makefile m
make #此时没有找到默认的makefile,无法运行
make -f m #以m作为makefile运行make
make -f m clean
ls

(四)Debug(GDB、CGDB、DDD)
sudo apt install gdb cgdb ddd #下载安装gdb,cgdb,ddd
ls
gcc -g test.c #调试
ls
gdb a.out

b main
r #(run)运行
n #(next)一步执行完函数(优先使用)
s #(step)进入函数内部一步步执行
finish # 执行完函数
c #(continue)
p i #(print i)打印某值
until # 将循环执行完
display # 显示某值





b main # 函数断点 (b+函数名)
tb 7 # 临时断点(第7行)+ c --> 到7行
b 10 # 行断点(12行)--> 到12行
b 8 if i==10 # 条件断点

9.22学习
一、知识点
1.系统调用:
| 文件 | I/O | ||
|---|---|---|---|
| 虚拟存储 | I/O | M | |
| 进程 | I/O | M | CPU |
2.学Linux命令
(1)命令功能
(2)man
man -k key(命令)
grep -nr xxx(查找内容) /usr/include
(3)伪代码
(4)实现
二、代码段
(一)sort
在OpenEuler环境下使用 man -k sort ,发现并没有找到想要的sort,直接用 man sort 、 man 2 sort 也是没有找到,于是我使用比较万能的 sort --help 命令来查看sort的帮助文档
总结sort用法如下:
- sort格式
sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][--help][--verison][文件][-k field1[,field2]] - sort常用选项
-b 忽略每行前面开始出的空格字符。
-c 检查文件是否已经按照顺序排序。
-d 排序时,处理英文字母、数字及空格字符外,忽略其他的字符。
-f 排序时,将小写字母视为大写字母。
-i 排序时,除了040至176之间的ASCII字符外,忽略其他的字符。
-m 将几个排序好的文件进行合并。
-M 将前面3个字母依照月份的缩写进行排序。
-n 依照数值的大小排序。
-u 意味着是唯一的(unique),输出的结果是去完重了的。
-o<输出文件> 将排序后的结果存入指定的文件。
-r 以相反的顺序来排序。
-t<分隔字符> 指定排序时所用的栏位分隔字符。
+<起始栏位>-<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
--help 显示帮助。
--version 显示版本信息。
[-k field1[,field2]] 按指定的列进行排序。
补充说明:sort可针对文本文件的内容,以行为单位来排序。
(二)strace
- strace是跟踪进程执行时的系统调用和所接收的信号(即它跟踪到一个进程产生的系统调用,包括参数、返回值、执行消耗的时间)。strace最简单的用法是执行一个指定的命令(过程中,starce会记录和解析命令进程的所有系统调用及这个进程的所有的信号值),在指定命令结束后立即退出。

- 注:以上每一行都是一条系统调用,等号左边是系统调用的函数名和参数,右边是该调用的返回值。strace显示这些调用的参数并返回符号形式的值。strace从内核接收信息,而且不需要以任何特殊的方式来构建内核
(三)用系统调用实现mycp
mycp.c
#include<stdio.h>
#include<unistd.h>
#include<sys/stat.h>
#include<sys/types.h>
#include<fcntl.h>
int main(int argc,char **argv)
{
FILE *fp1;
FILE *fp2;
fp1 = fopen(argv[1],"r");
fp2 = fopen(argv[2],"w");
char ch=fgetc(fp1);
while(ch!=EOF)
{
fputc(ch,fp2);
ch=fgetc(fp1);
}
fclose(fp1);
fclose(fp2);
return 0;
}

emacs mycp.c
gcc mycp.c -o mycp
sudo mv mycp /usr/bin
mycp test1.txt test2.txt
cat test1.txt
cat test2.txt

10.27学习
一、exec


1.基础知识



2.exec1.c
#include <stdio.h>
#include <unistd.h>
int main()
{
char *arglist[3];
arglist[0] = "ls";
arglist[1] = "-l";
arglist[2] = 0 ;//NULL
printf("* * * About to exec ls -l\n");
execvp( "ls" , arglist );
printf("* * * ls is done. bye");
return 0;
}

让子进程执行ls -l
2.psh1.c
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#define MAXARGS 20
#define ARGLEN 100
int execute( char *arglist[] )
{
execvp(arglist[0], arglist);
perror("execvp failed");
exit(1);
}
char * makestring( char *buf )
{
char *cp;
buf[strlen(buf)-1] = '\0';
cp = malloc( strlen(buf)+1 );
if ( cp == NULL ){
fprintf(stderr,"no memory\n");
exit(1);
}
strcpy(cp, buf);
return cp;
}
int main()
{
char *arglist[MAXARGS+1];
int numargs;
char argbuf[ARGLEN];
numargs = 0;
while ( numargs < MAXARGS )
{
printf("Arg[%d]? ", numargs);
if ( fgets(argbuf, ARGLEN, stdin) && *argbuf != '\n' )
arglist[numargs++] = makestring(argbuf);
else
{
if ( numargs > 0 ){
arglist[numargs]=NULL;
execute( arglist );
numargs = 0;
}
}
}
return 0;
}

二、fork


(一)基础知识
fork的返回值问题:
- 在父进程中,fork返回新创建子进程的进程ID;
- 在子进程中,fork返回0;
- 如果出现错误,fork返回一个负值;
- getppid():得到一个进程的父进程的PID;
- getpid():得到当前进程的PID;
注意:在fork函数执行完毕后,如果创建新进程成功,则出现两个进程,一个是子进程,一个是父进程。在子进程中,fork函数返回0,在父进程中,fork返回新创建子进程的进程ID。我们可以通过fork返回的值来判断当前进程是子进程还是父进程。
fork是把已有的进程复制一份,当然把PCB也复制了一份,然后申请一个PID - 子进程的PID=父进程的PID+1;

(二)代码实践
1.forkdemo1.c
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
int ret_from_fork, mypid;
mypid = getpid();
printf("Before: my pid is %d\n", mypid);
ret_from_fork = fork();
sleep(1);
printf("After: my pid is %d, fork() said %d\n",
getpid(), ret_from_fork);
return 0;
}

2.forkdemo2.c
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("before:my pid is %d\n", getpid() );
fork();
fork();
printf("aftre:my pid is %d\n", getpid() );
return 0;
}

3.forkdemo3.c
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<unistd.h>
#define DELAY 10
void child_code(int delay)
{
printf("child %d here. will sleep for %d seconds\n", getpid(), delay);
sleep(delay);
printf("child done. about to exit\n");
exit(27);
}
void parent_code(int childpid)
{
int wait_rv;
int child_status;
int high_8, low_7, bit_7;
wait_rv = wait(&child_status);
printf("done waiting for %d. Wait returned: %d\n", childpid, wait_rv);
high_8 = child_status >> 8; /* 1111 1111 0000 0000 */
low_7 = child_status & 0x7F; /* 0000 0000 0111 1111 */
bit_7 = child_status & 0x80; /* 0000 0000 1000 0000 */
printf("status: exit=%d, sig=%d, core=%d\n", high_8, low_7, bit_7);
}
int main()
{
int newpid;
printf("before: mypid is %d\n", getpid());
if ( (newpid = fork()) == -1 )
perror("fork");
else if ( newpid == 0 )
child_code(DELAY);
else
parent_code(newpid);
}

4.forkdemo4.c
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
int main()
{
int fork_rv;
printf("Before: my pid is %d\n", getpid());
fork_rv = fork(); /* create new process */
if ( fork_rv == -1 ) /* check for error */
perror("fork");
else if ( fork_rv == 0 ){
printf("I am the child. my pid=%d\n", getpid());
printf("parent pid= %d, my pid=%d\n", getppid(), getpid());
exit(0);
}
else{
printf("I am the parent. my child is %d\n", fork_rv);
sleep(10);
exit(0);
}
return 0;
}

5.forkgdb.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int gi=0;
int main()
{
int li=0;
static int si=0;
int i=0;
pid_t pid = fork();
if(pid == -1){
exit(-1);
}
else if(pid == 0){
for(i=0; i<5; i++){
printf("child li:%d\n", li++);
sleep(1);
printf("child gi:%d\n", gi++);
printf("child si:%d\n", si++);
}
exit(0);
}
else{
for(i=0; i<5; i++){
printf("parent li:%d\n", li++);
printf("parent gi:%d\n", gi++);
sleep(1);
printf("parent si:%d\n", si++);
}
exit(0);
}
return 0;
}

6.waitdemo1.c
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<unistd.h>
#define DELAY 4
void child_code(int delay)
{
printf("child %d here. will sleep for %d seconds\n", getpid(), delay);
sleep(delay);
printf("child done. about to exit\n");
exit(17);
}
void parent_code(int childpid)
{
int wait_rv=0; /* return value from wait() */
wait_rv = wait(NULL);
printf("done waiting for %d. Wait returned: %d\n",
childpid, wait_rv);
}
int main()
{
int newpid;
printf("before: mypid is %d\n", getpid());
if ( (newpid = fork()) == -1 )
perror("fork");
else if ( newpid == 0 )
child_code(DELAY);
else
parent_code(newpid);
return 0;
}

7.waitdemo2.c
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<unistd.h>
#define DELAY 10
void child_code(int delay)
{
printf("child %d here. will sleep for %d seconds\n", getpid(), delay);
sleep(delay);
printf("child done. about to exit\n");
exit(27);
}
void parent_code(int childpid)
{
int wait_rv;
int child_status;
int high_8, low_7, bit_7;
wait_rv = wait(&child_status);
printf("done waiting for %d. Wait returned: %d\n", childpid, wait_rv);
high_8 = child_status >> 8; /* 1111 1111 0000 0000 */
low_7 = child_status & 0x7F; /* 0000 0000 0111 1111 */
bit_7 = child_status & 0x80; /* 0000 0000 1000 0000 */
printf("status: exit=%d, sig=%d, core=%d\n", high_8, low_7, bit_7);
}
int main()
{
int newpid;
printf("before: mypid is %d\n", getpid());
if ( (newpid = fork()) == -1 )
perror("fork");
else if ( newpid == 0 )
child_code(DELAY);
else
parent_code(newpid);
}

11.3学习
一、指针与声明


右左法则:
类型识别法:从声明符开始先尽可能从最右开始分析,然后尽可能向左分析,但不要越过外面的括号。两边都达到外围括号时,跨过括号之后重复上述做法。
这样就可以逐步把类型分析清楚。我称之为“右左右左法”,道理很简单:位于右边的()和[]具有更高优先级。
- 我们看看前面的例子:
- 第一个daytab,先往右结合,[]表明daytab是一个包含13个元素的数组,再往左看int *,说明元素的类型是int *, 所以daytab是指针数组
- 第二个daytab1 先往右结合,是右括号,然后往左结合是*,说明daytab1是指针,再往右结合[],表明这个指针指向一个包含13个元素的数组,再往左看是int,说明数组的元素类型是int,所以daytab1是数组指针
- 第三个comp,先往右结合是函数,函数参数为空,然后往左看,返回值是指向int的指针,所以comp是指针函数
- 第四个comp1,先往右结合是函数,是右括号,然后往左结合是*,说明comp1是指针,再往右结合(),所以comp1是函数指针,指向的函数参数为空,返回值类型是int
- 总结:
在解析复杂声明时:
- 数组一定要告诉它元素个数和数据类型
- 函数一定要有形参类型和返回数据类型。
- 数组指针、函数指针,*和指针名字一定要括号括起来!
(1)int (*a)[10];
整型数组指针变量(首先看括号里面,a是一个指针变量,他存放的是数组元素的地址,而数组的每个元素都是整形)
(2)int (*a[10])(int);
函数指针数组(首先a是一个数组,它的元素都是指针,指针指向一个形参为整形,返回值也为整形的函数)
(3)int *( *( *a)(int))[10];(以a为中心,层层剥开括号,从右往左看)
- a:函数指针变量,指向一个形参为整形,返回值为返回值数组指针,该指针指向一个整形指针数组。
- 阅读步骤:
- 从变量名开始 -------------------------------------------- a
- 往右看,什么也没有,碰到了),因此往左看,碰到一个* ------ 一个指针
- 跳出括号,碰到了(int) ----------------------------------- 一个带一个int参数的函数
- 向左看,发现一个* --------------------------------------- (函数)返回一个指针
- 跳出括号,向右看,碰到[10] ------------------------------ 一个10元素的数组
- 向左看,发现一个* --------------------------------------- 指针
- 向左看,发现int ----------------------------------------- int类型
(4)int *( *( *arr[5])())();
- arr:函数指针数组,该数组里的元素指向一个形参为空,返回值是一个函数指针,该指针指向一个形参为空,返回值为整形指针的函数
- 阅读步骤:
- 从变量名开始 -------------------------------------------- arr
- 往右看,发现是一个数组 ---------------------------------- 一个5元素的数组
- 向左看,发现一个* --------------------------------------- 指针
- 跳出括号,向右看,发现() -------------------------------- 不带参数的函数
- 向左看,碰到* ------------------------------------------- (函数)返回一个指针
- 跳出括号,向右发现() ------------------------------------ 不带参数的函数
- 向左,发现* --------------------------------------------- (函数)返回一个指针
- 继续向左,发现int --------------------------------------- int类型

(5)例题

1. char (*( *x())[])();
- typedef char (*funp)();
- typedef funp fparray[];
- x 可简化为:fparray *x();
- x 是一个返回值为指向 fparray 类型的指针函数
2. char (*( *x[3])())[5];
- typedef char (*funp)[5];
- typedef funp fparray();
- x 可简化为:fparray *x[3];
- x 是一个返回值为指向 fparray 类型的指针数组
二、信号处理
(一)Linux进程间通信(IPC)

Linux下的进程通信手段基本上是从UNIX平台上继承来的。
对UNIX发展做出重大贡献的两大主力AT&T的贝尔实验室及BSD。
在进程间的通信方面的侧重点有所不同,前者是对UNIX早期的进程间通信手段进行了系统的改进和扩充,形成了“system V IPC”,其通信进程主要局限在单个计算机内;后者则跳过了该限制,形成了基于套接口(socket)的进程间通信机制。而Linux POSIX IPC则把两者的优势都继承了下来。
- UNIX进程间通信(IPC)方式包括管道、FIFO以及信号。
- System V进程间通信(IPC)包括System V消息队列、System V信号量以及System V共享内存区。
- Posix 进程间通信(IPC)包括Posix消息队列、Posix信号量以及Posix共享内存区。
(二)信号
- 信号是UNIX中所使用的进程通信的一种最古老的方法。
- 信号是在软件层次上对中断机制的一种模拟,它是比较复杂的通信方式,用于通知进程有某事件发生,一个进程收到一个信号与处理器收到一个中断请求效果上可以说是一样的。
(三)Linux中的信号


我们在Linux的shell中可以通过kill –l或man 7 signal命令来查看信号的信息。
- 通过kill –l我们看到:
每个信号都有一个编号和一个宏定义名称,这些宏定义可以在 signal.h 中找到,例如其中有定义#define SIGINT 2。 - 通过man 7 signal我们可以了解到这些信号各自在什么条件下产生,默认的处理动作是什么。
- man -k ...
- grep -nr SIGINT /usr/include
(四)信号生命周期

- 信号生命周期可以分为3个重要阶段,这3个阶段由4个重要事件来刻画的:信号产生、信号在进程中注册、信号在进程中注销、执行信号处理函数。
(五)信号产生

- 用户在终端按下某些键时,终端驱动程序会发送信号给前台进程,例如 Ctrl-C 产生 SIGINT 信号。可以通过stty –a 查看终端中哪些按键组合可以产生信号
- 硬件异常产生信号,这些条件由硬件检测到并通知内核,然后内核向当前进程发送适当的信号。例如当前进程执行了除以 0 的指令,CPU 的运算单元会产生异常,内核将这个异常解释为 SIGFPE 信号发送给进程。
- 一个进程调用 kill(2)函数可以发送信号给另一个进程。也可以用 kill(1)命令发送信号给某个进程,kill(1)命令也是调用 kill(2).如kill -2 5245会给PID是5245的进程发送中断信号,导致其中断。
- 当内核检测到某种软件条件发生时也可以通过信号通知进程,例如闹钟超时产生 SIGALRM 信号。
(六)信号处理
用户程序可以告诉内核如何处理某种信号,可选的处理动作有以下三种:
- 执行该信号的默认处理动作。
- 忽略此信号。
- 提供一个信号处理函数,要求内核在处理该信号时切换到用户态执行这 个处理函数,这种方式称为捕捉(Catch)一个信号。
1.捕捉信号


示例:
#include<stdio.h>
#include<signal.h>
void f(int);
int main()
{
int i;
signal(SIGINT,f);
for(i=0;i<5;i++){
printf("hello\n");
sleep(2);
}
return 0;
}
void f(int signum)
{
printf(" OUCH!\n");
}

运行结果说明:现在在程序运行期间按CRTL+C,程序不再中断退出了,而是调用了我们定义的f函数。信号就像中断,每按一次CRTL+C就调用一次信号处理函数f。
2.忽略信号
示例:
#include<stdio.h>
#include<signal.h>
int main()
{
signal(SIGINT,SIG_IGN);
printf("You can't stop me!\n");
while(1)
{
sleep(1);
printf("HaHa\n");
}
return 0;
}

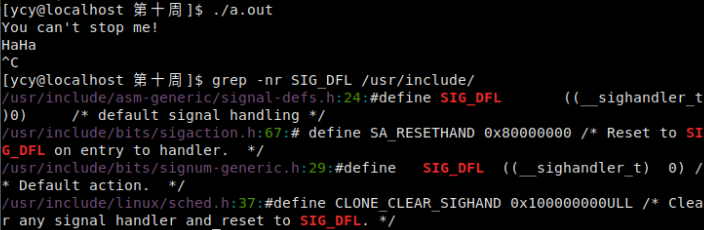
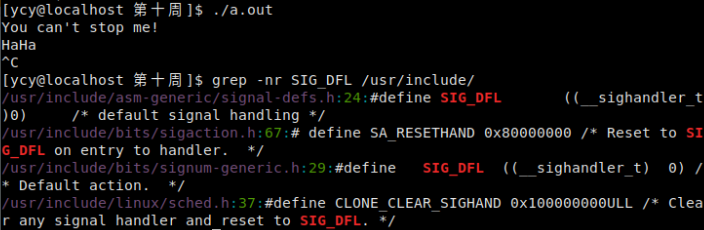
- 编译运行结果如图,在程序运行期间按CTRL+C,中断信号会被忽略。
- SIG_IGN 是什么?
grep –nr SIG_IGN /usr/include

通过grep命令我们查到,SIG_IGN其实是数字1,只是被强制转化成所需要的函数指针。
3.默认信号
示例:
#include<signal.h>
int main()
{
signal(SIGINT,SIG_DFL);
printf("You can't stop me!\n");
while(1)
{
sleep(1);
printf("HaHa\n");
}
return 0;
}

(七)多信号处理
#include<stdio.h>
#include<signal.h>
#define INPUTLEN 100
void inthandler(int s);
void quithandler(int s);
int main(int argc, char *argv[])
{
char input[INPUTLEN];
int nchars;
signal(SIGINT, inthandler); //^C
signal(SIGQUIT, quithandler); //^\
do{
printf("\nType a message\n");
nchars=read(0,input,(INPUTLEN-1));
if(nchars==-1)
perror("read returned an error");
else{
input[nchars]='\0';
printf("You typed: %s",input);
}
}while(strncmp(input,"quit",4)!=0);
return 0;
}
void inthandler(int s)
{
printf(" Received signal %d .. waiting\n",s);
sleep(2);
printf(" Leaving inthandler \n");
}
void quithandler(int s)
{
printf(" Received signal %d .. waiting\n",s);
sleep(3);
printf(" Leaving quithandler \n");
}
编译运行程序,我们依次输入^+C, ^+C, ^+, ^+, ^+C, ^+\,每次输入都等两三秒,等信号处理程序运行完毕。
查看运行结果,我们得知:如果等信号处理函数执行完毕,每次输入都会调用一次信号处理函数。

多信号处理-SIGX打断SIGX的情况
1.我们连续输入^+C , ^+C , ^+C , ^+C , ^+C

考虑一个信号还没有处理完又来了相同信号的情况。
我们通过连续输入5次^+C,不等第一次信号处理完毕来测试。
这种情况的处理方法有三种:
- 递归,调用同一个处理函数
- 忽略第二个信号
- 阻塞第二个信号直到第一个处理完毕
查看实验结果,我们得知Linux下采用第二种方式。
2.我们连续输入^+C , ^+\ , ^+C , ^+\

考虑一个信号还没有处理完又来了不同信号的情况。
我们通过连续输入^+C , ^+\ , ^+C , ^+\ ,不等前面信号处理完毕来测试。
查看实验结果,我们得知Linux下在一个信号没处理完的情况下,来了不同的信号,会优先处理后来的信号。
(八)sigaction
通过man 2 sigaction 查看帮助文档,我们看到sigaction主要使用了一个sigaction的结构体。

1.信号处理流程

使用sigaction时流程如图:先定义信号集合,再设置信号屏蔽位,然后定义信号处理函数,最后可以测试信号
2.示例
#include<stdio.h>
#include<unistd.h>
#include<signal.h>
#define INPUTLEN 100
void inthandler(int s);
int main(int argc, char *argv[])
{
struct sigaction newhandler;
sigset_t blocked;
char x[INPUTLEN];
newhandler.sa_handler=inthandler;
newhandler.sa_flags=SA_RESTART|SA_NODEFER;// |SA_RESETHAND
sigemptyset(&blocked);
sigaddset(&blocked,SIGQUIT);
newhandler.sa_mask=blocked;
if(sigaction(SIGINT,&newhandler,NULL)==-1)
perror("sigaction");
else
while(1){
fgets(x,INPUTLEN,stdin);
printf("input: %s",x);
}
return 0;
}
void inthandler(int s)
{
printf(" Called with signal %d\n",s);
sleep(s*4);
printf("done handling signal\n");
}


三、Linux进程间通信(一)——管道
(一)管道概述

管道是Linux中进程间通信的一种方式。这里所说的管道主要指无名管道,它具有以下特点:
- 它只能用于具有亲缘关系的进程之间的通信(也就是父子进程或者兄弟进程之间)。
- 它是一个半双工的通信模式,具有固定的读端和写端。需要双方通信时,需要建立起两个管道。
- 管道也可以看成是一种特殊的文件,对于它的读写也可以使用普通的read()和write()等函数。但是它不是普通的文件,并不属于其他任何文件系统,并且只存在于内核的内存空间中。
- 数据的读出和写入:一个进程向管道中写的内容被管道另一端的进程读出。写入的内容每次都添加在管道缓冲区的末尾,并且每次都是从缓冲区的头部读出数据。
(二)管道系统调用


我们再使用 man 2 pipe 查看函数的详细信息。我们注意到,为pipe函数传的参数为两个文件描述符。
管道是基于文件描述符的通信方式,当一个管道建立时,它会创建两个文件描述符fds[0]和fds[1],其中fds[0]固定用于读管道,而fd[1]固定用于写管道,这样就构成了一个半双工的通道。
管道关闭时只需将这两个文件描述符关闭即可,可使用普通的close()函数逐个关闭各个文件描述符。
- 注意:当一个管道共享多对文件描述符时,若将其中一对读写文件描述符都删除,则该管道就失效。

一般情况下使用管道时,先创建一个管道,再通过fork()函数创建一子进程,该子进程会继承父进程所创建的管道。为了实现父子进程之间的读写,只需把无关的读端或写端的文件描述符关闭即可。例如在下图中将父进程的写端fd[1]和子进程的读端fd[0]关闭。此时,父子进程之间就建立起了一条“子进程写入父进程读取”的通道。
同样,也可以关闭父进程的fd[0]和子进程的fd[1],这样就可以建立一条“父进程写入子进程读取”的通道。另外,父进程还可以创建多个子进程,各个子进程都继承了相应的fd[0]和fd[1],这时,只需要关闭相应端口就可以建立其各子进程之间的通道。
测试代码
/* pipe.c */
#include <unistd.h>
#include <sys/types.h>
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_DATA_LEN 256
#define DELAY_TIME 1
int main()
{
pid_t pid;
int pipe_fd[2];
char buf[MAX_DATA_LEN];
const char data[] = "Pipe Test Program";
int real_read, real_write;
memset((void*)buf, 0, sizeof(buf));
/* 创建管道 */
if (pipe(pipe_fd) < 0)
{
printf("pipe create error\n");
exit(1);
}
/* 创建一子进程 */
if ((pid = fork()) == 0)
{
/* 子进程关闭写描述符,并通过使子进程暂停1秒等待父进程已关闭相应的读描述符 */
close(pipe_fd[1]);
sleep(DELAY_TIME * 3);
/* 子进程读取管道内容 */
if ((real_read = read(pipe_fd[0], buf, MAX_DATA_LEN)) > 0)
{
printf("%d bytes read from the pipe is '%s'\n", real_read, buf);
}
/* 关闭子进程读描述符 */
close(pipe_fd[0]);
exit(0);
}
else if (pid > 0)
{
/* 父进程关闭读描述符,并通过使父进程暂停1秒等待子进程已关闭相应的写描述符 */
close(pipe_fd[0]);
sleep(DELAY_TIME);
/* 父进程向管道中写入字符串 */
if((real_write = write(pipe_fd[1], data, strlen((const char*)data))) != -1)
{
printf("Parent wrote %d bytes : '%s'\n", real_write, data);
}
/*关闭父进程写描述符*/
close(pipe_fd[1]);
/*收集子进程退出信息*/
waitpid(pid, NULL, 0);
exit(0);
}
}

在上面的测试代码中,首先创建管道,之后父进程使用fork()函数创建子进程,之后通过关闭父进程的读描述符和子进程的写描述符,建立起父子进程之间的管道通信。
(三)标准流管道
与Linux的文件操作中有基于文件流的标准I/O操作一样,管道的操作也支持基于文件流的模式。这种基于文件流的管道主要是用来创建一个连接到另一个进程的管道,这里的“另一个进程”也就是一个可以进行一定操作的可执行文件,例如,用户执行“ls -l”或者自己编写的程序“./pipe”等。由于这一类操作很常用,因此标准流管道就将一系列的创建过程合并到一个函数popen()中完成。它所完成的工作有以下几步。
- 创建一个管道
- fork()一个子进程
- 在父子进程中关闭不需要的文件描述符
- 执行exec函数族调用
- 执行函数中所指定的命令

使用man 3 popen查看函数的详细使用方法,其中, - command:指向的是一个以null 结束符结束的字符串,这个字符串包含一个shell命令,由shell来执行;
- type:“r”:文件指针连接到command 的标准输出,即该命令的结果产生输出
“w”:文件指针连接到command 的标准输入,即该命令的结果产生输入
与之相对应,关闭用popen()创建的流管道必须使用函数pclose()来关闭该管道流。该函数关闭标准I/O流,并等待命令执行结束。
使用popen()来执行“ps -ef”命令
/* standard_pipe.c */
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <fcntl.h>
#define BUFSIZE 1024
int main()
{
FILE *fp;
char *cmd = "ps -ef";
char buf[BUFSIZE];
/*调用popen函数执行相应的命令*/
if ((fp = popen(cmd, "r")) == NULL)
{
printf("Popen error\n");
exit(1);
}
while ((fgets(buf, BUFSIZE, fp)) != NULL)
{
printf("%s",buf);
}
pclose(fp);
exit(0);
}

上面的程序使用popen()来执行“ps -ef”命令,可以看出popen()函数使程序变得短小精悍
- 优点:减少代码编写量
- 缺点:用popen()创建的管道必须使用标准I/O函数进行操作,但不能使用前read()、write()一类不带缓冲的I/O函数。
(四)小结
管道的主要局限性正体现在它的特点上:
- 只支持单向数据流;
- 只能用于具有亲缘关系的进程之间;
- 没有名字,不方便操作;
- 管道的缓冲区是有限的(管道制存在于内存中,在管道创建时,为缓冲区分配一个页面大小)。
四、Linux进程间通信(二)——有名管道
(一)有名管道概述
1.回顾:管道(pipe)的局限性
- 只支持单向数据流;
- 只能用于具有亲缘关系的进程之间;
- 没有名字,不方便操作;
- 管道的缓冲区是有限的。
2.在有名管道(named pipe或FIFO)提出后,该限制得到了克服。
- FIFO不同于管道之处在于它提供一个路径名与之关联,以FIFO的文件形式存在于文件系统中。这样,即使与FIFO的创建进程不存在亲缘关系的进程,只要可以访问该路径,就能够彼此通过FIFO相互通信。因此,通过FIFO不相关的进程也能交换数据。
FIFO类似于放在草坪上的一根塑料水管,任何人都可以将此水管的一段放在耳边,而另一个人通过水管向对方说话。而当没有人使用的时候,水管仍然存在。FIFO可以看做由文件名标志的一根水管。 - 值得注意的是,FIFO严格遵循先进先出(first in first out),对管道及FIFO的读总是从开始处返回数据,对它们的写则把数据添加到末尾。
- 它们不支持诸如lseek()等文件定位操作。
(二)有名管道的相关操作

与有名管道相关的函数有哪些呢?我们根据“有名”(named)和“管道”(pipe)这两个关键字进行搜索,得到了图中的结果。顾名思义,mkfifo是我们需要的“创建FIFO”的函数

使用man 3 mkfifo查看函数的详细信息。mkfifo函数传入值有两个:filename和mode

其中,filename是要创建的管道,mode是管道类型
创建成功后,使用open()、read()和write()函数
- 为读而打开的管道:在open()中设置O_RDONLY;
- 为写而打开的管道:在open()中设置O_WDONLY;
- 非阻塞打开:在open()中设定为O_NONBLOCK
1.读进程
- 若该管道是阻塞打开,且当前FIFO 内没有数据,则对读进程而言将一直阻塞到有数据写入。
- 若该管道是非阻塞打开,则不论FIFO 内是否有数据,读进程都会立即执行读操作。即如果FIFO内没有数据,则读函数将立刻返回0。
2.写进程
- 若该管道是阻塞打开,则写操作将一直阻塞到数据可以被写入。
- 若该管道是非阻塞打开而不能写入全部数据,则读操作进行部分写入或者调用失败。
示例
/* fifo_read.c */
#include <sys/types.h>
#include <sys/stat.h>
#include <errno.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <limits.h>
#define MYFIFO "/tmp/myfifo"
#define MAX_BUFFER_SIZE PIPE_BUF /*定义在于limits.h中*/
int main()
{
char buff[MAX_BUFFER_SIZE];
int fd;
int nread;
/* 判断有名管道是否已存在,若尚未创建,则以相应的权限创建*/
if (access(MYFIFO, F_OK) == -1)
{
if ((mkfifo(MYFIFO, 0666) < 0) && (errno != EEXIST))
{
printf("Cannot create fifo file\n");
exit(1);
}
}
/* 以只读阻塞方式打开有名管道 */
fd = open(MYFIFO, O_RDONLY);
if (fd == -1)
{
printf("Open fifo file error\n");
exit(1);
}
while (1)
{
memset(buff, 0, sizeof(buff));
if ((nread = read(fd, buff, MAX_BUFFER_SIZE)) > 0)
{
printf("Read '%s' from FIFO\n", buff);
}
}
close(fd);
exit(0);
}
/* fifo_write.c */
#include <sys/types.h>
#include <sys/stat.h>
#include <errno.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <limits.h>
#define MYFIFO "/tmp/myfifo" /* 有名管道文件名*/
#define MAX_BUFFER_SIZE PIPE_BUF /*定义在于limits.h中*/
int main(int argc, char * argv[]) /*参数为即将写入的字符串*/
{
int fd;
char buff[MAX_BUFFER_SIZE];
int nwrite;
if(argc <= 1)
{
printf("Usage: ./fifo_write string\n");
exit(1);
}
sscanf(argv[1], "%s", buff);
/* 以只写阻塞方式打开FIFO管道 */
fd = open(MYFIFO, O_WRONLY);
if (fd == -1)
{
printf("Open fifo file error\n");
exit(1);
}
/*向管道中写入字符串*/
if ((nwrite = write(fd, buff, MAX_BUFFER_SIZE)) > 0)
{
printf("Write '%s' to FIFO\n", buff);
}
close(fd);
exit(0);
}
该实例包含了两个程序,一个用于读管道,另一个用于写管道。其中在读管道的程序里创建管道,并且作为main()函数里的参数由用户输入要写入的内容。读管道的程序会读出用户写入到管道的内容,这两个程序采用的是阻塞式读写管道模式。

为了能够较好地观察运行结果,需要把这两个程序分别在两个终端里运行,在这里首先启动读管道程序。读管道进程在建立管道之后就开始循环地从管道里读出内容,如果没有数据可读,则一直阻塞到写管道进程向管道写入数据。在启动了写管道程序后,读进程能够从管道里读出用户的输入内容.
(三)小结
- 管道常用于两个方面:(1)在shell中时常会用到管道(作为输入输入的重定向),在这种应用方式下,管道的创建对于用户来说是透明的;(2)用于具有亲缘关系的进程间通信,用户自己创建管道,并完成读写操作。
- FIFO可以说是管道的推广,克服了管道无名字的限制,使得无亲缘关系的进程同样可以采用先进先出的通信机制进行通信:(1)提供一个路径名与之关联;(2)严格遵循先进先出(first in first out) 。
- 管道和FIFO的数据是字节流,应用程序之间必须事先确定特定的传输"协议",采用传播具有特定意义的消息。
- 要灵活应用管道及FIFO,理解它们的读写规则是关键。
五、Linux进程间通信(三)——信号量
(一)信号量概述
1.多任务操作系统环境——多进程
- 同步关系:多进程为了完成同一个任务相互协作
- 互斥关系:不同进程为了争夺有限的系统资源,进入竞争状态
2.进程之间的互斥与同步关系存在的根源在于临界资源
- 临界资源是在同一个时刻只允许有限个(通常只有一个)进程可以访问(读)或修改(写)的资源;
- 访问临界资源的代码叫做临界区,临界区本身也会成为临界资源。
3.信号量——解决进程之间的同步与互斥问题
- 称为信号量的变量
- 在该信号量下等待资源的进程等待队列
- 对信号量进行的两个原子操作(PV操作)
4.PV原子操作的具体定义如下:
- P 操作:如果有可用的资源(信号量值>0),则占用一个资源(信号量值-1,进入临界区代码);如果没有可用的资源(信号量值等于0),则被阻塞,直到系统将资源分配给该进程(进入等待队列,一直等到资源轮到该进程);
- V 操作:如果在该信号量的等待队列中有进程在等待资源,则唤醒一个阻塞进程。如果没有进程等待它,则释放一个资源(信号量值+1)。
- (最简单的信号量是只能取0和1两种值,这种信号量被叫做二维信号量。在这里,我们主要讨论二维信号量。)
(二)信号量的应用
1.man –k semaphore

使用“man -k”搜索与“信号量”(semaphore)相关的函数。我们注意到semget函数的描述:获取系统V信号量集标识符,在对信号量操作之前,“获取”信号量似乎是我们想要的。
2.man 2 semget

查看semget函数,我们来对函数传入值稍作分析:
- key:信号量的键值,多个进程可以通过它访问同一个信号量,其中有个特殊值IPC_PRIVATE。它用于创建当前进程的私有信号量。
- nsems:需要创建的信号量数目,通常取值为1。
- semflg:同open()函数的权限位,也可以用八进制表示法,其中使用IPC_CREAT 标志创建新的信号量,即使该信号量已经存在(具有同一个键值的信号量已在系统中存在),也不会出错。如果同时使用IPC_EXCL 标志可以创建一个新的唯一的信号量,此时如果该信号量已经存在,该函数会返回出错。
“SEE ALSO”部分:

我们在semget函数的“see also”部分可以查阅与之相关的其他函数
3.信号量的使用步骤
- 创建信号量或获得在系统已存在的信号量,此时需要调用semget()函数。不同进程通过使用同一个信号量键值来获得同一个信号量。
- 初始化信号量,此时使用semctl()函数的SETVAL操作。当使用二维信号量时,通常将信号量初始化为1。
- 进行信号量的PV 操作,此时调用semop()函数。这一步是实现进程之间的同步和互斥的核心工作部分。
- 如果不需要信号量,则从系统中删除它,此时使用semclt()函数的IPC_RMID 操作。此时需要注意,在程序中不应该出现对已经被删除的信号量的操作。
12.1学习——嵌入式C语言
一、程序设计风格
- 标识符与命名
- 保持一致性
- 准确
- 为魔数命名
- 缩行显示程序结构
1.使用括号排除二义性
- ? if(x&mask == BITS)
- if ( (x&mask) == BITS)
2.使用表达式的自然形式
- ? If (!(a<b) || !(c<d))
- if ((a>=b) || (c>=d))
3.当心副作用
- ? str[i++] = str[i++] = ‘ ’;
- str[i++] = ‘ ’; str[i++] = ‘ ’


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 推荐几款开源且免费的 .NET MAUI 组件库
· 实操Deepseek接入个人知识库
· 易语言 —— 开山篇
· Trae初体验