20191218 实验四《Python程序设计》实验报告
20191218 2020-2021-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 1912
姓名: 唐启恒
学号:20191218
实验教师:王志强
实验日期:2021年6月24日
必修/选修: 公选课
一、实验内容
- Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
(1)程序能运行,功能丰富。(需求提交源代码,并建议录制程序运行的视频)10分
(2)综合实践报告,要体现实验分析、设计、实现过程、结果等信息,格式规范,逻辑清晰,结构合理。10分。
(3)在实践报告中,需要对全课进行总结,并写课程感想体会、意见和建议等。5分
二、实验过程
1.网络爬虫实战
需求分析:发送请求获得返回数据、解析获得数据、输出解析后的数据。
需要调用的库:re、requests。
(1)淘宝网爬虫
创建函数
需求分析:发送请求获得返回数据、解析获得数据、输出解析后的数据。
需要调用的库:re、requests。
-
getHTMLText函数:对服务器发送请求并获得返回数据
def getHTMLText(url): try: header = { 'authority': 's.taobao.com', 'cache-control': 'max-age=0', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', 'referer': 'https://s.taobao.com/search?q=%E4%B9%A6%E5%8C%85&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306', 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9', 'cookie': 'cna=of0cFi+PRlkCAXAga/Rh5jS/; thw=cn; miid=1746754052324791774; t=666c0abca91eaba189bedb8dc7cd9af4; cookie2=1eaa7669168b838f207f946a56d6c06e; v=0; _tb_token_=e3e75bafeab75; _samesite_flag_=true; sgcookie=E0CPuRRNCb3UsPzEfu8ez; unb=2201465236169; uc3=id2=UUphy%2FZ8WVQTGEtLSA%3D%3D&nk2=F5RNZTsZefZoa8k%3D&vt3=F8dBxGepHC4UCW39woY%3D&lg2=UIHiLt3xD8xYTw%3D%3D; csg=76e486aa; lgc=tb801621930; cookie17=UUphy%2FZ8WVQTGEtLSA%3D%3D; dnk=tb801621930; skt=5159b705fae0ca1b; existShop=MTU5MDkyNjE3MQ%3D%3D; uc4=id4=0%40U2grEJGD1caelul1pbdrh9%2FZHNY3neYE&nk4=0%40FY4GsvRAzezC4KJ%2F6Fq%2BPUeNQ5BcAA%3D%3D; tracknick=tb801621930; _cc_=UIHiLt3xSw%3D%3D; _l_g_=Ug%3D%3D; sg=09c; _nk_=tb801621930; cookie1=U7Gmn5kRAszHsmIsFcN1Y6rDPBjpuYddw9YlBSNITsY%3D; enc=JDI2YJQr%2Fg4gc0f7829oFezKf9MFrM%2BUlJZ5JBY%2BEdOSe%2B%2FAum2YSuESyxnliSWuHaiCwNzPAjY7BTLPa4m%2FaHJdUFL1HRK3vGT2eEY7UHE%3D; tfstk=cOkVBSbAMKpVkry69-wafcZzA2AfaQUgRTrUiXN6mk92_GVb8sXPWuMlJurNaWNc.; mt=ci=12_1; hng=CN%7Czh-CN%7CCNY%7C156; UM_distinctid=1726a96e2ab3d8-0a6e4de9b0dc43-3a65420e-144000-1726a96e2ac9d1; alitrackid=www.taobao.com; lastalitrackid=www.taobao.com; CNZZDATA1277659945=1256986223-1590926173-%7C1590926292; uc1=cookie15=WqG3DMC9VAQiUQ%3D%3D&existShop=false&pas=0&cookie21=Vq8l%2BKCLjA%2Bl&cookie16=URm48syIJ1yk0MX2J7mAAEhTuw%3D%3D&cookie14=UoTV7N%2B0xtxMZQ%3D%3D; JSESSIONID=CB695AD612260F9E44DDD5E96A505328; l=eBSA3l3gqv46Q3ayBOfZourza77OSIRYIuPzaNbMiOCP_7fp51ChWZv0tj89C3GVh6xXR3u14VQeBeYBqQOSnxv92j-la_kmn; isg=BCAgnhN2arDKctWRuj9ghLH78S7yKQTz4pJPapox7DvOlcC_QjnUg_alKT0VHLzL', } r = requests.get(url, headers=header) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "F" -
parsePage函数:通过正则表达式对获得的html文本进行解析,获得我们想要得到的内容。
def parsePage(ilt, html): try: plt = re.findall(r'\"view_price\":\"[\d+\.]*\"', html) tlt = re.findall(r'\"raw_title\"\:\".*?\"', html) for i in range(len(plt)): price = eval(plt[i].split(':')[1]) title = eval(tlt[i].split(':')[1]) ilt.append([price, title]) except: print("F") -
printGoodsList函数:输出解析过的内容,同时使用正则表达式对输出进行格式化。
def printGoodsList(ilt): tplt = "{:4}\t{:8}\t{:16}" print(tplt.format("序号", "价格", "商品名称")) count = 0 for g in ilt: count = count + 1 print(tplt.format(count, g[0], g[1]))
其中,头部Head的设置是为了绕过反爬虫机制。
在刚开始写代码时,程序运行并没有输出。检查请求状态码,发现状态码为200,能够正常访问。查找资料后发现,淘宝网设置了反爬虫机制,结合上课所学内容,进行了header中代理的仿用户处理。
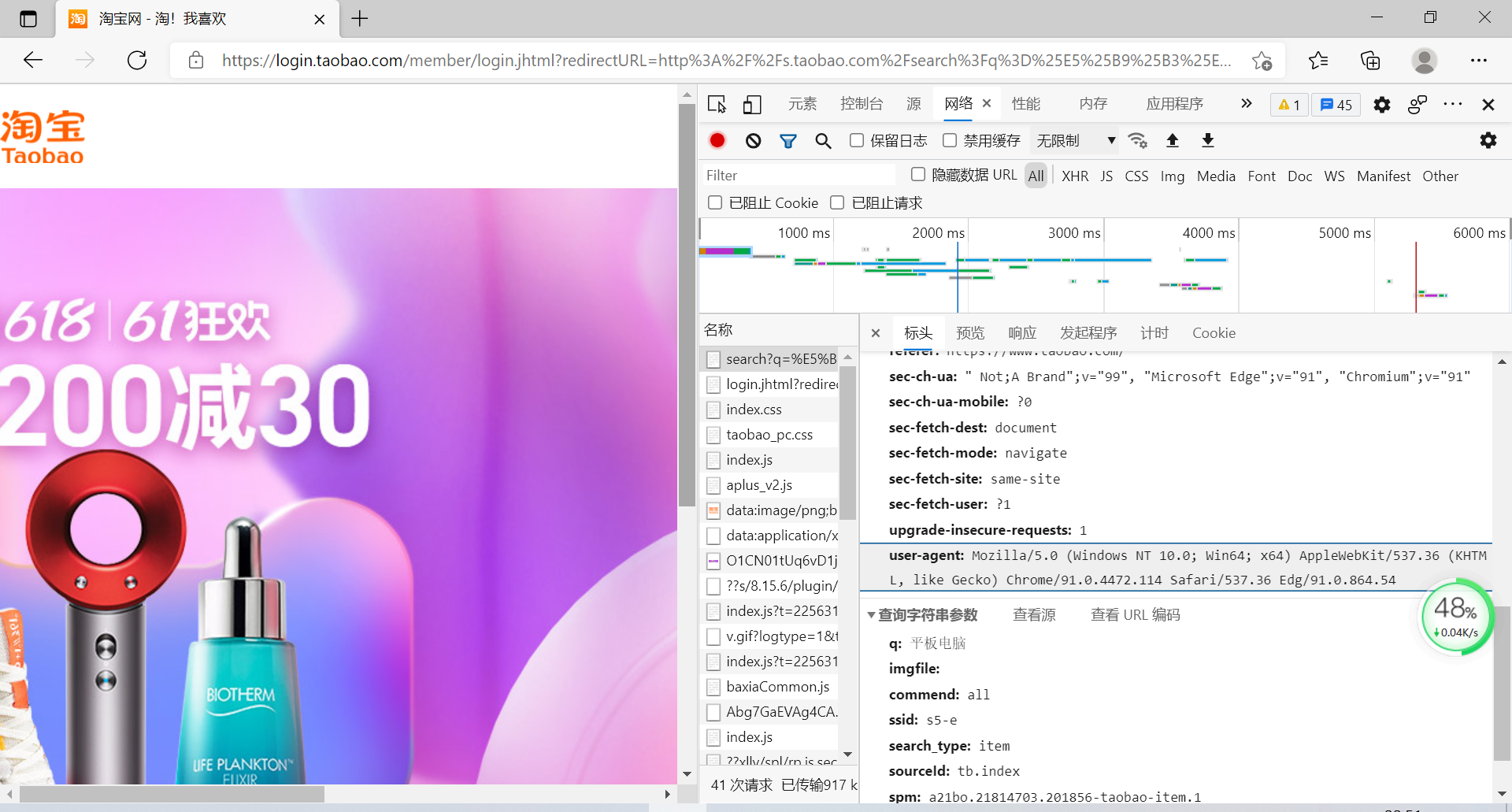
进行爬虫
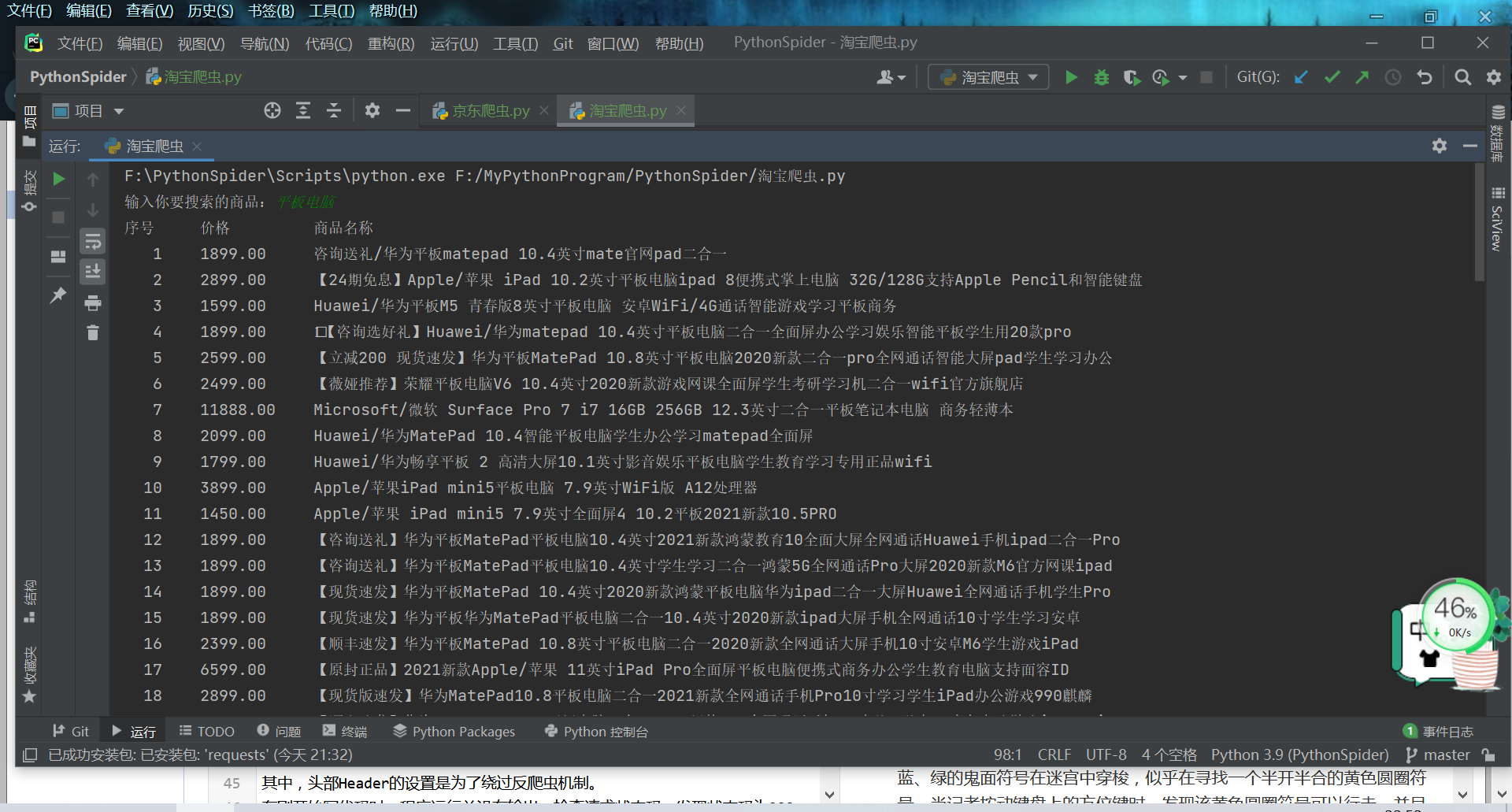
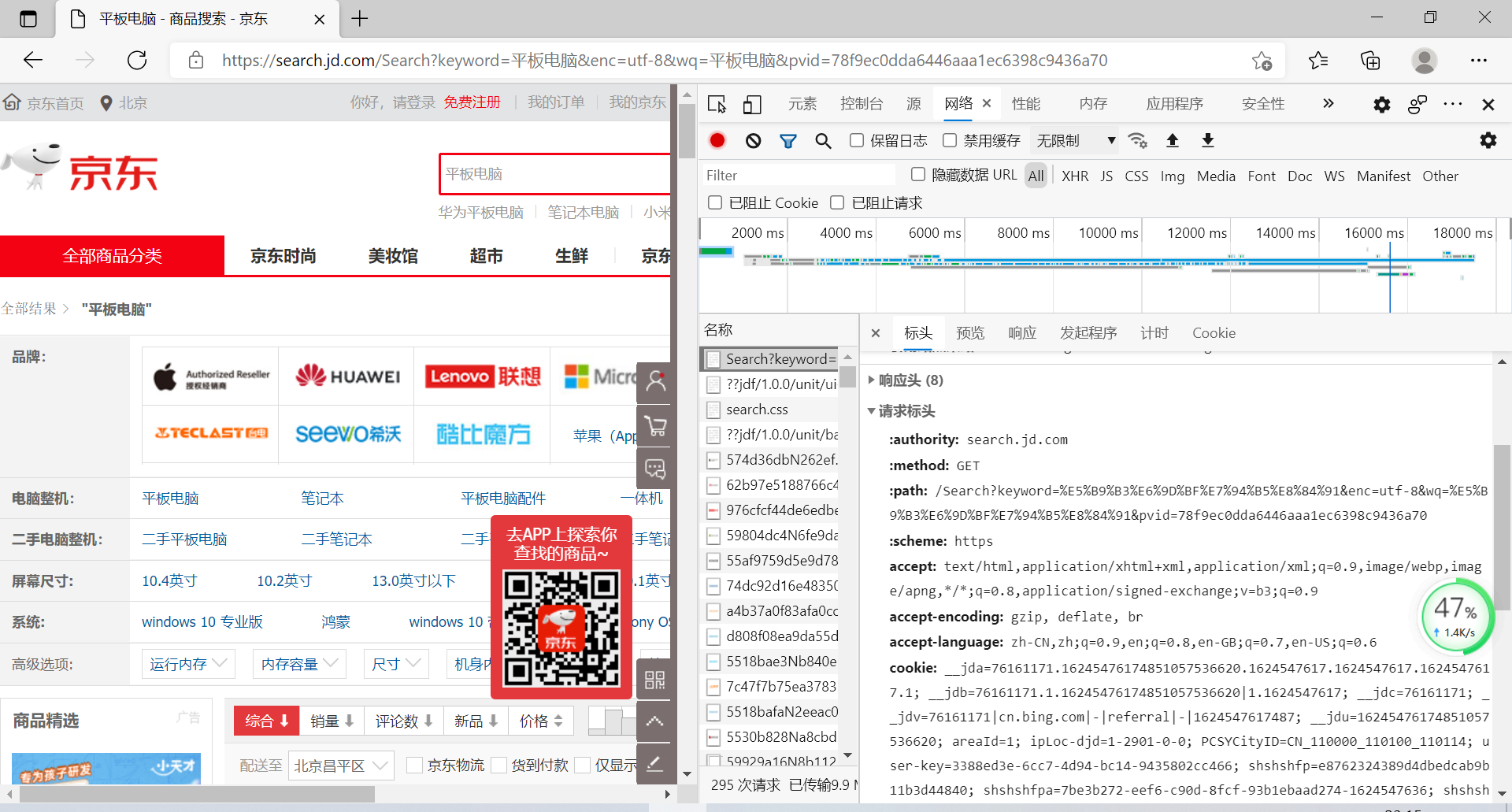
(2)京东网爬虫
创建函数
定义函数抓取每页前30条商品信息
def crow_first(n):
# 构造每一页的url变化
url = 'https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=' + str(
2 * n - 1)
head = {'authority': 'search.jd.com',
'method': 'GET',
'path': '/s_new.php?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&page=4&s=84&scrolling=y&log_id=1529828108.22071&tpl=3_M&show_items=7651927,7367120,7056868,7419252,6001239,5934182,4554969,3893501,7421462,6577495,26480543553,7345757,4483120,6176077,6932795,7336429,5963066,5283387,25722468892,7425622,4768461',
'scheme': 'https',
'referer': 'https://search.jd.com/Search?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&page=3&s=58&click=0',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
'Cookie': 'qrsc=3; pinId=RAGa4xMoVrs; xtest=1210.cf6b6759; ipLocation=%u5E7F%u4E1C; _jrda=5; TrackID=1aUdbc9HHS2MdEzabuYEyED1iDJaLWwBAfGBfyIHJZCLWKfWaB_KHKIMX9Vj9_2wUakxuSLAO9AFtB2U0SsAD-mXIh5rIfuDiSHSNhZcsJvg; shshshfpa=17943c91-d534-104f-a035-6e1719740bb6-1525571955; shshshfpb=2f200f7c5265e4af999b95b20d90e6618559f7251020a80ea1aee61500; cn=0; 3AB9D23F7A4B3C9B=QFOFIDQSIC7TZDQ7U4RPNYNFQN7S26SFCQQGTC3YU5UZQJZUBNPEXMX7O3R7SIRBTTJ72AXC4S3IJ46ESBLTNHD37U; ipLoc-djd=19-1607-3638-3638.608841570; __jdu=930036140; user-key=31a7628c-a9b2-44b0-8147-f10a9e597d6f; areaId=19; __jdv=122270672|direct|-|none|-|1529893590075; PCSYCityID=25; mt_xid=V2_52007VwsQU1xaVVoaSClUA2YLEAdbWk5YSk9MQAA0BBZOVQ0ADwNLGlUAZwQXVQpaAlkvShhcDHsCFU5eXENaGkIZWg5nAyJQbVhiWR9BGlUNZwoWYl1dVF0%3D; __jdc=122270672; shshshfp=72ec41b59960ea9a26956307465948f6; rkv=V0700; __jda=122270672.930036140.-.1529979524.1529984840.85; __jdb=122270672.1.930036140|85.1529984840; shshshsID=f797fbad20f4e576e9c30d1c381ecbb1_1_1529984840145'
}
r = requests.get(url, headers=head)
# 指定编码方式,不然会出现乱码
r.encoding = 'utf-8'
html1 = etree.HTML(r.text)
# 定位到每一个商品标签li
datas = html1.xpath('//li[contains(@class,"gl-item")]')
# 将抓取的结果保存到本地CSV文件中
with open('JD_Phone.csv', 'a', newline='', encoding='utf-8')as f:
write = csv.writer(f)
for data in datas:
p_price = data.xpath('div/div[@class="p-price"]/strong/i/text()')
p_comment = data.xpath('div/div[5]/strong/a/text()')
p_name = data.xpath('div/div[@class="p-name p-name-type-2"]/a/em')
# 这个if判断用来处理那些价格可以动态切换的商品,比如上文提到的小米MIX2,他们的价格位置在属性中放了一个最低价
if len(p_price) == 0:
p_price = data.xpath('div/div[@class="p-price"]/strong/@data-price')
# xpath('string(.)')用来解析混夹在几个标签中的文本
write.writerow([p_name[0].xpath('string(.)'), p_price[0], p_comment[0]])
f.close()
定义函数抓取每页后30条商品信息
def crow_last(n):
# 获取当前的Unix时间戳,并且保留小数点后5位
a = time.time()
b = '%.5f' % a
url = 'https://search.jd.com/s_new.php?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&cid2=653&cid3=655&page=' + str(
2 * n) + '&s=' + str(48 * n - 20) + '&scrolling=y&log_id=' + str(b)
head = {
'authority': 'search.jd.com',
'cache-control': 'max-age=0',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'referer': 'https://www.jd.com/',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': '__jdu=2047103149; shshshfpa=16ae8f53-5ae1-9de0-0ec7-d606fd429b8b-1571133416; shshshfpb=pYrZgLCdz5oFhuEIhY2v4Zw%3D%3D; qrsc=3; __jdv=76161171|baidu|-|organic|%25E4%25BA%25AC%25E4%25B8%259C|1590926787595; areaId=14; ipLoc-djd=14-1116-3433-0; rkv=V0500; UM_distinctid=1726aa0663582-03d3560bee40c-3a65420e-144000-1726aa06636233; TrackID=1Fkw1M1_Um8z4aZxzM88PaVrfa1NclrA5-Pp_oUv0QoGkQJsAuQx_mlrVK1jb-Hz3blG4lWBHe27qqvbdEe8mEpk3jKUxnzcTLHVVokp69gA; thor=3B3B94FCFFD97861EC4C84D7B4E9034099196D8E6BE2C0ED4523496131EFDDEEED2430BF573FA2C70A575F172968BC1D7BBD1E6A3D7102679C1ADEEEAA9FE084385F1BACFB82ADBB33C28559B3B8B60D0EFCC5D00234F976A6362CCB6DC3ED3817CFF1AAA7E47A87189B77281897EB3E44F2F3BF77CD5FB4D0153D05B69D0E9CD7968F837A3A84E42F389C3CC06275A13682D4F2460474EE85DC2A5907A93452; pinId=51UPJKKWueTfOBEKj6YZyw; pin=jd_UcBGwTpLaHLW; unick=jd_UcBGwTpLaHLW; ceshi3.com=000; _tp=yzNUSmC8aRtAFY8ILrHooA%3D%3D; _pst=jd_UcBGwTpLaHLW; shshshfp=9d38b151fe2b761e0c3a4fb78c195c2e; __jda=122270672.2047103149.1571133379.1586011436.1590926788.9; __jdb=122270672.8.2047103149|9.1590926788; __jdc=122270672; shshshsID=e446e3a630a5a9d9aeae1b61e2ce2641_6_1590927979367; CNZZDATA1277659945=2059356410-1590926797-https%253A%252F%252Fwww.jd.com%252F%7C1590927980; 3AB9D23F7A4B3C9B=7FX6VP23LCI5I6DXXAO64CHVLKIH6WDXMGJUDIUAB3PGKODGHZXKQUSISB62YVTTU2C7OEMI5KN4ZQSALB3UY6MC3I',
}
r = requests.get(url, headers=head)
r.encoding = 'utf-8'
html1 = etree.HTML(r.text)
datas = html1.xpath('//li[contains(@class,"gl-item")]')
with open('JD_Phone.csv', 'a', newline='', encoding='utf-8')as f:
write = csv.writer(f)
for data in datas:
p_price = data.xpath('div/div[@class="p-price"]/strong/i/text()')
p_comment = data.xpath('div/div[5]/strong/a/text()')
p_name = data.xpath('div/div[@class="p-name p-name-type-2"]/a/em')
if len(p_price) == 0:
p_price = data.xpath('div/div[@class="p-price"]/strong/@data-price')
write.writerow([p_name[0].xpath('string(.)'), p_price[0], p_comment[0]])
f.close()
一样的方法绕过反爬虫机制
2.简易游戏开发
吃豆人小游戏
- 吃豆人是电子游戏历史上的经典街机游戏,由Namco公司的岩谷彻设计并由Midway Games在1980年发行。Pac-Man被认为是80年代最经典的街机游戏之一,游戏的主角小精灵的形象甚至被作为一种大众文化符号,或是此产业的代表形象。它的开发商Namco也把这个形象作为其吉祥物和公司的标帜,一直沿用至今。该游戏的背景以黑色为主。画面中,“Google”6个字母组成回廊似的迷宫画面,四个颜色分别为红、黄、蓝、绿的鬼面符号在迷宫中穿梭,似乎在寻找一个半开半合的黄色圆圈符号。当记者按动键盘上的方位键时,发现该黄色圆圈符号可以行走,并且可以吞吃迷宫路径上的小黄豆,但遇到鬼面符号时就要被吃掉。
- 为方便开发,我将代码分成两个文件,分别是main.py和unit.py
(1)main.py
在其中主要实现了游戏窗口、参数等的初始化
constant initialize
FPS = 60
BLOCK_SIZE = 24
WIDTH = 29
HEIGHT = 15
WINDOW_WIDTH = WIDTH * BLOCK_SIZE
WINDOW_HEIGHT = HEIGHT * BLOCK_SIZE
MAP_NAME = "./material/map.maze"
BGM_NAME = "./material/bgm.ogg"
BLOCK_IMAGE = "./material/block.png"
FOOD_IMAGE = "./material/food.png"
GAMEOVER_IMAGE = "./material/gameover.png"
SERVER_PORT = 30000
ENEMY_COUNT = 4
OX = 1
OY = 1
DELAY = 8
pygame initialize
pygame.init()
display = pygame.display.set_mode((WINDOW_WIDTH, WINDOW_HEIGHT))
clock = pygame.time.Clock()
block_image = pygame.image.load(BLOCK_IMAGE)
food_image = pygame.image.load(FOOD_IMAGE)
gameover_image = pygame.image.load(GAMEOVER_IMAGE)
bgm = pygame.mixer.music.load(BGM_NAME)
scene = "game"
unit_list = []
game_map = []
map initialize
def load_map(filename):
global game_map
game_map.clear()
file = open(filename, 'r')
for line in file.readlines():
game_map.append(list(line.strip()))
pass
pass
set passport
def through(position):
x = position[0]
y = position[1]
in_range = (x >= 0 and x < WIDTH) and (y >= 0 and y < HEIGHT)
in_space = (not game_map[y][x] == '1')
return (in_range and in_space)
pass
以及对游戏是否结束的判断模块
def gameover():
pygame.mixer.music.stop()
keys = pygame.key.get_pressed()
if keys[K_RETURN]:
initialize()
pass
display.fill((0, 0, 0))
x = (WINDOW_WIDTH-gameover_image.get_width())/2
y = (WINDOW_HEIGHT-gameover_image.get_height())/2
display.blit(gameover_image, (x, y))
pygame.display.update()
pass
(2)unit.py
在其中主要实现了敌人和玩家的创建,以及实现了游戏人物的移动
class user(unit):
def __init__(self, x, y):
super(user, self).__init__(USER_IMAGE)
self.position = [x, y, x, y]
pass
def next(self, direction):
self.turn(direction)
self.ahead()
return (self.position[2], self.position[3])
pass
class enemy(unit):
def __init__(self, id, x, y):
filename = ENEMY_IMAGE[id]
super(enemy, self).__init__(filename)
self.position = [x, y, x, y]
pass
def track(self, user_pos):
rand_dir = [1,2,3,4]
self.turn(random.choice(rand_dir))
pass
def clockwise(self):
self.turn(self.direction + 1)
pass
游戏运行截图
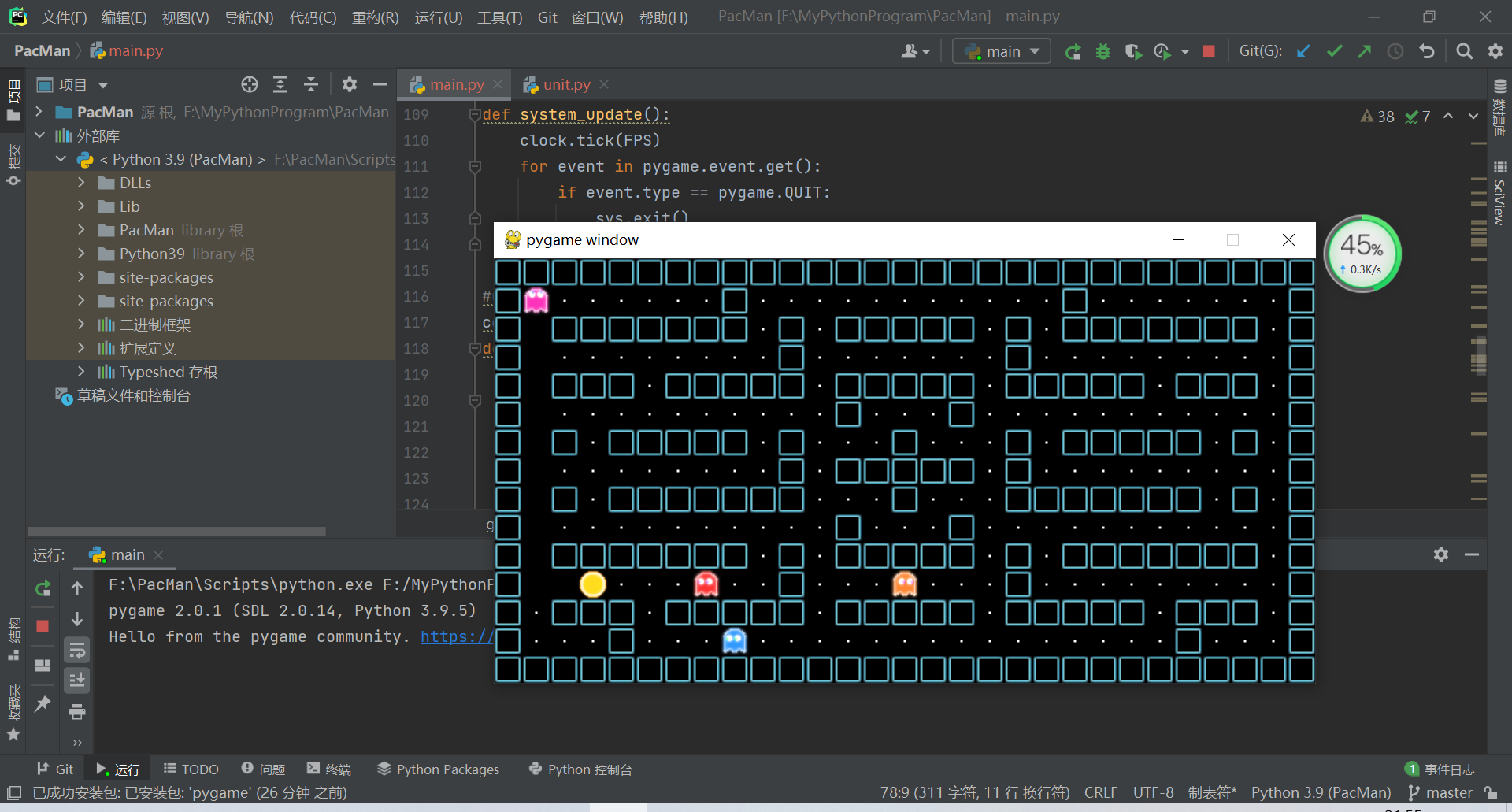
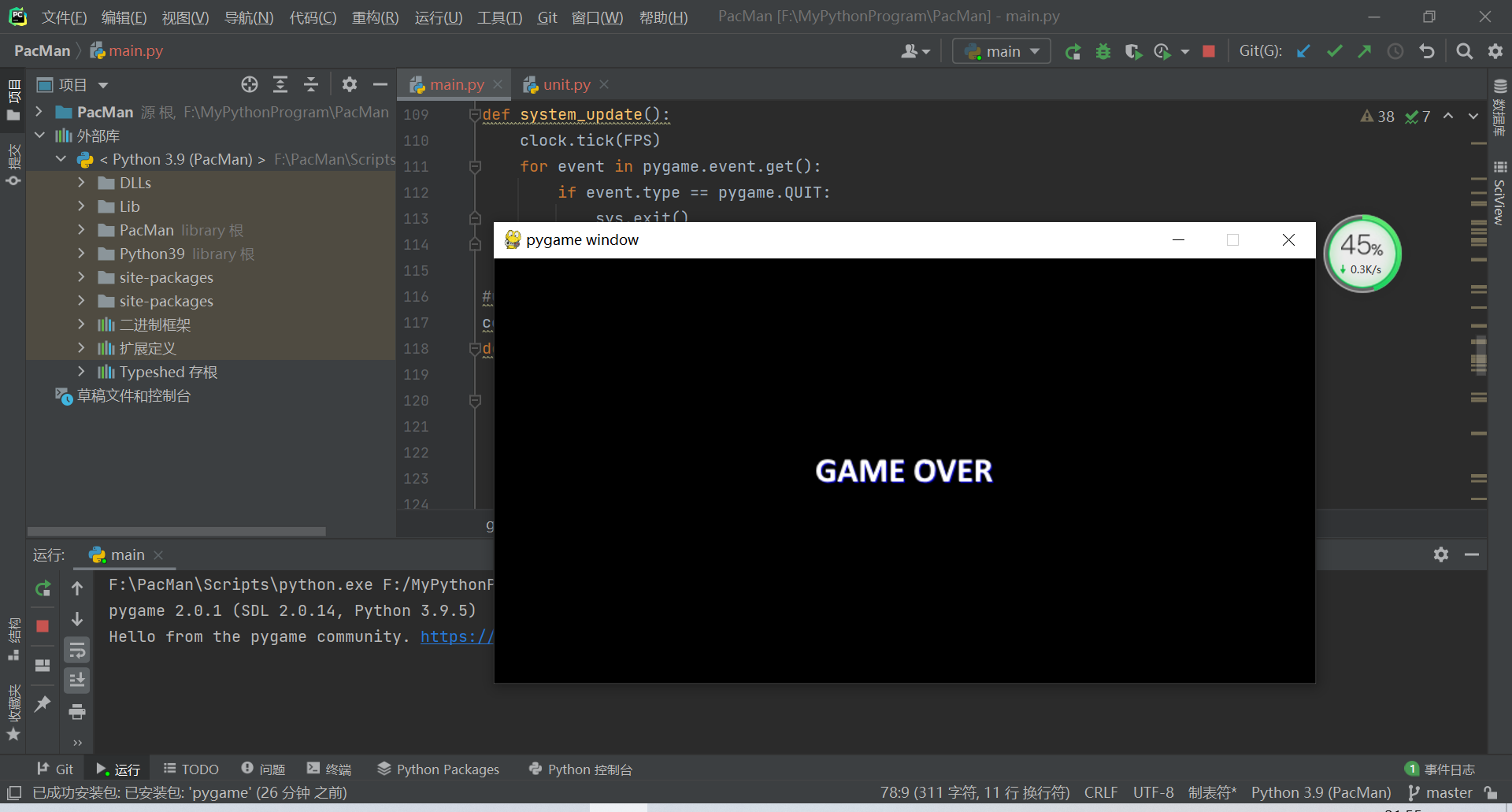
完整代码见码云链接
视频演示已上传给小组长
三、课程总结
知识小结
这一学期跟随着王老师学习了python,回顾所学,收获满满。下面对这学期所学Python知识做一个简单的小结。
Python是一种高级动态、完全面向对象的语言,函数、模块、数字、字符串都是对象,并且完全支持继承、重载、派生、多继承,有益于增强源代码的复用性。
Python是一种计算机程序设计语言(解释型语言),具有代码少、简单、运行速度慢的特点。
-
1、数据类型
- 数字型:int、float、Boolean
- 非数字型:字符串、列表、元组、字典
- 可变类型:列表、字典
- 不可变类型:数字、字符串、元组
- 格式化字符串:两种写法
我们上课主要学习了format字符串
a、使用位置参数,{}的值对应填充 fromat 后面的变量 print("{}的级别是{}".format(score,grade)) 还可以使用 0、1 编号进行多个引用,0、1分别大表 format 后面变量的位置 print("{0}的级别是{1},分数是{0}".format(score,grade)) 甚至还可以使用参数列表,但是 format 后面要用 *list list=[score,grade] print("{0}的级别是{1},分数是{0}".format(*list))
b、使用关键字参数:
print("{score}的级别是{grade},分数是{score}".format(score=score,grade=grade)) 可以使用字典来传递关键字参数,但是要用 **hash hash = {'name':'hoho','age':18}
'my name is {name},age is {age}'.format(//hash) 'my name is hoho,age is 18'
精度与进制:变量后面加上冒号就可以指定输出形式
'{0:.2f}'.format(1/3) '0.33' 千分位格式化: print("{1:,}".format(8,9))
-
2、变量
通常数据都是让变量来引用和保存的.
变量是 python 中的重要概念,python 作为一门动态语言,就是体现在变量命名时不需要指定类型,而是可以指向任意类型的数据。变量命名也是有规则的,即必须是有数字、字母、下划线组成且不能数字开头,除此之外变量名还有一个写法上的通用原则:驼峰命名法- 小驼峰:首字母小写后面单词首字母大写
- 大驼峰:每个单词的首字母都大写
一般函数、变量名用小驼峰,模块和类名用大驼峰
-
3、控制流
python 程序运行都是从上到下依次运行,但是可以通过控制流来人为改变运行逻辑。- if :条件判断
- while、for:两种循环
而如果要在循环体内再次人为改变逻辑,就需要用到 breake、continue了,特别注意这两个破坏循环规则的语句都只作用在最近一层的 for、while 循环上。
-
4.函数
函数的出现是为了节省代码,减少冗余。
def func(): print(' 调用了函数')
匿名函数:
常用来构建列表 list=[i for i in range(6)]
还可以搭配 map 函数来使用, map(func,[1,2,3,4,5]) 会将列表中得数组依次传入 func 函数得到结果,得到一个map 值,再用 list 转换一下就可以得到一个列表
函数参数(重点理解):
函数的参数:形式参数的定义以及实际参数的写法- a、位置参数:实参+定义。就是实参会一一对应到形参上
def func(num1) print(num1) func(10) - b、默认参数:定义。有默认值,如果传入了实参就用实参,定义的时候要在非默认参数后面:
正确:def func(num1,num2=10)
错误:def func(num1=10,num2) - c、关键字参数:实参。传入实际参数时,指定参数名字来传递数据,一般有一个实参用的是关键字参数,其余也要用,不然容易造成一个参数多个值的错误。 func(num1=12,num2=10) func(12,num2=10) d、元组可变参数:定义。可以接收任意数量的位置参数。使用 *args 来接收,会将接收到的值自动组包成一个元组赋给args,参数变成元组了 def func(num1,*args,name): print(num1) print(args) print(name) func(10,2,3,4,name='lan') 结果:这里是位置参数+元组可变参数 10 (2, 3, 4) lan e、字典可变参数:定义。可以接收多余的关键字参数,用 **kwargs 来接收。必须放到参数列表最后,不然报错。参数变成字典了 def func(num1=0,**kwargs): print(num1) print(kwargs) func(2,a=3,b=4) 结果: 2 {'a': 3, 'b': 4}
注意: a、如果实参用了关键字参数,最好就都用关键字参数。
字典可变参数必须要放到最后面(比默认参数还要后),元组可变没有顺序要求。
左右:普通参数《==元组可变《==默认参数(应该靠后)《==字典可变(必须最后) 除了字典可变,其他顺序不是绝对,如果顺序有变化,实参中可以用关键字参数来调节 b、如果形参里面既有 默认参数,又有可变参数,那么要将默认参数放到最后面,并且赋值时必须要用关键字参数。这也符合默认参数放到非默认参数后面的原则 def func(num1=0,*args): print(num1) print(args) # 像这里本来时像把 2,3,4 都给 args ,可以由于位置参数的原因,最终是num1=2,rags=(3,4)) func(2,3,4) 变成如下就好了:
def func(*args,num1=0): func(2,3,4,num1=10)
- a、位置参数:实参+定义。就是实参会一一对应到形参上
-
5、文件操作
学习了最基本的文件读写操作,在实验三中的socket通信中有所体现 -
6、网络爬虫
在最后几节课中,我学习了request等爬虫需要用到的库中相关函数的使用,并动手实践爬虫了豆瓣网、疫情动态网,熟悉了爬虫的一般方法。
感想与建议
-
在这一学期课程中,我对python这门语言有了更加深入的了解。python的库十分丰富,功能强大,品类繁多。虽然开始课程的知识点密度没有想象中的大,但正是这段时间我不断在实践中巩固了python基础,这才让我在课程的后半阶段中能够顺利跟上老师的脚步,实现python编程能力的提升。通过这么长时间对python这一语言的学习和实践,我深切地感受到了python的优点。
-
至于说到建议,我觉得课程上可以讲解更多的实例,让我们在动手实现各种各样的案例中学习python编程,也希望今后课程中能够讲到大数据分析、人工智能、神经网络等当下热门的内容。
-
总而言之,在王老师的指导下,我这个学期进行了很多的编程实践,虽然没有完成很庞大的项目,但是在课程学习的过程中,我掌握了许许多多的知识,收获非常大,也体会到了python写脚本、做项目的快乐。对于我来说,能够亲手实现一些以前从来没有编写过的程序确实是满满的成就感。最后,希望自己能够在以后的时间中,继续学习python,亲手写出更多有意思的程序,在python学习之路上继续前行。
