

Flask
1、Flask用法
**视图**
处理业务逻辑代码的函数
**路由**
发送网络请求的URL地址
**Flask框架**
- 轻量级的web后台框架
- werkzeug(路由模块)
- 模版引擎 Jinja2
- 其他功能需要第三方扩展实现
1.1、常用扩展包
Flask_SQLalchemy ORM操作数据库
Flask-RESTful 开发restful的工具
Flask-Session Session存储
Flask-Migrate 管理迁移数据库
Flask-cache 缓存
Flask-WTF 表单
Flask-Mail 邮箱
Flask-Login 认证用户状态
Flask-OpenID 认证
Flask-admin 简单而可扩展的管理接口框架
Flask-Bable 提供国际化和本地化支持-翻译
1.2、最小应用
from flask import Flask
# __name__表示当前文件所在的目录就是Flask项目目录 会在项目目录寻找静态文件夹和模版文件夹
app = Flask(__name__)
if __name__ == '__main__':
# app.run()
# 可选参数
app.run(host='0.0.0.0', port=8888, debug=True)
@app.route('/')
def index():
return 'Hello Flask'
1.3、Flask两种启动方式
以下两种方式启动,即可不需要main函数
命令行运行
export FLASK_APP=xx.py
export FLASK_ENV=development
flask run -h 0.0.0.0 -p 8888
pycharm配置运行
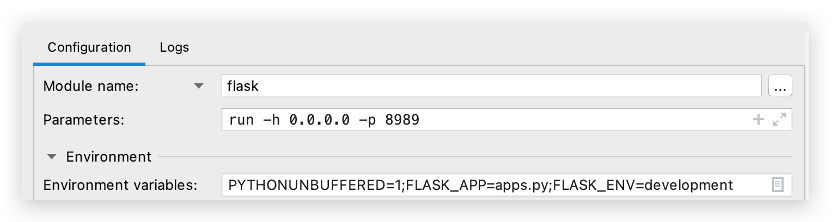
旧版本pycharm
Script path: 脚本路径
Parameters: -m flask run -h 0.0.0.0 -p 8888
1.4、路由
- 通过app.url_map 即可查看路由信息
Map([
<Rule '/index' (OPTIONS, GET, HEAD) -> index>,
<Rule '/static/<filename>' (OPTIONS, GET, HEAD) -> static>
])
- 设置请求方式 get、post
@app.route('/index', methods=['get', 'post'])
def index():
print(app.url_map)
return 'Hello Flask'
1.4.1、路由变量
# 变量名称和形参名称必须一致
@app.route('/useradd/<userid>')
def useradd(userid):
print('userid', userid)
1)、转换器
设置传递的参数的类型。
int、string、float、uuid。
# int 为转换器名称,非数据类型
@app.route('/useradd/<int:userid>')
转换器都是基于from werkzeug.routing import BaseConverter
2)、自定义转换器
from werkzeug.routing import BaseConverter
class MobileConverter(BaseConverter):
regex = r"1[3-9]\d{9}$"
# 将自定义的转换器类,注册到系统默认的转换器字典中
app.url_map.converters['mob'] = MobileConverter
@app.route('/userad/<mob:mobile>')
def userad(mobile):
print(mobile)
1.5、请求request
1.5.1、request参数获取
from flask import request
1、localhost:8000/user/zhangsan/22
2、localhost:8000/user?name=zs&age=12 GET请求
request.args获取
request.args.get("")
# 3、表单参数
{"name":"zhangsan","age":21} POST请求
request.form获取
request.form.get("")
# 4、json字符串
'{"name":"zhangsan","age":21}'
request.json获取
json字符串转换为字典json.loads()
# 5、文件类型参数
request.files获取
fimg = request.files['img'] # type:FileStorage 类型声明,有提示
fimg.save("1.png")
1.6、响应
1.6.1、访问静态资源
静态资源默认目录为static。
修改静态资源目录
app = Flask(__name__,
static_folder="static1",
static_url_path=“res/img”
)
# 访问路径
localhost:8080/res/img/12.png
1.6.2、返回模版文件
新建templates目录
@app.route('/')
def index():
return render_template('index.html')
1.6.3、返回响应数据
- 返回3个值,也就是元祖集合,分别是响应体、响应状态码、响应头。
- 自定义响应对象Response
from flask import Response,make_response
# 创建响应对象
response=make_response("hello flask")
# 设置响应头
response.headers['B']=10
return response
1.6.4、返回json
可直接使用flask自带的jsonify()生成json响应。
dict={"name":"zhangdan","age":22}
return jsonify(dict1)
# return jsonify(name="zs",age=22) 也支持关键字实参的形式
1.6.5、重定向redirect
# 重定向到自己的路由,只需要url资源段
return redirect("/index")
1.7、状态保持与异常捕获
1.7.1、Cookie
特点
- 数据保存在客户端,减轻服务器压力
- 访问网站时,浏览器自动将cookie传给服务器
@app.route('/')
def index():
resp = make_response()
# 设置cookie内容
resp.set_cookie('per_page', '10', max_age=86400)
# 删除cookie,本质设置max_age=0
# resp.delete_cookie("per_page")
return resp
1.7.2、Session
特点
- 存储在服务端(服务器的数据库中)
from flask import session
from datetime import timedelta
app = Flask(__name__)
# 使用flask里面的session需要设置加密字符串
app.secret_key = "sdsd232sdd34dfgdfg"
# 设置session有效期
app.permanent_session_lifetime = timedelta(days=1)
@app.route('/index')
def index1():
# 设置session
session["names"] = "jack"
# 使有效期生效
session.permanent = True
# 获取session
session.get("names")
# 删除session
session.pop("names")
session.clear()
return "ok"
1.7.3、状态保持jwt
Json Web Token。本质是一个字符串,将用户信息保存在json字符串中,编码后得到JWT token,且带有签名信息,接收后可以检验是否被篡改。
token身份验证流程
1、客户端使用用户名和密码请求登录
2、服务端接收到用户名和密码,进行验证
3、验证成功,服务端签发一个token,返回给客户端
4、客户端存储起来,放到比如cookie里
5、客户端每次请求都需要携带token,可以在cookie或header中携带
6、服务端收到请求,验证token,向客户端返回请求数据
优点
- 支持跨域,cookie是无法跨域的
- 无状态,服务端不需要存储session信息,减轻服务器压力
- 更适用于CDN
- 适用于移动端
- 无需考虑CSRF,不依赖cookie,不会出现CSRF
pip install pyjwt
flask实现jwt
import jwt
from datetime import timedelta, datetime
@app.route("/login")
def login():
# 格林威治0时区当前时间+2h
expire = datetime.utcnow() + timedelta(hours=2)
# 构建载荷信息
user_dict = {
"user_id": 22,
"username": "xiaoming",
"exp": expire # 过期时间戳 2小时
}
# 构建密钥
key = "python3"
# 生成2小时有效token
token = jwt.encode(payload=user_dict, key=key, algorithm="HS256")
# token = token.decode()
resp = make_response()
resp.headers['Authorization'] = token
return resp
return "login success {}".format(token)
@app.route("/index")
def index():
# 提取请求头中的token
print(request.headers)
token = request.headers.get("Authorization")
# 校验token 获取载荷信息
payload = jwt.decode(token, key="python3", algorithms="HS256")
username = payload.get("username")
user_id = payload.get("user_id")
return "用户ID:{},用户名:{}".format(user_id, username)
增加JWT安全性
- JWT是在请求头中传递的,避免网络劫持,推荐使用https
- JWT的hash签名密钥保存在服务端,保证服务端不被攻破,理论上就是安全的
- JWT可以使用暴力穷举来破解,定期更换服务端的hash密钥(也就是salt)
1.7.4、异常捕获
flask对http进行了封装,可以捕获http错误,也可主动抛出http错误。
from flask import Flask, abort
# 重写404
@app.errorhandler(404)
def error_404(error): # 一旦捕获,要求必须定义形参接收具体错误信息
return "访问的页面不存在"
# 捕获系统内置错误
@app.errorhandler(ZeroDivisionError)
def error_zone(error):
return "除数不能为0"
@app.route("/")
def index():
# abort(404)
# abort(500)
a = 1 / 0
return ""
2、高级用法
2.1、Flask请求钩子
请求钩子可以对请求的各个阶段进行监听,方便对请求完成统一的处理,减少重复代码,类似于Django的中间件。
1、before_request
- 每次执行视图函数之前调用
- 对请求进行准备处理
- 如果在该函数返回响应,视图函数将不会被调用
2、after_request
- 没有抛出异常,在每次视图函数之后之后调用
- 在此函数中对响应值进行近一步修改处理
- 接收一个参数,即包装好的响应对象
- 将修改后的响应对象返回
3、before_first_request
- web应用在第一次请求前被调用
- 进行web应用的初始化操作
4、teardown_request
- 每次执行视图函数之后调用
- 无论是否异常都会执行,一般用于请求收尾
- 接受一个参数,错误信息
- 需要在非调试模式下运行
- 在after_request之后执行
代码实现
@app.before_first_request # 1
def before_first_request():
print('before_first_request')
@app.before_request # 2
def before_request():
print('before_request')
@app.after_request # 3
def after_request(response):
print('after_request')
return response
@app.teardown_request # 4
def teardown_request(e):
print('teardown_request')
装饰器的两种执行方式
方法1:语法糖
@app.teardown_request
方法2:装饰器理解为函数
def index():
pass
app.teardown_request(index)
2.2、蓝图
实现flask项目的模块化。
蓝图实现步骤
- 1、创建蓝图对象,管理子模块
新建python package=>home,修改__init__.py
from flask import Blueprint
# 设置蓝图名称,导包路径
# url_prefix 默认访问路径前缀/home/index
home_bp = Blueprint("home", __name__,url_prefix="/home")
from home import views
- 2、使用蓝图对象绑定路由和视图函数
from home import home_bp
@home_bp.route("/index")
def index():
return "home_page"
- 3、在app中注册蓝图对象
from home import home_bp
app = Flask(__name__)
app.register_blueprint(home_bp)
蓝图其他使用
- 可以使用请求钩子函数,作用域在模块中
- url_for 反解析url url_for("蓝图.函数名") 可得到url
2.3、上下文
是一个数据容器,保存了Flask程序运行过程中的一些信息。
2种:请求上下文和应用上下文。
2种上下文使用范围相同,从请求开始到结束,范围外会失效。
线程隔离。
2.3.1、请求上下文
记录和请求相关的数据,包括request和session 2个变量。
- request 封装了http请求的内容,针对的是http请求。
手动开启请求上下文
with app.request_context():
print(request)
- session 记录请求会话中的信息,针对的是用户信息。
2.3.2、应用上下文
记录和应用相关的数据,包括current_app和g两个变量
- current_app 自动引用创建的Flask对象,需要在项目其他文件中使用app时,应该通过current_app来获取,减少循环导入的问题。
手动开启应用上下文
with app.app_context():
print(current_app)
- g
- flask 会给开发者预留一个容器,记录自定义数据
- g变量每次请求会重置数据
- g使用场景,1)、在钩子函数和视图函数之间传递数据(钩子函数获取信息g.name,然后视图函数g.name获取) 2)、函数嵌套时传递数据
2.4、用户认证案例
2.4.1、统一处理
在钩子函数before_request中统一提取用户信息,保存在g中。视图函数即可获取。
2.4.2、用户权限认证
- 某些功能未登录无法访问,首页未登录显示登录标签。
- 使用装饰器,先装饰路由,再装饰验证
from functools import wraps
# 验证登录的装饰器
def login_requires(view_func):
# 防止装饰器修改被装饰函数的函数名和文档信息
@wraps(view_func)
def wrapper(*args, **kwargs):
# 判断是否登录的逻辑
if g.name:
# 已登录
return view_func(*args, **kwargs)
else:
# 权限验证失败
abort(401)
return wrapper
@app.route("/index")
@login_requires
def index():
return "首页展示"
2.5、Flask应用配置
2.5.1、加载配置
2.5.1.1、app.config
# app.config,用于设置配置,该属性继承dict
app.config["PERMANENT_SESSION_LIFETIME"]=timedelta(days=7)
app.config["DEBUG"]=True
app.config["SECRET_KEY"]="xxx"
app.config["JSON_AS_ASCII"]=False
2.5.1.2、config.py
# 对象中加载配置config.py
# 各种环境配置文件,开发、生产、测试多套环境
from datetime import timedelta
class BaseConfig:
PERMANENT_SESSION_LIFETIME = timedelta(days=7)
SECRET_KEY = "xxx"
JSON_AS_ASCII = False
class DevelopmentConfig(BaseConfig):
"""开发环境"""
DEBUG = True
SQL_URL = "127.0.0.1"
SQL_PORT = 3306
class ProductConfig(BaseConfig):
"""生产环境"""
DEBUG = False
SQL_URL = "192.168.1.1"
SQL_PORT = 3306
SQL_PORT_SLAVE = 3366
class TestConfig(BaseConfig):
"""测试环境"""
DEBUG = True
TESTING = True
CHO_ENV = {
"dev": DevelopmentConfig,
"pro": ProductConfig,
"test": TestConfig,
}
使用config.py文件
配置类中读取
from config import ProductConfig,DevelopmentConfig,TestConfig
app.config.from_object(ProductConfig)
或者
from config import CHO_ENV
app.config.from_object(CHO_ENV.get("env"))
环境变量中读取
app.config.from_envvar()
配置py文件中读取
app.config.from_pyfile()
2.5.2、切换配置
虽然封装了多套环境,但是需要修改代码才可以切换配置,不方便开发和测试。
推荐做法:
- 定义工厂函数,封装应用的创建过程
- 利用环境变量,调用工厂函数,指定配置并动态创建应用
def create_app(config_name):
"""工厂方法"""
app = Flask(__name__)
app.config.from_object(CHO_ENV[config_name])
return app
app = create_app("dev")
# app = create_app("pro")
# 根据不同的传入参数 得到不同的app
2.5.3、加载隐私配置
从环境变量中加载配置,可用于加载隐私配置。
- 通过环境变量指定配置文件的路径
- export ENV_CONFIG="配置文件路径"
- slient=True 即使未配置环境变量也不会报错
- app.config.from_envvar("ENV_CONFIG",slient=True)
2.6、Flask-restful
2.6.1、视图
环境安装
pip install flask-restful
2.6.1.1、构建RESTAPI
from flask_restful import Api, Resource
def create_app(config_name):
"""工厂方法"""
app = Flask(__name__)
app.config.from_object(CHO_ENV[config_name])
return app
app = create_app("dev")
# 1、创建组件对象
api = Api(app)
# 2、定义类视图
class DemoResource(Resource):
def get(self):
# 返回字典,最底层将字典转换为json字符串
return {"get": "get message"}
def post(self):
return "post"
# 3、类视图添加路由信息
# api.add_resource(DemoResource, '/', endpoint="类视图别名")
api.add_resource(DemoResource, '/index')
if __name__ == '__main__':
app.run(debug=True, port=8888, host="0.0.0.0")
2.6.1.2、Restful给类视图添加装饰器
- 装饰器装饰顺序按照列表9-0
1、给类视图所有方法添加装饰器
def my_decrot(func):
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
return wrapper
def my_decrot2(func):
def wrapper(*args, **kwargs):
return func(*args, **kwargs)
return wrapper
app = Flask(__name__)
api = Api(app)
class DemoResource(Resource):
# 装饰器
method_decorators = [my_decrot, my_decrot]
def get(self):
return {"get": "get message"}
def post(self):
return "post"
2、类视图指定方法添加指定装饰器
method_decorators = {
"get": [my_decrot, my_decrot2],
"post": [my_decrot2],
}
2.6.1.3、蓝图和类视图
配合使用的步骤
# 1、创建蓝图对象
蓝图对象 = Blueprint("蓝图名",__name__)
# 2、每个蓝图创建组件对象
组件对象 = Api(蓝图对象)
# 3、组件对象添加类视图
组件对象.add_resource(viewResource,'url路由')
具体案例
# 1、蓝图/__init__.py
from flask import Blueprint
from flask_restful import Api
from . import views
# 设置蓝图名称,导包路径
home_bp = Blueprint("home", __name__, url_prefix="/home")
home_obj = Api(home_bp)
home_obj.add_resource(views.HomeResource, '/index')
from home import views
# 2、蓝图/views.py
from flask_restful import Resource
class HomeResource(Resource):
def get(self):
return {"get": "get msg"}
def post(self):
return {"post": "post msg"}
2.6.2、请求
2.6.2.1、请求解析
- 序列化器功能
- 反序列化
- 参数解析
- 数据保存
- 序列化 - flask-Resuful 实现了类似功能
- 参数解析 RequestParser
- 序列化 marshal函数 - flask-restful没有数据保存的功能,可通过flask-sqlalchemy扩展完成
参数解析RequestParser
# 1 、创建请求解析器
req_parse = RequestParser()
# 2、添加参数规则
req_parse.add_argument(参数名,参数规则...)
- default 给参数设置默认值
- required 必须传递,否则返回400,取值True或False
- location 设置参数提取位置 args/form/json/files/headers/cookies
- type 参数的转换类型或者格式校验
# 3、执行解析
参数对象 = req_parse.parse_args()
# 4、获取参数
参数对象.参数名
from flask_restful import Resource
from flask_restful.reqparse import RequestParser
class HomeResource(Resource):
def get(self):
rpa = RequestParser()
rpa.add_argument("name", type=str, location="args")
rpa.add_argument("age", type=int, location="args")
ret = rpa.parse_args()
print(ret.get("name"))
return {"get": "get msg"}
# 访问地址
localhost:8888/index?name=zs&age=22
2.6.3、响应
2.6.3.1、序列化marshal函数
# 定义序列化规则
序列化规则 = (字段名:序列化类型)
# marshal按照序列化规则,将模型转换为字典
序列化后的字典 = marshal(模型对象,序列化规则)
常见的序列化类型
- String 转换字符串类型属性
- Integer 整数
- Float 浮点
- List 列表,要求列表元素类型一致
- Nested 字典类型
- Boolean 布尔类型
代码实现
- 方法1 marshal
点击查看代码
from flask_restful import fields, marshal
# 1、模型类
class User(object):
def __init__(self):
self.name = "zs"
self.age = 12
self.height = 175.5
self.mylist = [20, 30, 40]
self.mydict = {
"a": 1,
"c": True
}
# 2、序列化规则字典
myshal_dict = {
"name": fields.String(20),
"age": fields.Integer(default=18),
"height": fields.Float(),
"mylist": fields.List(fields.Integer),
"mydict": fields.Nested({
"a": fields.Integer,
"c": fields.Boolean,
})
}
class HomeResource(Resource):
def get(self):
# 3、创建用户对象
user = User()
# 4、利用marshal函数,将对象序列化成字典
mym = marshal(user, myshal_dict)
return mym
- 方法2 marshal_with
点击查看代码
from flask_restful import fields,marshal_with
# 1、模型类(已经实例化)
class User(object):
def __init__(self):
self.name = "zs"
self.age = 12
self.height = 175.5
self.mylist = [20, 30, 40]
self.mydict = {
"a": 1,
"c": True
}
# 2、序列化规则字典
myshal_dict = {
"name": fields.String(20),
"age": fields.Integer(default=18),
"height": fields.Float(),
"mylist": fields.List(fields.Integer),
"mydict": fields.Nested({
"a": fields.Integer,
"c": fields.Boolean,
})
}
class HomeResource(Resource):
method_decorators = {
"post": [marshal_with(myshal_dict)]
}
def post(self):
user = User()
return user
- 方法3 推荐
在模型类定义转字典的方法
2.6.3.2、自定义json
- 字典转换json的方法,output_json,包裹成json返回。
- 复制output_json源码,使用装饰器api.representation(mediatype="application/json") # 返回参数类型
- 拦截返回的字典数据,再在复制出来的output_json方法里进行修改
# output_json放到utils/output_json.py文件里
from util import output_json
api.representation(mediatype="application/json")(output_json)
# 下面的类视图都可以使用到
2.7、单例模式
单例--只需要初始化一个对象的方案。如数据库链接。
优点
- 只会保留一个对象,减少系统开销
- 提高创建速度,每次获取已经存在的对象,全局共享对象
- 在系统中只存在一个对象实例,避免多实例创建使用产生的逻辑错误
2.7.1、实现单例
1、重写__new__方法
class Singleton(object):
# __new__方法在__init__方法调用前被调用
def __new__(cls, *args, **kwargs):
if not hasattr(cls, "_instance"):
# 创建对象保存到类上,调用父类的方法
cls._instance = super(Singleton, cls).__new__(cls, *args, **kwargs)
# 业务内容 初始化
# cls._instance.rest=REST(_serverIP,_serverPort,_softVersion)
# cls._instance.rest.setAccount(_accountSid,_accountToken)
# cls._instance.rest.setAppId(_appId)
cls._instance.name = "zhangsan"
return cls._instance
def send_sms(self):
# 执行发送
result = self.name
return ""
if __name__ == '__main__':
s1 = Singleton()
print(s1.send_sms())
s2 = Singleton()
print(id(s1))
print(id(s2))
# 同一个id
2、装饰器实现单例
# 装饰器实现单例
from threading import Lock
def singleton(cls):
instance = {}
instance_lock = Lock()
def wrapper(*args, **kwargs):
if cls not in instance:
# 使用锁保证只创建一个对象
with instance_lock:
instance["cls"] = cls(*args, **kwargs)
return instance(cls)
return wrapper
@singleton
class Foo(object):
def __init__(self):
name = "zhangsan"
def send_sms(self):
result = self.name
return ""
foo1 = Foo()
foo1.send_sms()
2.8、Flask-SQLALchemy扩展
2.8.1、基本使用
安装
pip install flask-sqlalchemy
若是安装失败,提示No module named 'MySQLdb',需要尝试下面方案
- pip install mysqlclient
- pip install pymysql
基本配置
配置项
| SQLALCHEMY_DATABASE_URI | 数据库连接地址 |
|---|---|
| SQLALCHEMY_BINDS | 访问多个数据库时,用于设置数据库连接地址 |
| SQLALCHEMY_ECHO | 是否打印底层执行的SQL |
| SQLALCHEMY_RECORD_OUERIES | 是否记录执行的查询语句,用于慢查询分析,调试模式下自动启动 |
| SQLALCHEMY_TRACK_MODIFICATIONS | 是否追踪数据库变化(触发钩子函数),会消耗额外的内存 |
| SQLALCHEMY_ENGINE_OPTIONS | 设置针对sqlalchemy本体的配置项 |
数据库URL
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:密码@127.0.0.1:3306/数据库名"
- 数据库驱动使用pymysql,协议名改为mysql+pymysql://root:密码@127.0.0.1:3306/数据库名
- sqlalchemy支持多种关系型数据库
2.8.2、数据操作
1)、add 新增
@app.route("/add")
def add_user():
# 创建模型对象
u1 = User(name="zhangsan", age=22)
# u1.name = "lisi"
# u1.age = 33
# 模型对象添加到会话中
db.session.add(u1)
# 添加多条
# db.session.add_all([u1,u2,u3])
# 提交会话
db.session.commit()
# 手动回滚 默认自动回滚
db.session.rollback()
return "add ok"
2)、select 查询
常见的查询执行器
- all() 返回列表
- count() 返回查询结果数量
- first() 返回查询到的第一个模型对象,没有返回None
- first_or_404() 返回查询到的第一个模型对象,没有返回404
- get(主键) 返回主键对应的模型对象,不存在返回None
- get_or_404() 返回主键对应的模型对象,不存在返回404
- paginate(页码,每页条数) 返回paginate对象,包含分页查询的结果
# 分页 每页3条,查询第二页数据
p = User.query.paginate(2, 3)
# p.page # 当前页数
# p.pages # 总页数
# p.items # 数据
常见的查询过滤器
- filter_by(字段名=值)
# 指定用户表
User.query.filter_by(id=4).first() - filter(函数引用/比较运算)
# filter全局查询
User.query.filter(User.id == 4).first()
# 以什么结尾
User.query.filter(User.name.endswith("san"))
# 以什么开头
User.query.filter(User.name.startswith("zhang"))
# 内容包含什么
User.query.filter(User.name.contains("zh"))
# 模糊匹配 不推荐
User.query.filter(User.name.like("z%s"))
# 逻辑操作
# 与操作1
User.query.filter(User.name.startswith("zhang"), User.age == 33)
# 与操作2
from sqlalchemy import and_, or_, not_
User.query.filter(and_(User.name.startswith("zhang"), User.age == 33))
# 或操作
User.query.filter(or_(User.name.startswith("zhang"), User.age == 33))
# 非操作
User.query.filter(not_(User.name == "zhangsan")).all()
User.query.filter(User.name != "zhangsan").all()
# in操作
User.query.filter(User.id.in_([1, 3, 5, 7])).all()
- limit(限定条数)
- offset(偏移条数)
- order_by(排序字段)
# 排序 并取前5个
User.query.order_by(User.age, User.id.desc()).limit(5).all()
# 排序,取2-5位4个数据
User.query.order_by(User.age).offset(1).limit(4).all()
- group_by(分组字段)
- options() 针对原查询限定查询的字段
# 优化select * ,指定字段查询
from sqlalchemy.orm import load_only
User.query.options(load_only(User.name, User.age)).all()
返回的内容在模型中不存在,需要使用db.session.query
from sqlalchemy import func
# 各个年龄的个数
uu = db.session.query(User.age, func.count(User.name).label("count")).group_by(User.age).all()
# label 是取别名
3)、update 更新
- 先查询,再更新
u1 = User.query.filter(User.name == "zhangsan").first()
u1.name = "ZHANGSAN"
# db.session.add(u1) 默认可不加
db.session.commit()
- 基于过滤条件的更新
User.query.filter(User.name == "ZHANGSAN").update({
"age": 2222
})
4)、delete 删除
- 先查询,再删除
u1 = User.query.filter(User.name == "zhangsan").first()
db.session.delete(u1)
db.session.commit()
- 基于过滤条件的删除
User.query.filter(User.name == "ZHANGSAN").delete()
db.session.commit()
5)、索引
建立索引增加了查询速度,降低了增删改的速度。
字段内容经常被增删改,不建议作为索引。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律