hive入门二
一、hive配置修改
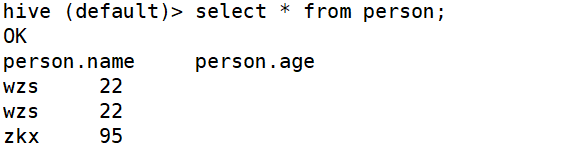
1、在hive-site.xml文件中添加如下配置信息,就可以实现显示当前数据库,以及查询表的头信息配置。


<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
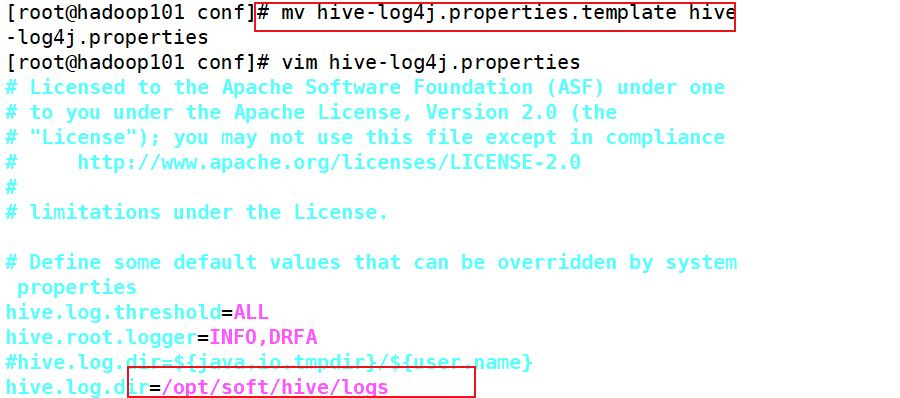
2、Hive的log默认存放在/tmp/atguigu/hive.log目录下(当前用户名下)修改hive的log存放日志到/opt/module/hive/logs
(1)修改/opt/module/hive/conf/hive-log4j.properties.template文件名称为hive-log4j.properties
(2)在hive-log4j.properties文件中修改log存放位置hive.log.dir=/opt/module/hive/logs
二、hive的数据类型
1、基本数据类型
|
Hive数据类型 |
Java数据类型 |
长度 |
例子 |
|
TINYINT |
byte |
1byte有符号整数 |
20 |
|
SMALINT |
short |
2byte有符号整数 |
20 |
|
INT |
int |
4byte有符号整数 |
20 |
|
BIGINT |
long |
8byte有符号整数 |
20 |
|
BOOLEAN |
boolean |
布尔类型,true或者false |
TRUE FALSE |
|
FLOAT |
float |
单精度浮点数 |
3.14159 |
|
DOUBLE |
double |
双精度浮点数 |
3.14159 |
|
STRING |
string |
字符系列。可以指定字符集。可以使用单引号或者双引号。 |
‘now is the time’ “for all good men” |
|
TIMESTAMP |
|
时间类型 |
|
|
BINARY |
|
字节数组 |
2、集合数据类型
|
数据类型 |
描述 |
语法示例 |
|
STRUCT |
和c语言中的struct类似,都可以通过“点”符号访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第1个元素可以通过字段.first来引用。 |
struct() |
|
MAP |
MAP是一组键-值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是MAP,其中键->值对是’first’->’John’和’last’->’Doe’,那么可以通过字段名[‘last’]获取最后一个元素 |
map() |
|
ARRAY |
数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘John’, ‘Doe’],那么第2个元素可以通过数组名[1]进行引用。 |
Array() |
3、案例
1、假设某表有如下一行,我们用JSON格式来表示其数据结构。在Hive下访问的格式为
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //列表Array,
"children": { //键值Map,
"xiao song": 18 ,
"xiaoxiao song": 19
}
"address": { //结构Struct,
"street": "hui long guan" ,
"city": "beijing"
}
}
2、基于上述数据结构,我们在Hive里创建对应的表,并导入数据。创建本地测试文件people
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
3、建表
create table people(name string,friends array<string>,
children map<string,int>,
address struct<street:string,city:string>)
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';

三、建库
一、库的常见操作
1.增
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment] // 库的注释说明
[LOCATION hdfs_path] // 库在hdfs上的路径
[WITH DBPROPERTIES (property_name=property_value, ...)]; // 库的属性
create database if not exists mydb2
comment 'this is my db'
location 'hdfs://hadoop101:9000/mydb2'
with dbproperties('ownner'='jack','tel'='12345','department'='IT');
2.删
drop database 库名: 只能删除空库
drop database 库名 cascade: 删除非空库
3.改
use 库名: 切换库
dbproperties: alter database mydb2 set dbproperties('ownner'='tom','empid'='10001');
同名的属性值会覆盖,之前没有的属性会新增
4.查
show databases: 查看当前所有的库
show tables in database: 查看库中所有的表
desc database 库名: 查看库的描述信息
desc database extended 库名: 查看库的详细描述信息
四、建表
一、表操作
1.增
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)] //表中的字段信息
[COMMENT table_comment] //表的注释
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format] // 表中数据每行的格式,定义数据字段的分隔符,集合元素的分隔符等
[STORED AS file_format] //表中的数据要以哪种文件格式来存储,默认为TEXTFILE(文本文件)
可以设置为SequnceFile或 Paquret,ORC等
[LOCATION hdfs_path] //表在hdfs上的位置
①建表时,不带EXTERNAL,创建的表是一个MANAGED_TABLE(管理表,内部表)
建表时,带EXTERNAL,创建的表是一个外部表!
外部表和内部表的区别是:
内部表(管理表)在执行删除操作时,会将表的元数据(schema)和表位置的数据一起删除!
外部表在执行删除表操作时,只删除表的元数据(schema)
在企业中,创建的都是外部表!
在hive中表是廉价的,数据是珍贵的!
建表语句执行时:
hive会在hdfs生成表的路径;
hive还会向MySQl的metastore库中掺入两条表的信息(元数据)
管理表和外部表之间的转换:
将表改为外部表: alter table p1 set tblproperties('EXTERNAL'='TRUE');
将表改为管理表: alter table p1 set tblproperties('EXTERNAL'='FALSE');
注意:在hive中语句中不区分大小写,但是在参数中严格区分大小写!
2.删
drop table 表名:删除表
3.查
desc 表名: 查看表的描述
desc formatted 表名: 查看表的详细描述
