
201971010245-王亚亚 实验三 结对项目—《{0-1}KP 实例数据集算法实验平台》项目报告
| 项目 | 内容 |
|---|---|
| 课程班级博客链接 | https://edu.cnblogs.com/campus/xbsf/2019nwnucs |
| 这个作业要求链接 | https://edu.cnblogs.com/campus/xbsf/2019nwnucs/homework/12560 |
| 我的课程学习目标 | 1. 体验软件项目开发中的两人合作,练习结对编程 2. 掌握Github协作开发程序的操作方法。 3.阅读《现代软件工程—构建之法》学习代码规范等知识 4. 学习遗传算法并进行问题求解。 |
| 这个作业在哪些方面帮助我实现学习目标 | 1.熟悉了软件工程结对编程 2.掌握Github克隆结对方项目 3.学习了代码风格规范、代码设计规范、代码复审等知识 |
| 结对方学号-姓名 | 201971010242-王凯英 |
| 结对方本次博客作业链接 | https://www.cnblogs.com/201971010242wang/p/16043089.html |
| 本项目Github的仓库链接地址 | https://github.com/201971010245/-0-1-kp |
1. 实验目的与要求
(1)体验软件项目开发中的两人合作,练习结对编程(Pair programming)。
(2)掌握Github协作开发软件的操作方法。
2. 实验内容和步骤
任务1:阅读《现代软件工程—构建之法》第3-4章内容,理解并掌握代码风格规范、代码设计规范、代码复审、结对编程概念;
1.代码风格规范:
代码风格规范包括命名规范,代码展示风格的规范(缩进、空格、换行),控制语句的规范以及代码注释的规范,好的代码风格规范可以让其他人更好的理解。它的原则是:简明,易读,无二义性。
- 四个空格的缩进
- 每个{}独占一行
- 不要把多个变量定义在一行上
- 一个类型的成员变量用同一类型命名
- 所有的类型/类/函数名
- 注释是为了解释程序做什么(What),为什么这么做(Why),以及要特别注意的地方,只用ASCII字符,不要用中文
2.代码设计规范:
- 函数:只做一件事,并且要做好
- 单一出口
- 不要在构造函数中做复杂的操作,简单初始化所有的数据成员即可
3.代码复审:
看代码是否在代码规范的框架内正确地解决了问题、长远的问题;
- 修改之后,有没有别的功能会受影响;
- 项目中还有别的地方需要类似的修改吗;
- 有没有留下足够的说明,让将来维护代码时不会出现问题;
- 对于修改,是否需要告知成员;
- 导致问题的根本原因是什么?以后如何能自动避免这样的情况再次出现。
结对编程
结对编程是一种敏捷软件开发的方法,两个程序员在一个计算机上共同工作。一个人输入代码,而另一个人审查他输入的每一行代码。输入代码的人称作驾驶员,审查代码的人称作观察员。两个程序员经常互换角色。
在结对编程中,观察员同时考虑工作的战略性方向,提出改进的意见,或将来可能出现的问题以便处理。这样使得驾驶者可以集中全部注意力在完成当前任务的“战术”方面。观察员当作安全网和指南。结对编程对开发程序有很多好处。比如增加纪律性,写出更好的代码等。
结对编程是极端编程的组成部分。
任务2:两两自由结对,对结对方《实验二 软件工程个人项目》的项目成果进行评价,具体要求如下:
(1)对项目博文作业进行阅读并进行评论,评论要点包括:博文结构、博文内容、博文结构与PSP中“任务内容”列的关系、PSP中“计划共完成需要的时间”与“实际完成需要的时间”两列数据的差异化分析与原因探究,将以上评论内容发布到博客评论区。
结对方博客链接:王凯英的博客
结对方Github项目仓库链接:王凯英Github项目仓库链接
博客评论:

(2)克隆结对方项目源码到本地机器,阅读并测试运行代码,参照《现代软件工程—构建之法》4.4.3节核查表复审同伴项目代码并记录。
- 克隆对方代码到本地机器
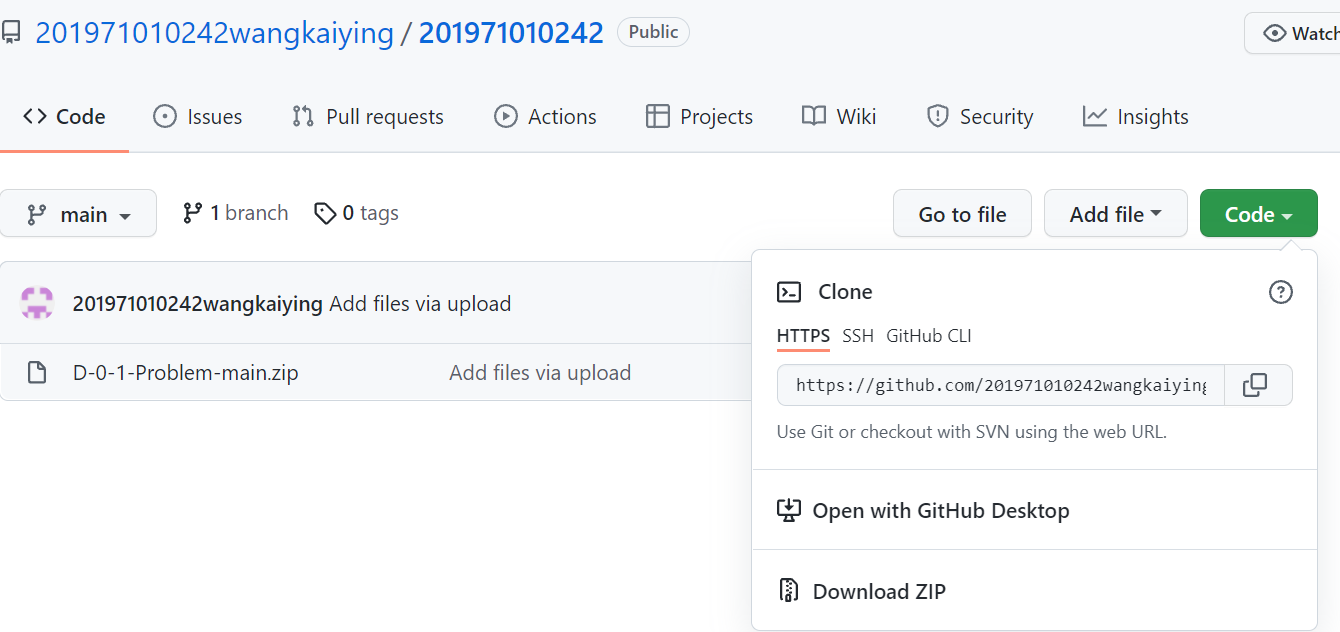
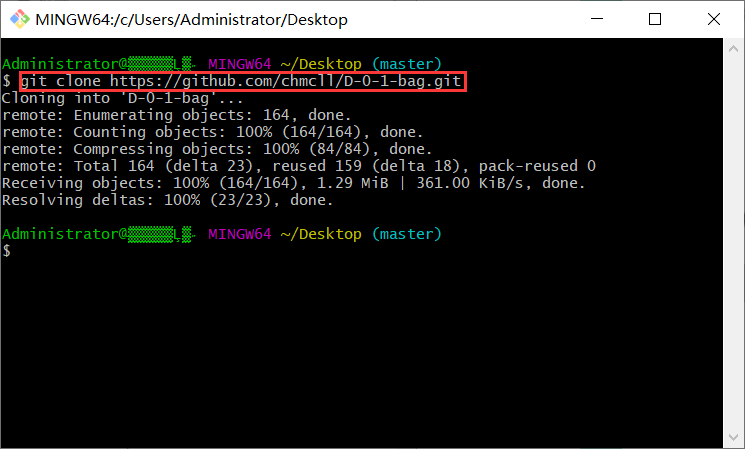
- 代码核查表
| 内容 | 完成效果 |
|---|---|
| 是否可正确读入实验数据文件的有效D{0-1}KP数据 | 代码实现了从本地读取数据,符合需求且比较容易维护 |
| 是否能够绘制任意一组D{0-1}KP数据以重量为横轴、价值为纵轴的数据散点图 | 可根据读入的不同数据准确绘制以重量为横轴、价值为纵轴的数据散点图,符合实验要求。 |
| 是否对一组D{0-1}KP数据按项集第三项的价值:重量比进行非递增排序 | 对不同的数据可以进行选择并对其进行能够对一组D{0-1}KP数据按项集第三项的价值:重量比进行非递增排序;但相关部分代码可读性较差,存在较多问题。 |
| 是否自主选择动态规划算法、回溯算法求解指定D{0-1} KP数据的最优解和求解时间 | 代码中选择动态规划算法任意选择一组数据并求解了这组数据的最优解和求解时间,求解时间也是按照以秒为单位,符合实验要求 |
| 是否将任意一组D{0-1} KP数据的最优解、求解时间和解向量可保存为txt文件或导出EXCEL文件。 | 完成了任意一组D{0-1} KP数据的最优解、求解时间和解向量可保存为txt文件或导出EXCEL文件保存在本地。 |
| 代码规范 | 项目中大部分代码是符合代码标准和风格的,但对于返回函数没有进行检查 |
| 代码可读性 | 代码可读性较强,在有些较难理解部分进行了详细的注释使得程序的可读性增强。 |
1)概要部分
a.代码符合需求和规格说明
b.代码设计没有考虑周全,有很多代码使用的很不合适。
c.代码可读性还性吧,不过有的还存在很多问题。
d.代码比较容易维护。
e.代码的每一行都执行了,都检查了。
2)设计规范部分
a.代码遵循了已知的设计模式和在项目中的常用模式, 学习了很多知识。
b.我代码设计中有字符串和数字的存在。
c.程序代码没有依赖于某一平台,从Win32移植到Win64上没有出现很大的问题。
d.在本程序中类似的功能差不多都可以调用而不用全部重新来实现。
e.有无用的代码可以删除,在我的抽签程序中,我对于按组抽签中的添加人员姓名进行了编码,实际上是不需要的,因为一个学号就做够啦,而且还有窗体控件的功能实现。
3)代码规范部分
a.修改的部分有很多地方是符合代码标准和风格的,但是有也有代码是没有符合标准和风格的。
4)具体代码部分
a.在抽签程序中对错误进行了处理,在实现号码滚动的代码上出现了错误,只能实现代码中的数字,而不能随机的进行输入数字。对于调用的外部函数,检查了返回值。
b.参数传递无错误,字符串的长度是字节的长度,是双字节,是以1开始计数
c.Switch语句的用的很好,没有出现死循环
d.没有使用断言(Assert)来保证我们认为不变的条件真的满足
f.对资源的利用,是在C#书上借鉴的,内存、文件、各种GUI资源、数据库访问的连接没有可能导致资源泄露,有可能优化
e.数据结构中有很的元素是没有用到的。
5)效能
a.代码中,特别是循环中没有明显可优化的部分。
b.对于系统和网络调用会超时,可以等待一会。
6)可读性
代码可读性很易懂,没有足够的注释,代码量很少。
7) 可测试性
a.代码需要更新和创建新的单元测试。
b.可以针对部分功能的实现对代码进行进一步改进或创建新的单元测试。
(3)依据复审结果尝试利用github的Fork、Clone、Push、Pull request、Merge pull request等操作对同伴个人项目仓库的源码进行合作修改。
fork:从别人发布的项目上复制一个过来,相当于一个分支;项目复制到自己的个github中,于是本地就有了一个仓库,假设名字为A;
clone: 从自己的github上把fork过来的复制到本地,这样本地就有了一个项目A1;
push:当你在A1中进行修改进行开发后,最后同步到你的github上的仓库中;
pull request:你把自己github中的已经修改的内容申请同步到最初那个开发者的项目中。
克隆到本地
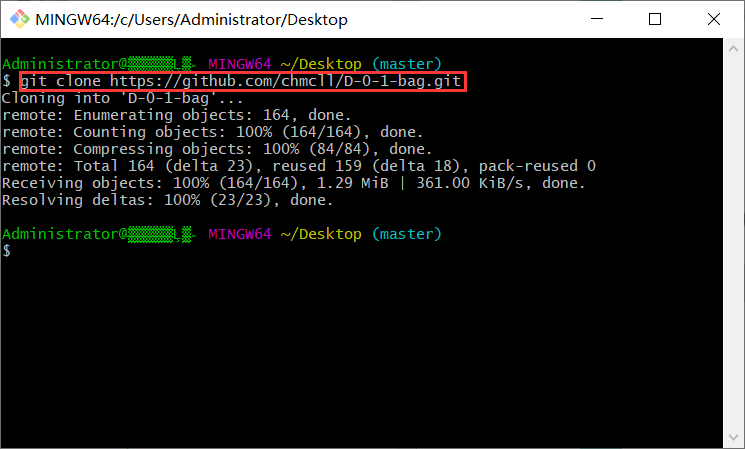
关联原始仓库
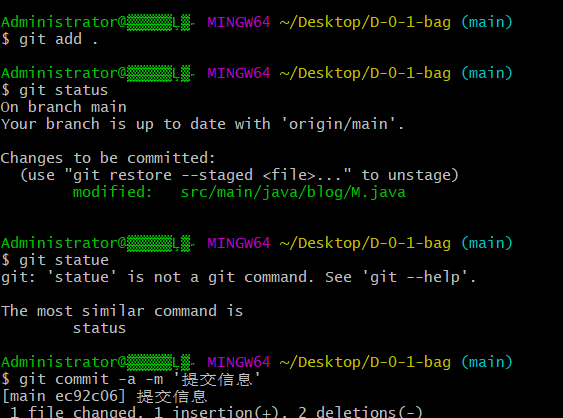
PUSH
任务3:两两采用两人结对编程方式,设计开发一款D{0-1}KP 实例数据集算法实验平台,使之具有以下功能:
一、需求分析
从若干具有价值系数与重量系数的物品(或项)中,选择若干个装入一个具有载重限制的背包,并使装入物品的重量系数之和在不超过背包载重前提下价值系数之和达到最大。

二、功能分析
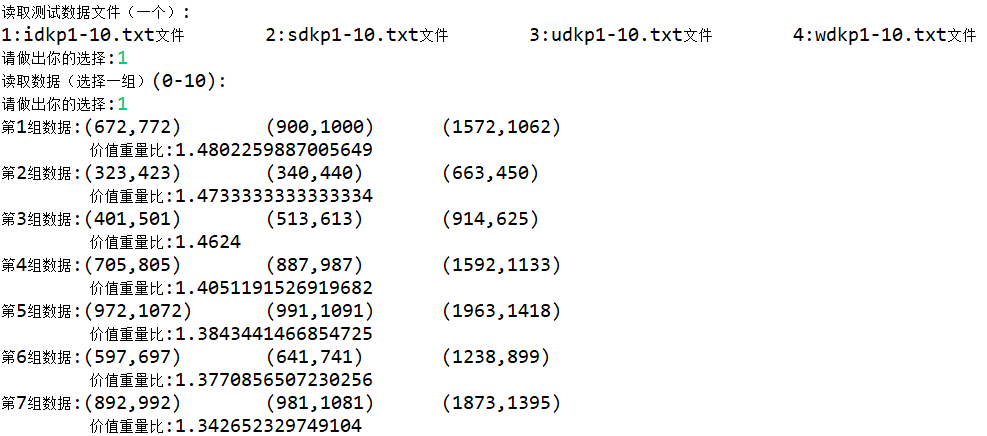
1、可读取实验数据,有效呈现所有数据;
2、用读取的数据绘制出以重量为横轴、价值为纵轴的数据散点图;
3、将数据按项集第三项的价值:重量比进行非递增排序;
4、用户能够自主选择动态规划算法、回溯算法求解数据的最优解和求解时间;
5、数据的最优解、求解时间和解向量可保存为txt文件
三、软件设计
1、D{0-1}KP 实例数据集需存储在数据库;
2、平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据;
3、人机交互界面要求为GUI界面;
4、查阅资料,设计遗传算法求解D{0-1}KP,并利用此算法测试要求(3);
在实验过程中,此次实验要求的技术与我在此之前的掌握的技术有一定差距。所以我复习了大学三年级第一学期在《算法设计与分析》课程中学习到的动态规划算法与回溯算法求解0/1背包问题的内容,循序渐进,推进实验的进程。
1、动态规划算法
动态规划算法的核心思想是:
将大问题划分为小问题进行解决,从而一步一步获得最优解的处理算法。
动态规划算法与分治算法类似,其基本思想也是将代求问题分解成若干子问题,先求解子问题,然后从这些子问题的解得到原问题的解。
与分治算法不同的是,适合于动态规划求解的问题,经分解得到的子问题往往不是互相独立的,即下一个子阶段的求解过程是建立在上一个子阶段的解的基础上,进行进一步的求解。
2、回溯算法
顾名思义,回溯法一个很显著的特征就是回溯,即在处理完某种情况或出现不能继续进行的情况时,要退回到之前的某个“交叉口”,处理另一种可能。
回溯法是一种非常有效的方法,有“通用的解题法”之称。它有点像穷举法,但是更带有跳跃性和系统性,他可以系统性的搜索一个问题的所有的解和任一解。回溯法采用的是深度优先策略。通常,回溯法会定义一个解空间,这个解空间通常是以图或树的形式呈现出来的。背包问题的解空间是树的形式,属于深度优先搜索。
回溯法在确定了解空间的结构后,从根结点出发,以深度优先的方式搜索整个解空间,此时根结点成为一个活结点,并且成为当前的扩展结点。每次都从扩展结点向纵向搜索新的结点,当算法搜索到了解空间的任一结点,先判断该结点是否肯定不包含问题的解(是否还能或者还有必要继续往下搜索),如果确定不包含问题的解,就逐层回溯;否则,进入子树,继续按照深度优先的策略进行搜索。当回溯到根结点时,说明搜索结束了,此时已经得到了一系列的解,根据需要选择其中的一个或者多个解即可。
回溯法解决问题一般分为三个步骤:
(1)针对所给问题,定义问题的解空间;
(2)确定易于搜索的解空间结构;
(3)以深度优先的方式搜索解空间
软件实现及核心功能代码展示
软件包括哪些类,这些类分别负责什么功能,他们之间的关系怎样?类内有哪些重要的方法,关键的方法是否需要画出流程图?
项目文件夹基本部分注释:

代码展示:
for(int i=1;i<row;i++) {
String Row=Integer.toString(i);
for(int j=1;j<4;j++) {
String Weight=Integer.toString(weight[i][j]);
String Value=Integer.toString(value[i][j]);
String addsql="INSERT INTO table_kp01(tempname,weight,value) VALUES(?,?,?)";
PreparedStatement pst=null;
pst=conn.prepareStatement(addsql);//预编译SQL
pst.setString(1, Row);
pst.setString(2, Weight);
pst.setString(3, Value);
pst.executeUpdate();//执行SQl语句
}
}
(3)平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据;
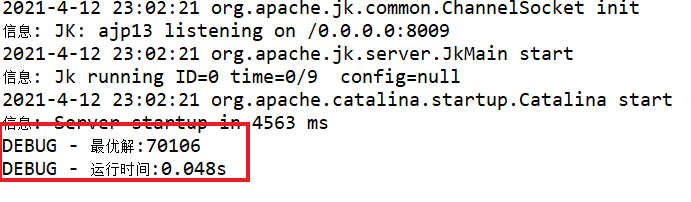
调用算法结果展示:

算法实验日志数据结果展示:
算法实验日志数据部分代码:
<%@page import="org.apache.log4j.Logger" %>
private static Logger log1=Logger.getLogger(RES);
private static Logger log2=Logger.getLogger(RUN_TIME);
log1.debug("最优解:"+res);
out.println("</br>");//换行标签
log2.debug("运行时间:"+run_time+"s");
遗传算法概述:
遗传算法(Genetic Algorithm,GA)是进化计算的一部分,是模拟达尔文的遗传选择和自然淘汰的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。该算法简单、通用,鲁棒性强,适于并行处理。
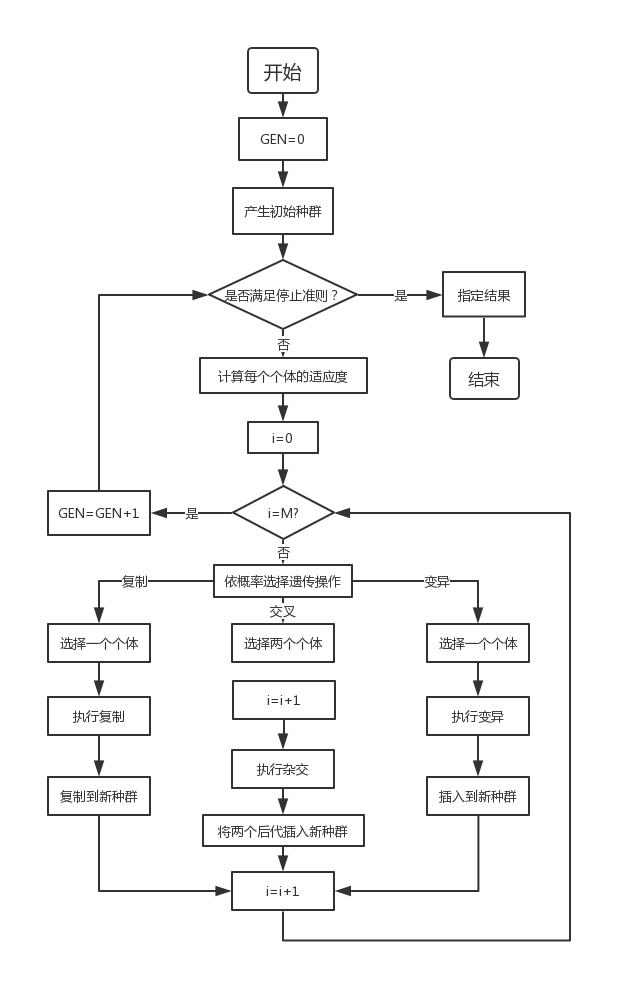
遗传算法的基本流程
通过随机方式产生若干由确定长度(长度与待求解问题的精度有关)编码的初始群体;
通过适应度函数对每个个体进行评价,选择适应度值高的个体参与遗传操作,适应度低的个体被淘汰;
经遗传操作(复制、交叉、变异)的个体集合形成新一代种群,直到满足停止准则(进化代数GEN>=?);
将后代中变现最好的个体作为遗传算法的执行结果。
其中,GEN是当前代数;M是种群规模,i代表种群数量。
此次结对作业的PSP
| 任务内容 | 计划共完成需要的时间/分钟 | 实际完成需要的时间/分钟 |
|---|---|---|
| 计划总时长 | 1180 | 2050 |
| 任务一 | 50 | 55 |
| 阅读《现代软件工程—构建之法》第3-4章 | 50 | 55 |
| 任务二 | 320 | 400 |
| 对项目博文作业进行阅读并进行评论 | 20 | 20 |
| 克隆结对方项目源码到本地机器,阅读并测试运行代码 | 100 | 120 |
| 依据复审结果用github的Fork、Clone、Push等操作对同伴个人项目仓库的源码进行合作修改 | 200 | 260 |
| 任务3 | 810 | 1595 |
| D{0-1}KP 实例数据集存储在数据库 | 40 | 60 |
| 将数据库数据读取出来 | 40 | 70 |
| 用读出来的数据绘制散点图并显示在人机交互页面 | 60 | 270 |
| 动态规划算法结果显示在前端 | 60 | 120 |
| 回溯算法结果显示 | 40 | 75 |
| 将数据项显示在前端,按其第三项进行排序并显示 | 80 | 100 |
| 平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据 | 250 | 400 |
| 人机交互界面要求为GUI界面 | 40 | 50 |
| 查阅资料,设计遗传算法求解D{0-1}KP,并利用此算法测试要求 | 200 | 450 |
此次项目总结
这次的实验我们尝试了结对编程,通过结对编程我们可以一起去交流学习。结对编程的效果是真的挺大的,通过结对编程我们共同合作,能够想到一些对方没有考虑地方,可以分享知识、共同解决遇到的问题。两个人合作完成一个项目,要比起自己单独去完成效果好很多,不仅会减轻双方的工作量,还可以在合作中最大化发挥自己的优点,同时也可以从对方身上学到很多自己不擅长的技术,互相弥补,共同进步。而且通过这次的结对编程,我们学会了合作学习、交流,知道怎么团队工作。

