

201971010242-王凯英 实验三 结对项目—《{0-1}KP 实例数据集算法实验平台》项目报告
| 项目 | 内容 |
|---|---|
| 课程班级博客链接 | 班级 |
| 这个作业要求链接 | 作业 |
| 我的课程学习目标 | (1)体验软件项目开发中的两人合作,练习结对编程(Pair programming)。(2)掌握Github协作开发软件的操作方法。 |
| 这个作业在哪些方面帮助我实现学习目标 | (1)通过本次实验,首次开展软件工程结对项目,熟悉了项目制作的基本流程。(2)再次练习使用GitHub发布软件项目 |
| 结对方学号-姓名 | 201971010242-王亚亚 |
| 结对方本次博客作业链接 | 链接 |
| 本项目Github的仓库链接地址 | 仓库 |
- 任务1:阅读《现代软件工程—构建之法》第3-4章内容,理解并掌握代码风格规范、代码设计规范、代码复审、结对编程概念;
代码风格规范、代码设计规范、代码复审、结对编程概念; 代码规范: 代码设计规范,牵涉到程序设计、模块之间的关系、设计模式等方方面面的通用原则。代码设计规范: 代码设计规范不光是程序书写的格式问题,而且牵涉到程序设计、模块之间的关系、设计模式 等方方面面,这里又有不少内容与具体程序设计语言息息相关(如C、C++. Java、C#),但 是也有通用的原则,这里主要讨论通用的原则。
代码复审目的:
找出代码的错误
(1) 编码错误,比如一些碰巧骗过了编译器的错误;
(2) 不符合团队代码规范的地方。
结对编程:
在结对编程模式下,一对程序员肩并肩地、平等地、互补地进行开发工作。两个程序员并排坐在一台电脑前,面对同一个显示器,使用同一个键盘,同一个鼠标一起工作。他们一起分析,一起设计,一起写测试用例,一起编码,一起单元测试,一起集成测试,一起写文档等。
-
任务2
概要部分: -
代码符合需求和规格说明么?
答:代码符合需求和规格说明。
- 代码设计是否考虑周全
答:代码设计考虑周全。
- 代码可读性如何?
答:代码可读性较好
- 代码容易维护么?
答:代码容易维护。
- 代码的每一行都执行并检查过了吗?
答:代码的每一行都执行并检查过了。
设计规范部分:
- 设计是否遵从已知的设计模式或项目中常用的模式?
答:设计遵从已知的设计模式或项目中常用的模式。
- 有没有硬编码或字符串/数字等存在?
答:存在硬编码
- 代码有没有依赖于某一平台,是否会影响将来的移植(如Win32到Win64)?
答:代码实在win64上进行的编码,不太清楚在win32上能否运行,未进行测试。
- 有没有无用的代码可以清除?
答:基本上没有需要清除的代码。
代码规范部分:
答:修改的部分符合代码标准和风格。
具体代码部分:
- 有没有对错误进行处理?对于调用的外部函数,是否检查了返回值或处理了 异常?
答:对错误进行了处理,对于调用的外部函数,检查了返回值或处理了异常。
- 数据结构中有没有用不到的元素?
答:数据结构中没有用不到的元素。
效能:
- 代码中,特别是循环中是否有明显可优化的部分?
答:代码中,特别是循环中没有明显可优化的部分。
- 可读性:
答:代码没有足够的注释,注释很少,代码可读性不是很好。
- 可测试性:
答:代码是不需要更新或创建新的单元测试。
第五步:结对方项目仓库中的Fork、Clone、Push、Pull request、Merge pull request日志数据:
- Fork:
将结对方的项目复制过来,相当于一个分支;项目复制到自己的github中,于是本地就有了和结对方相同命名的仓库。
- Clone:
从自己的github上把fork过来的复制到本地,这样本地就有了结对方的项目。
- Push:
在本地项目进行修改开发后,最后同步到我的github上的仓库中。
- Pull request:
把自己github中的已经修改的内容申请同步到最初那个开发者的项目中并作出比较。由于在push阶段对结对方的代码未作出修改(个人觉得结对方代码无需修改),所以比较结果是两个项目并无差异。
- 任务三
采用两人结对编程方式,设计开发一款D{0-1}KP 实例数据集算法实验平台,使之具有以下功能:
(1)平台基础功能:实验二 任务3;
(2)D{0-1}KP 实例数据集需存储在数据库;
(3)平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据;
(4)人机交互界面要求为GUI界面(WEB页面、APP页面都可);
(5)查阅资料,设计遗传算法求解D{0-1}KP,并利用此算法测试要求(3);
(6)附加功能:除(1)-(5)外的任意有效平台功能实现。
一、需求分析
-
折扣0/1背包问题,动态规划算法,回溯算法;
-
从定的文件中读取出正确的数据并保存;
-
读取数据并对数据进行处理,需要用到数据的切片技术;
-
绘制数据散点图要用到数据的可视化技术;
-
将求解出的数据保存或导出文件
-
D{0-1}KP 实例数据集需存储在数据库;
-
平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据;
-
人机交互界面要求为GUI界面。
二、功能设计
- 绘制任意一组D{0-1}KP数据以重量为横轴、价值为纵轴的数据散点图;
- 对任意一组D{0-1}KP数据按项集第三项的价值:重量比进行非递增排序;
- 用户能够自主选择动态规划算法、回溯算法求解指定D{0-1} KP数据的最优解和求解时间(以秒为单位);
- 任意一组D{0-1} KP数据的最优解、求解时间和解向量
三、设计实现
在实验过程中,此次实验要求的技术与我在此之前的掌握的技术有一定差距。所以我复习了大学三年级第一学期在《算法设计与分析》课程中学习到的动态规划算法与回溯算法求解0/1背包问题的内容,循序渐进,推进实验的进程。
1、动态规划算法
动态规划算法的核心思想是:
将大问题划分为小问题进行解决,从而一步一步获得最优解的处理算法。
动态规划算法与分治算法类似,其基本思想也是将代求问题分解成若干子问题,先求解子问题,然后从这些子问题的解得到原问题的解。
与分治算法不同的是,适合于动态规划求解的问题,经分解得到的子问题往往不是互相独立的,即下一个子阶段的求解过程是建立在上一个子阶段的解的基础上,进行进一步的求解。
2、回溯算法
-
顾名思义,回溯法一个很显著的特征就是回溯,即在处理完某种情况或出现不能继续进行的情况时,要退回到之前的某个“交叉口”,处理另一种可能。
-
回溯法是一种非常有效的方法,有“通用的解题法”之称。它有点像穷举法,但是更带有跳跃性和系统性,他可以系统性的搜索一个问题的所有的解和任一解。回溯法采用的是深度优先策略。通常,回溯法会定义一个解空间,这个解空间通常是以图或树的形式呈现出来的。背包问题的解空间是树的形式,属于深度优先搜索。
-
回溯法在确定了解空间的结构后,从根结点出发,以深度优先的方式搜索整个解空间,此时根结点成为一个活结点,并且成为当前的扩展结点。每次都从扩展结点向纵向搜索新的结点,当算法搜索到了解空间的任一结点,先判断该结点是否肯定不包含问题的解(是否还能或者还有必要继续往下搜索),如果确定不包含问题的解,就逐层回溯;否则,进入子树,继续按照深度优先的策略进行搜索。当回溯到根结点时,说明搜索结束了,此时已经得到了一系列的解,根据需要选择其中的一个或者多个解即可。
回溯法解决问题一般分为三个步骤:
(1)针对所给问题,定义问题的解空间;
(2)确定易于搜索的解空间结构;
(3)以深度优先的方式搜索解空间。
3、遗传算法
- 查阅资料,设计遗传算法求解D{0-1}KP,并利用此算法测试要求(3);
百度百科中对于遗传算法的解释:https://baike.baidu.com/item/遗传算法/838140?fr=aladdin。
遗传算法(Genetic Algorithms )是基于生物进化理论的原理发展起来的一种广为应用的、高效的随机搜索与优化的方法。其主要特点是群体搜索策略和群体中个体之间的信息交换,搜索不依赖于梯度信息。它是在70年代初期由美国密西根( Michigan )大学的霍兰( Holland )教授发展起来的。1975年霍兰教授发表了第一本比较系统论述遗传算法的专著《自然系统与人工系统中的适应性》(《 Adaptationin Natural and Artificial Systems 》)。遗传算法最初被研究的出发点不是为专门解决最优化问题而设计的,它与进化策略、进化规划共同构成了进化算法的主要框架,都是为当时人工智能的发展服务的。迄今为止,遗传算法是进化算法中最广为人知的算法。
遗传火算法的实施步骤如下(以目标函数求最小为例)。
第一步:初始化 t←0进化代数计数器;T是最大进化代数;随机生成M个个体作为初始群体P(t);
第二步:个体评价 计算P(t)中各个个体的适应度;
第三步:选择运算 将选择算子作用于群体;
第四步:交叉运算 将交叉算子作用于群体;
第五步:变异运算 将变异算子作用于群体,并通过以上运算得到下一代群体P(t + 1);
第六步:终止条件判断 t≦T:t← t+1 转到步骤2;t>T:终止 输出解。
- 遗传算法应用步骤:
确定决策变量及各种约束条件,即个体的表现型X和问题的解空间;
建立优化模型 (目标函数最大OR 最小) 数学描述形式 量化方法;
染色体编码方法;
解码方法;
个体适应度的量化评价方法 F(x)
设计遗传算子;
确定有关运行参数。
参考:https://blog.csdn.net/wangqiuyun/article/details/8847307
4、关键代码展示
for(int i=1;i<row;i++) {
String Row=Integer.toString(i);
for(int j=1;j<4;j++) {
String Weight=Integer.toString(weight[i][j]);
String Value=Integer.toString(value[i][j]);
String addsql="INSERT INTO table_kp01(tempname,weight,value) VALUES(?,?,?)";
PreparedStatement pst=null;
pst=conn.prepareStatement(addsql);//预编译SQL
pst.setString(1, Row);
pst.setString(2, Weight);
pst.setString(3, Value);
pst.executeUpdate();//执行SQl语句
}
}
<%@page import="org.apache.log4j.Logger" %>
private static Logger log1=Logger.getLogger(RES);
private static Logger log2=Logger.getLogger(RUN_TIME);
log1.debug("最优解:"+res);
out.println("</br>");//换行标签
log2.debug("运行时间:"+run_time+"s");
5、结果展示
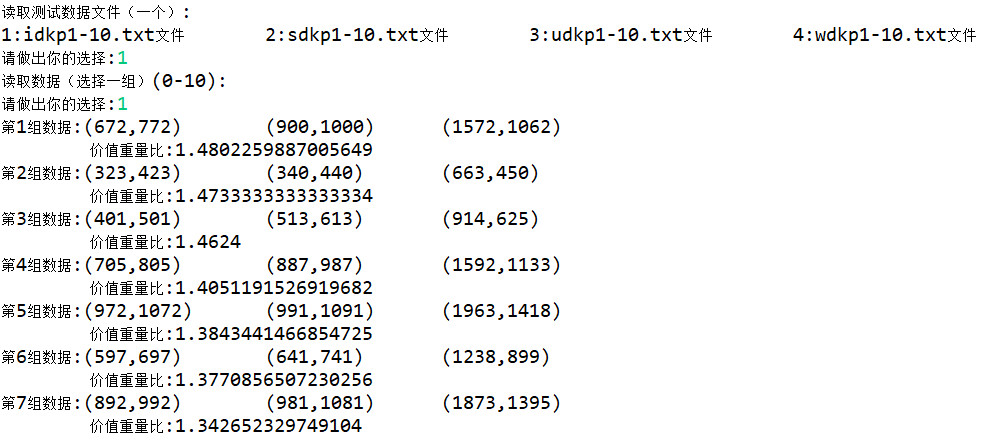

D{0-1}KP 实例数据集需存储在数据库
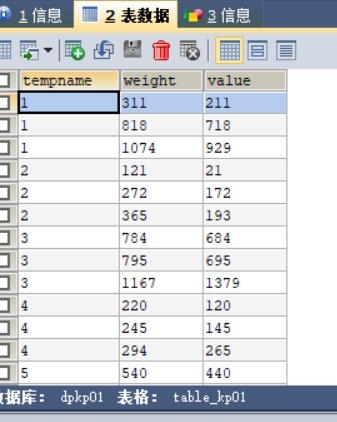
平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据;
调用算法结果展示:

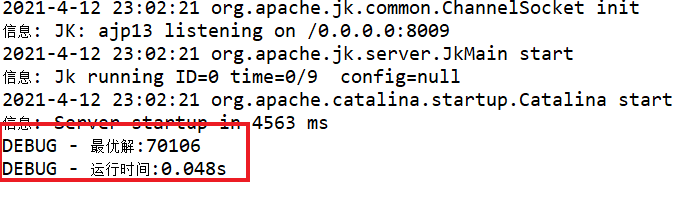
人机交互界面要求为GUI界面(WEB页面、APP页面都可);
结果展示:
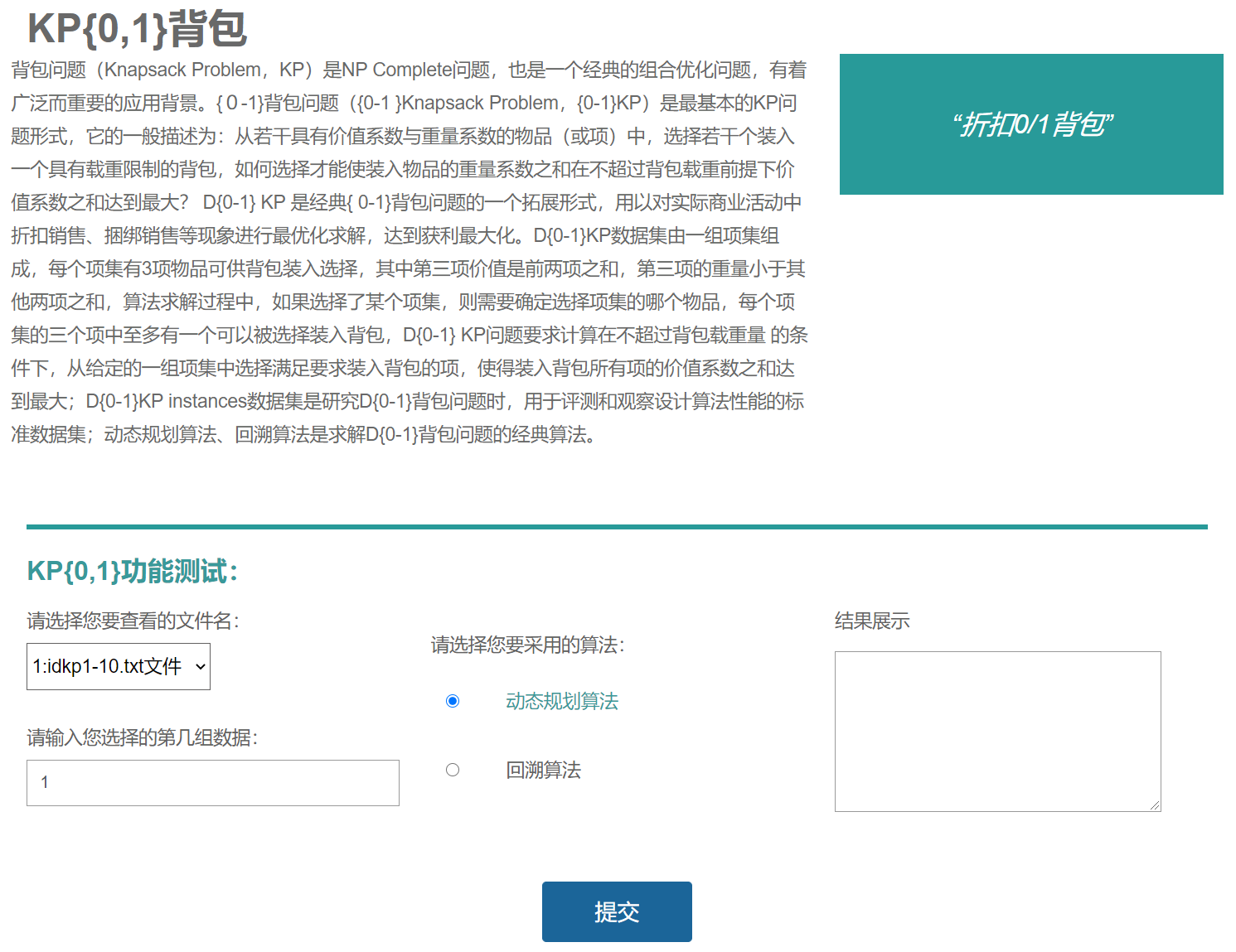
实现结果:

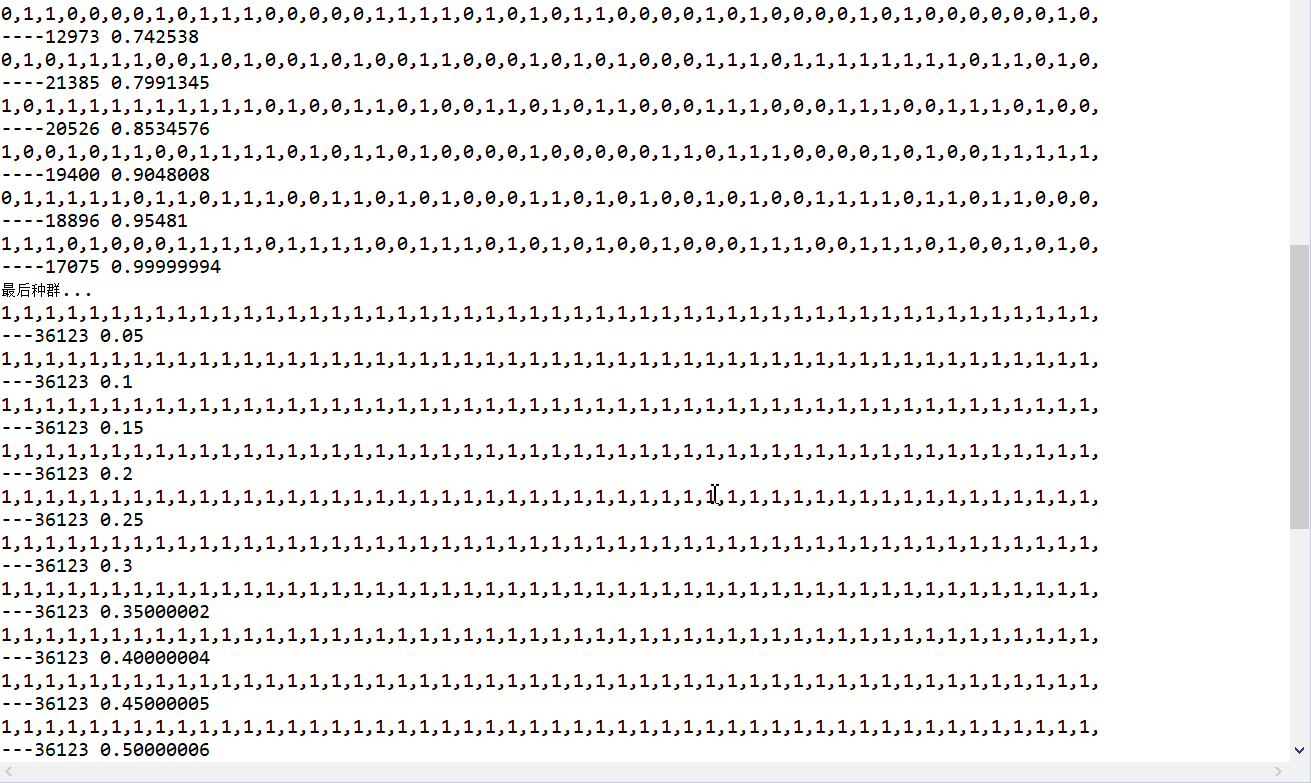
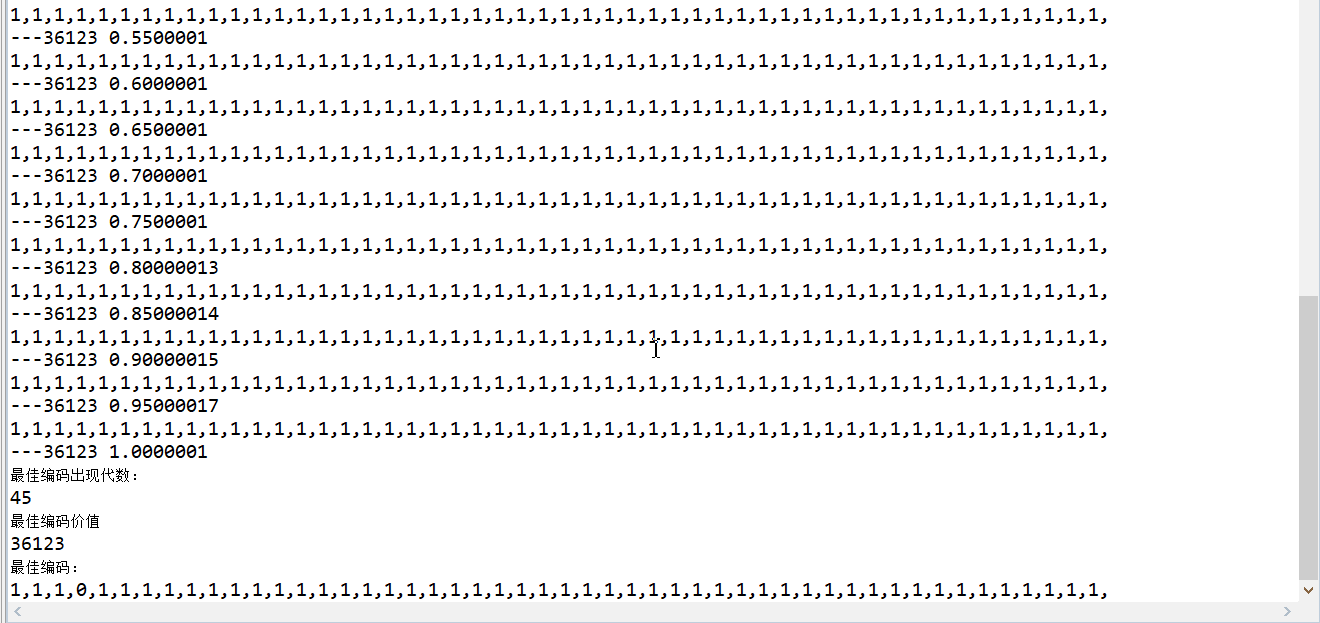
6、PSP
| PSP | 任务内容 | 计划完成所需要的时间(min) | 实际完成所需要的时间(min) |
|---|---|---|---|
| Planning | 计划 | 45 | 50 |
| Estimate | 估计这个任务需要多少时间,并规划大致工作步骤 | 50 | 55 |
| Development | 开发 | 700 | 800 |
| Analysis | 需求分析(包括学习新技术) | 130 | 200 |
| Design Spec | 生成设计文档 | 30 | 35 |
| Design Review | 设计复审 (和同事审核设计文档) | 15 | 13 |
| Coding Standard | 代码规范 | 14 | 18 |
| Design | 具体设计 | 260 | 300 |
| Coding | 具体编码 | 300 | 354 |
| Code Review | 代码复审 | 58 | 60 |
| Test | 测试 | 70 | 90 |
| Reporting | 报告 | 60 | 70 |
| Summer | 任务+总结 | 40 | 60 |
7、小结
两人进行合作要比一人进行容易得多。经过这次实验,我发现在真正的结对的情况下,确实会产生1+1>2的情况,因为另一方会从另外一个角度思考,发现对方代码的不足并及时指正。但也存在双方工作没办法平均分配,双方各有擅长的方面,所以在合作时更多的是取长补短,发会合作的优势。

