
python数据分析之人力资源分析
一、数据描述
1.数据字段及解释
- left:是否离职
- satisfaction_level:满意度
- last_evaluation:绩效评估
- number_project:完成项目数
- average_montly_hours:平均每月工作时间
- time_spend_company:为公司服务的年限
- work_accident:是否有工作事故
- promotion:过去5 年是否有升职
- salary:薪资水平
2.导入数据
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline df=pd.read_csv('I:\HR_comma_sep.csv')

共有14999条数据,这里代码默认展示前五行
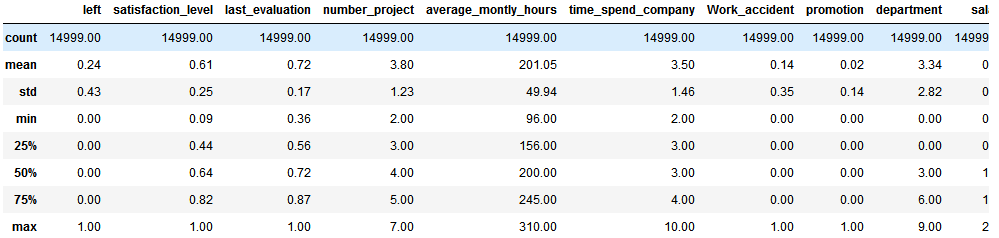
##看一下整体数据,大概有76%的人留下了,24%的人离开了 left_rate=df.left.value_counts()/14999 0 0.761917 1 0.238083 Name: left, dtype: float64
二、提出问题
1、失去优秀员工会让公司产生多大损失?招新人和优秀老员工之间的成本与变现孰轻孰重?
2、什么原因产生了较低的满意度?
3、为什么离开的员工平均比没有离开的员工得到更高的评价,甚至是项目数量的增加?低评价的员工不应该更倾向于离开公司吗?
三、数据清洗和预处理
##检查是否有缺失值 df.isnull().any() satisfaction_level False last_evaluation False number_project False average_montly_hours False time_spend_company False Work_accident False left False promotion_last_5years False sales False salary False dtype: bool
##适当改名,方便选取列 df = df.rename(columns={'satisfaction_level': 'satisfaction_level', 'last_evaluation': 'last_evaluation', 'number_project': 'number_project', 'average_montly_hours': 'average_montly_hours', 'time_spend_company': 'time_spend_company', 'Work_accident': 'Work_accident', 'promotion_last_5years': 'promotion', 'sales' : 'department', 'left' : 'left' })
##由于“部门”和“薪金”的功能是明确的,我将把它转换为数值,以便更好地分析。 ##分别查看department列和salary列唯一值有多少个 df1=pd.Series(df['department']).unique() df2=pd.Series(df['salary']).unique()
##把两列的值转化为数值 df['department'].replace(list(pd.Series(df['department']).unique()),np.arange(10),inplace=True) df['salary'].replace(list(pd.Series(df['salary']).unique()),[0,1,2],inplace=True)
##把left列移到表的前面,方便分析 front=df['left'] df.drop(labels='left',axis=1,inplace=True) df.insert(0,'left',front) df.head()
四、数据可视化
1.相关性分析
sns.heatmap(corr,xticklabels=corr.columns.values,yticklabels=corr.columns.values); sns.plt.title('Heatmap of Correlation Matrix')
(+)number_project&average_montly_hours&last_evaluation
(-)left&satisfaction_level&salary
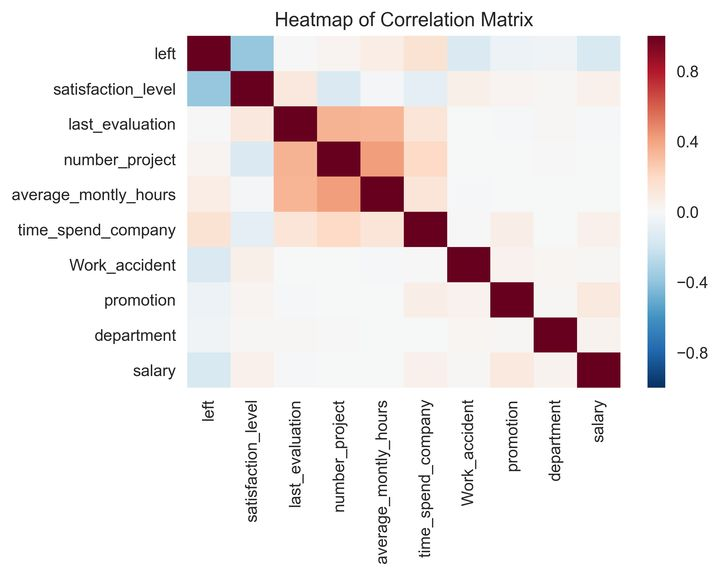
从热图上看,有大的正(+)相关性的有,完成项目数(number_project)和平均月度工作时间(average_montly_hours),它们分别和绩效评估有较大的正相关,这可能意味着花了更多时间和做了更多项目的员工得到了高度评价。但是,绩效评估与响应变量转换之间几乎没有相关关系,也就是说绩效评估的高度评价没有转换到薪资水平和升职上来,只是得到了好的评价而已,对于负(-)关系,离职率、满意度和薪水是高度相关的。我们假设员工在不太满意投入产出比的情况下往往会离开公司。
2.变量分析
##department vs left depart_left_table=pd.crosstab(index=df['department'],columns=df['left']) ##职位:'sales', 'accounting', 'hr', 'technical', 'support', 'management','IT', 'product_mng', 'marketing', 'RandD' depart_left_table.plot(kind='bar',figsize=(5,5),stacked=True) ##department vs salary depart_salary_table=pd.crosstab(index=df['department'],columns=df['salary']) depart_salary_table.plot(kind="bar",figsize=(5,5),stacked=True) ##salary vs left salary_left_table=pd.crosstab(index=df['salary'],columns=df['left']) salary_left_table.plot(kind='bar',figsize=(5,5),stacked=True) ##promotion vs left promotion_left_table=pd.crosstab(index=df['promotion'],columns=df['left']) promotion_left_table.plot(kind='bar',figsize=(5,5),stacked=True) ##number_project vs left project_left_table=pd.crosstab(index=df['number_project'],columns=df['left']) project_left_table.plot(kind='bar',figsize=(5,5),stacked=True) df.loc[(df['left']==1),'number_project'].plot(kind='hist',normed=1,bins=15,stacked=False,alpha=1) ##time_spend_company vs left company_left_table=pd.crosstab(index=df['time_spend_company'],columns=df['left']) company_left_table.plot(kind='bar',figsize=(5,5),stacked=True) df.loc[(df['left']==1),'time_spend_company'].plot(kind='hist',normed=1,bins=10,stacked=False,alpha=1) ##average_montly_hours vs left hours_left_table=pd.crosstab(index=df['average_montly_hours'],columns=df['left']) fig=plt.figure(figsize=(10,5)) letf=sns.kdeplot(df.loc[(df['left']==0),'average_montly_hours'],color='b',shade=True,label='no left') left=sns.kdeplot(df.loc[(df['left']==1),'average_montly_hours'],color='r',shade=True,label='left') ##last_evaluation vs left evaluation_left_table=pd.crosstab(index=df['last_evaluation'],columns=df['left']) fig=plt.figure(figsize=(10,5)) left=sns.kdeplot(df.loc[(df['left']==0),'last_evaluation'],color='b',shade=True,label='no left') left=sns.kdeplot(df.loc[(df['left']==1),'last_evaluation'],color='r',shade=True,label='left') ##satisfaction_level vs left satis_left_table=pd.crosstab(index=df['satisfaction_level'],columns=df['left']) fig=plt.figure(figsize=(10,5)) left=sns.kdeplot(df.loc[(df['left']==0),'satisfaction_level'],color='b',shade=True,label='no left') left=sns.kdeplot(df.loc[(df['left']==1),'satisfaction_level'],color='r',shade=True,label='left') ##last_evaluation vs satisfaction_level df1=df[df['left']==1] fig, ax = plt.subplots(figsize=(10,10)) pd.scatter_matrix(df1[['satisfaction_level','last_evaluation']],color='k',ax=ax) plt.savefig('scatter.png',dpi=1000,bbox_inches='tight')
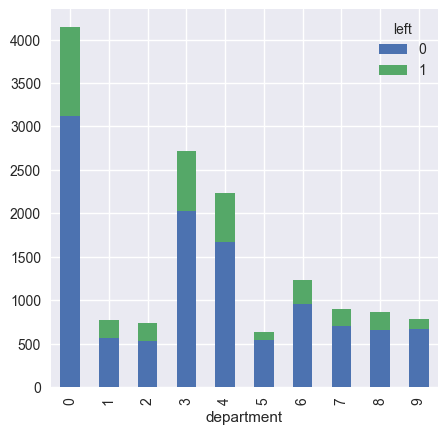
- department vs left
职位分别是:'sales', 'accounting', 'hr', 'technical', 'support', 'management','IT', 'product_mng', 'marketing', 'RandD'
公司职位基本对应业务支持,技术,和销售。大多数部门的离职率相似,也就管理层和研发低一些,但管理层离职率最低。这可能意味着地位较高的人倾向于不离开。
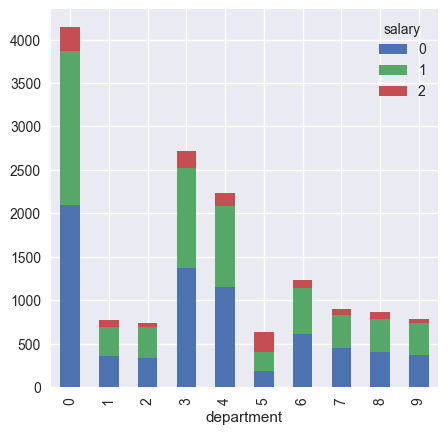
- department vs salary
可以看出管理层的薪资最高,离职率最低
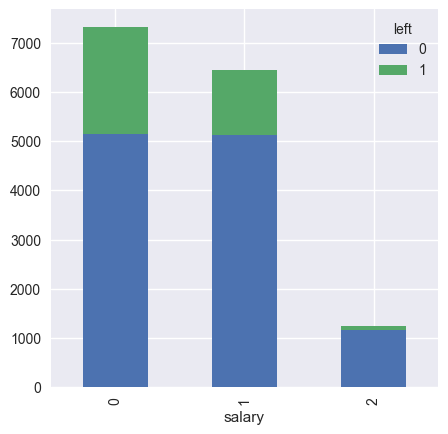
- salary vs left
很形象的看出,离职的员工薪资几乎都在低到中等水平,很少有高新的员工离开公司。
- promotion vs left
在离职的员工中几乎都没有得到升职。

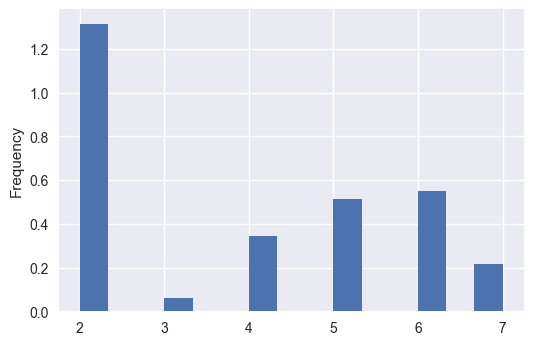
- number_project vs left
本图显示超过一半的员工只有2个项目就离开了公司,但同样有从4-7个项目统计的员工离开。我们可以猜测一下,也许这意味着,项目数量在2或更少的员工工作不够,或者没有被高度重视,从而离开了公司?6个项目以上员工会过度劳累,从而离开公司?3个项目的员工离职率最低。

- time_spend_company vs left
离职员工在离职前大部分在公司已经工作了3-6年,在公司工作7-10年的员工没有人离开。

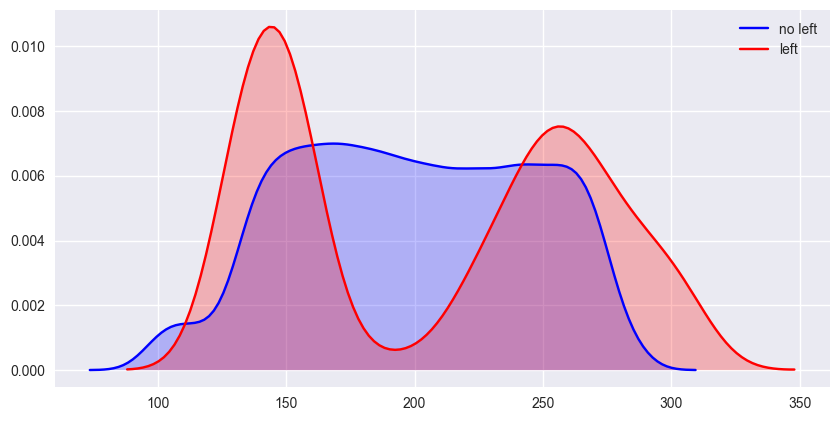
- average_montly_hours vs left
是一个很明显的双峰分布,说明员工平均每月工作时间少的(低于150小时)和工作时间多的(高于250小时)的员工离职率最高。
所以一般离开公司的员工要么工作时间少的,要么过度工作的。
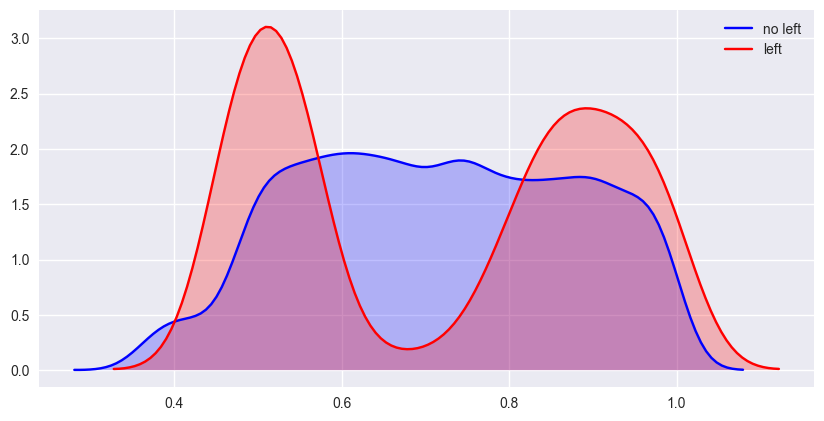
- last_evaluation vs left
又是一个双峰分布,表现糟糕的和表现出色的出现了离职的两个峰值,根据前边的分析,效绩评估出色的员工,公司没有相应的转化到升职和薪资上。0.6-0.8之间有比较好的员工留存。
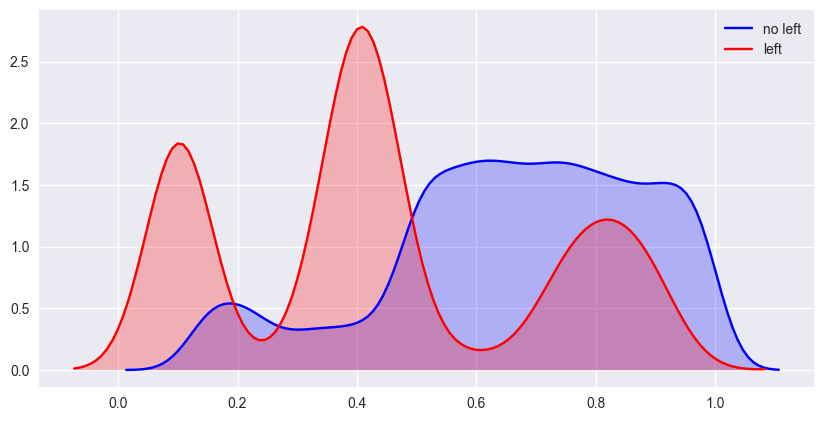
- satisfaction_level vs left
出现了三个峰值,满意度低于0.1的员工基本离职,满意度在0.3-0.5之间离开的员工又到达一个峰值,满意度在0.8左右时,又出现了一个峰值,这些是满意度较高的员工,这些员工可能找到了更好的工作机会,离职不是对公司不满,这些员工对公司是有比较高的满意度的。
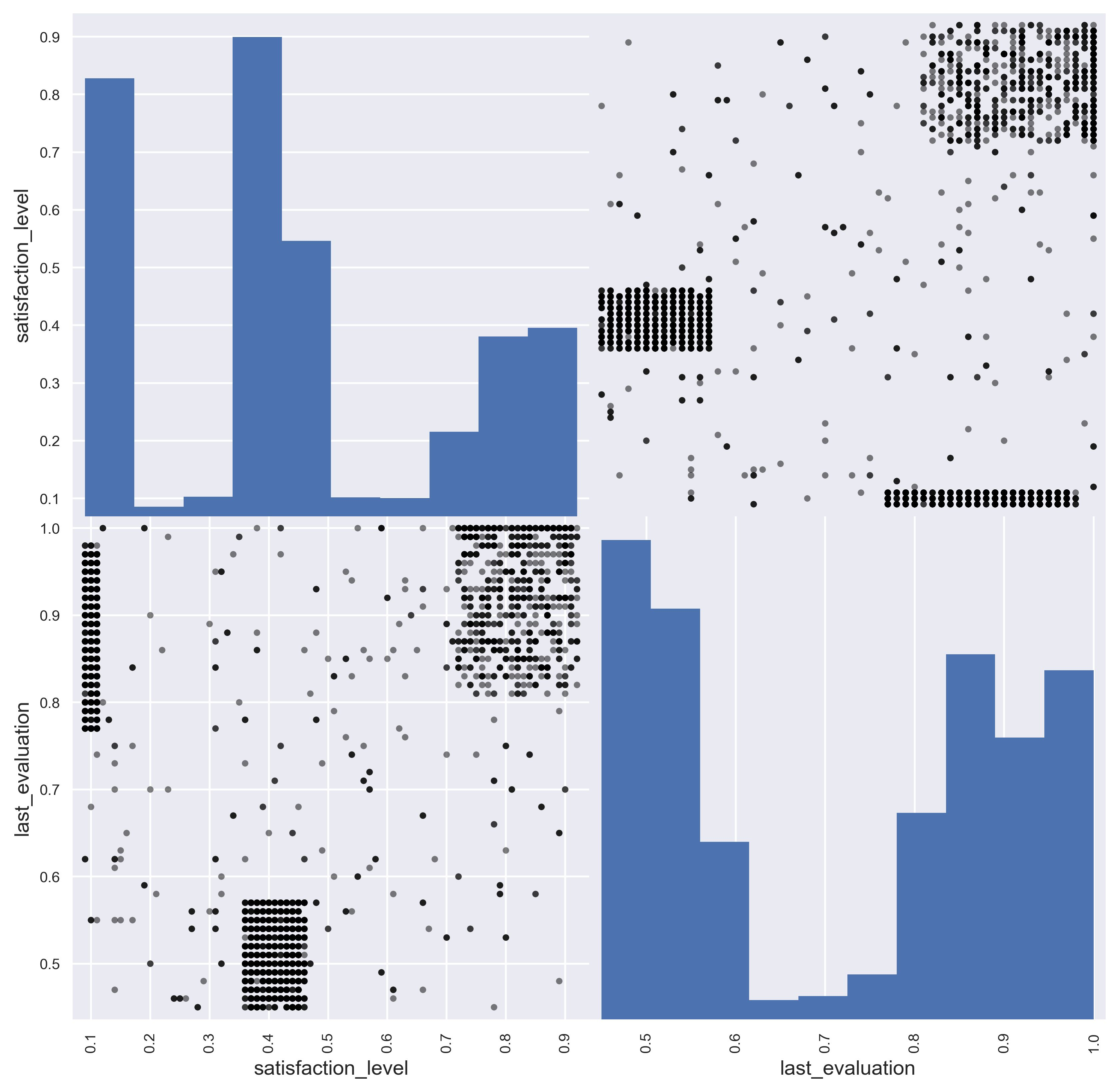
- last_evaluation vs satisfaction_level
在绩效评估与满意度的散射矩阵中,可以看到有三个不同的集群。
集群1:满意度低于0.2,绩效评估大于0.75,这可以很好地表明离开公司的员工都是好员工,但对自己的工作感到不满意,当你受到高度评价的时候,这个集群应该代表着“过度劳累”的员工。
集群2:满意度在0.35~0.45之间,绩效评估在0.58以下,这可以被看作是雇员受到了不太好的评价,这可能意味着这些员工表现不好,所以员工自己的满意度也不好,这个集群代表着表现不佳的员工。
集群3:满意度在0.7~1之间,评价大于0.8,这可能意味着这个集群的员工是最理想的,他们热爱他们的工作,公司对他们的表现评价很高,这个类别的员工离开可能是因为他们找到了另一个工作机会。
五、总结
员工离职概述:
离职员工工作时间大部分是~6hours /天(工作)和~10小时/天(劳累);
大部分离职员工薪资都在low~medium这一档,薪资水平低;
离职员工,几乎都没有得到升职;
大多数离职员工的评价分数在0.6以下和0.8以上;
离职员工大多数有2个项目,但同样有4-7个项目的员工离开,3个项目的员工离职率最低;
完成项目数,每月平均工作时间,绩效评估有正相关关系。意味着你工作越多,得到的评价就越高;
离职率、满意度与薪酬呈负相关关系。这意味着较低的满意度和工资产生了较高的离职率;
优秀员工看中的是良好的待遇,和更好的职业发展,这些因素都直接影响员工的主观感受,公司给予了员工高的评价,但没有相应转化到薪资和升职的变量中,即使一部分离职的优秀员工给予了公司不错的满意度,但依然不能阻挡他们会追寻更好的工作机会。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号