MR-求每年最高气温
一、要求:求每年最高气温,原始数据如下:
2014010114 2014010216 2014010317 2014010410 2014010506 2012010609 2012010732 2012010812 2012010919 2012011023 2001010116 2001010212 2001010310 2001010411 2001010529 2013010619 2013010722 2013010812 2013010929 2013011023 2008010105 2008010216 2008010337 2008010414 2008010516 2007010619 2007010712 2007010812 2007010999 2007011023 2010010114 2010010216 2010010317 2010010410 2010010506 2015010649 2015010722 2015010812 2015010999 2015011023
二、源代码
TempMapper.java


package com.me.sy1; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class TempMapper extends Mapper<LongWritable, Text,Text, IntWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { Text out_ket = new Text(); IntWritable out_value = new IntWritable(); String line= value.toString(); String year=line.substring(0,4); int temperature=Integer.parseInt(line.substring(8)); out_ket.set(year); out_value.set(temperature); context.write(out_ket,out_value); } }
TempReduce.java
package com.me.sy1; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class TempReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int maxValue = Integer.MIN_VALUE; StringBuffer sb = new StringBuffer(); //取values的最大值 for (IntWritable value : values) { maxValue = Math.max(maxValue, value.get()); sb.append(value).append(", "); } context.write(key, new IntWritable(maxValue)); } }
TempDriver.java
package com.me.sy1; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TempDriver { public static void main(String[] args) throws Exception { Path inputPath=new Path("/yjs/sy1"); Path outputPath=new Path("/yjs/sy1/out"); //作为整个Job的配置 Configuration conf = new Configuration(); // 分隔符只是一个byte类型的数据,即便传入的是个字符串,只会取字符串的第一个字符 conf.set("mapreduce.input.fileinputformat.split.maxsize", "20480000"); conf.set("fs.defaultFS", "hdfs://192.168.1.100:9000"); // 在YARN上运行 conf.set("mapreduce.framework.name", "yarn"); // RM所在的机器 conf.set("yarn.resourcemanager.hostname", "192.168.1.101"); // 设置输入格式 conf.set("mapreduce.job.inputformat.class", "org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat"); //保证输出目录不存在 FileSystem fs=FileSystem.get(conf); if (fs.exists(outputPath)) { fs.delete(outputPath, true); } // ①创建Job Job job = Job.getInstance(conf); // 告诉NM运行时,MR中Job所在的Jar包在哪里 job.setJar("yjs-1.0-SNAPSHOT.jar"); //jar 包的驱动类 job.setJarByClass(TempDriver.class); // 为Job创建一个名字 job.setJobName("temp"); // ②设置Job // 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型 job.setMapperClass(TempMapper.class); job.setReducerClass(TempReducer.class); // Job需要根据Mapper和Reducer输出的Key-value类型准备序列化器,通过序列化器对输出的key-value进行序列化和反序列化 // 如果Mapper和Reducer输出的Key-value类型一致,直接设置Job最终的输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 声明使用NLineInputFormat //job.setInputFormatClass(NLineInputFormat.class); // 设置输入目录和输出目录 FileInputFormat.setInputPaths(job, inputPath); FileOutputFormat.setOutputPath(job, outputPath); // ③运行Job job.waitForCompletion(true); } }
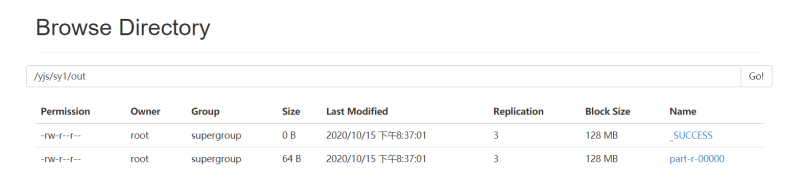
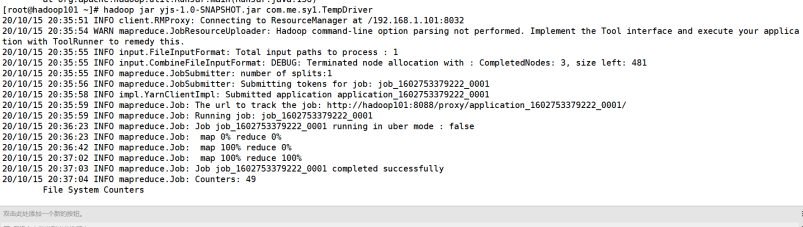
三、结果