

20165324 《Java程序设计》 第六周
学号 2016-2017-2 《Java程序设计》第六周学习总结
教材学习内容总结
第八章 常用实用类
String类
- 构造String对象:常量对象;String对象;引用String常量。
- 字符串的并置:String对象使用“+”进行并置运算,即首尾相接。
- String类的常用方法
public int length():获取String对象的长度。public boolean equals(String s):比较当前String对象的字符序列是否与参数s指定的String对象的字符序列相同。public boolean startsWith(String s):判断当前String对象的字符序列的前缀是否与参数指定的String对象s一致。public boolean endsWith(String s):判断当前String对象的字符序列的后缀是否与参数指定的String对象s一致。public int compareTo(String s):按字典序与参数指定的String对象S的字符序列比较大小。public boolean contains(String s):判断当前String对象的字符序列是否包含参数s的字符序列。public int indexOf(String s):从当前String对象的字符序列的0索引位置开始检索首次出现s的字符序列的位置,返回该位置。若无法检索到,则返回-1。注:indenxOf(String str,int startpoint)方法是一个重载方法,可以指定检索开始的位置。空格也要占一个字符序列的位置。public int lastIndexOf(String s):从当前String对象的字符序列的0索引位置开始检索最后一次出现s的字符序列的位置,返回该位置。若无法检索到,则返回-1。public String substring(int startpoint,int end):调用方法获得一个新的String对象,新的String对象是复制当前startpoint位置至end-1位置的字符序列。也可以省略end,复制startpoint至结尾的所有字符序列。
- 字符串与基本数据的相互转化:
public static String valueOf(byte/int/long/float/double n)将上述类型转换为String对象。 - 对象的字符串表示:Object类有一个
public String toString()方法,一个对象通过调用该方法可以获得该对象的字符串表示。返回的形式为:创建对象的类的名字@对象的引用的字符串表示。 - 字符串与字符数组、字节数组。
- 字符串与字符数组举例说明:
String s="1945年8月15日是抗战胜利日";
char []a=new char[4];
s.getChars(11,15,a,0);//数组a的单元依次放的字符是抗 战 胜 利
char []c;
c="睡觉".toCharArray();//数组c的单元依次放的字符是 睡 觉
- 字符串与字节数组:String类的构造方法
String (byte[],int offset,int length),从数组起始位置offset开始取length个字节,构造一个String对象。 - 字符的加密算法:若加密算法为做加法运算,则解密算法为减法运算。
- 正则表达式及字符串的替换与分解
- 正则表达式是一个String对象的字符序列,该字符序列中含有具有特殊意义的字符,这些特殊字符称为正则表达式的元字符。
- 元字符如图:
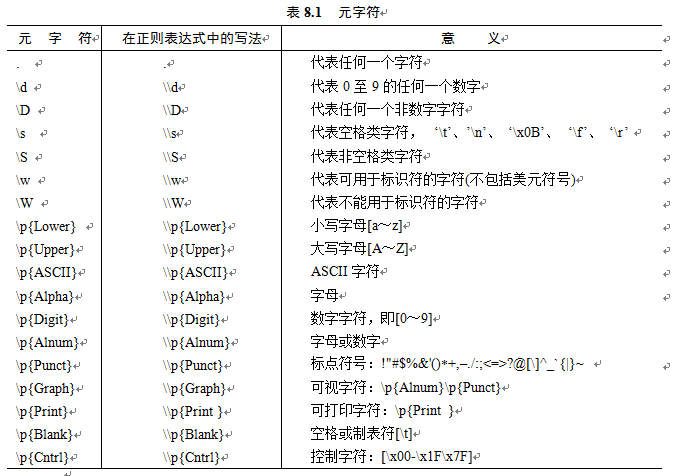
- 限定符如图:
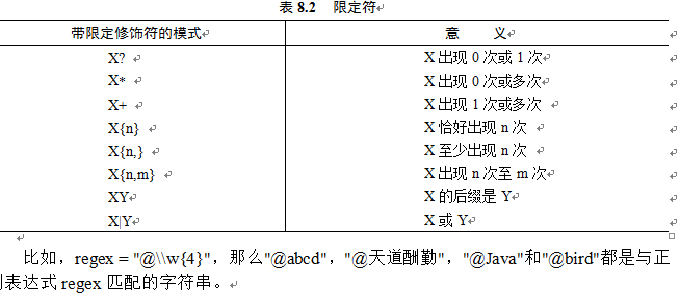
- 字符串的替换:
public String replaceAll(String regex,String replacement),调用方法返回一个新的String对象,新的String对象的字符序列是把当前对象字符序列中所有和参数regex相匹配的子字符序列,用参数replacament的字符序列替换后得到的新的字符序列,但不影响当前String对象的字符序列。 - 字符序列的分解:
public String[]split(String regex):String对象调用该方法时,使用参数指定的正则表达式regex作为分隔标记分解出当前String对象的字符序列中的单词,并将分解出的单词存放在String数组中,如:
String str="1949年10月1日建国";
String regex="\\D+";//匹配任何非数字字符序列
String digitWord[]=str.split(regex);//digitWord[]存放的为:1949 10 1
StringTokenizer类
- 用于将字符序列分解成可被独立使用的单词时,使用该对象。StringTokenizer有两个构造方法:
-
StringTokenizer(String s),使用默认的分隔标记,即空格符,换行符,回车符,Tab符等等。 -
StringTokenizer(String s,String delim):参数delim的字符序列的字符的任意排列被作为标记符。 -
具体使用步骤:
(1)设置分隔标记regex。
String s=(正则表达式);(2)replaceAll方法的调用。
s=s.replaceAll(regex,"#");(3)使用StringTokenizer创建分析器。
StringTokenizer fenxi=new StringTokenizer(s,"#");(4)获取分线器中计数变量的值。
int amount=fenxi.countTokens();(5)取出分析器中的String单元,使用数组或其他方式存储。
double a[]=new double [amount]; String m; for (int i=0;i<n;i++) { m=fenxi.nextToken(); a[i]=Double.parseDouble(m); } while(fenxi.hasMoreTokens()) { String item = fenxi.nextToken(); double price = Double.parseDouble(item); } ```
Scanner类
- Scanner对象可以调用正则表达式作为分隔标记,即让Scanner对象在解析操作时,把与正则表达式匹配的字符序列作为分隔标记。默认使用空白字符作为分隔标记来解析String对象的字符序列的单词。
Scanner sc=new Scanner(String s);
sc.useDelimiter(正则表达式);
优先使用StringTokenize类,进行String对象的分解
StringBuffer类
- StringBuffer类的对象的实体的存储空间可以自动的改变大小,便于存放。
StringBuffer s=new StringBuffer("我喜欢"); s.append("Java") - StringBuffer有三个构造方法。
- StringBUffer类的常用方法
- append方法
public char charAt(int n)和public void setCharAt(int n,char ch)StringBuffer insert(int index,String str)public StringBuffer reverse()StringBuffer delete(int startIndex,int endIndex)StringBUffer replace(int startIndex,int endIndex,String str)
Date类与Calendar类
- Date类:
Date nowTime=new Date();:获取当前时间。 - 带参数的构造方法。
- Calendar类学习参考Dome15
日期的格式化
- 使用String类调用format方法对日期格式化:
format(格式化模式,日期列表);
Math类、BigInteger类和Random类
- Math类常用方法:
public static long abs(double a):返回绝对值。public static double max/min(double a,double b):返回两个数中最大/小的数。public static double random():产生一个0~1之间的随机数([0,1))。public static double sqrt(double a):返回a的平方根。
- BigInteger类:处理特别大的整数。常用方法暂时不用。
- Random类:生成随机数。
数字格式化
- 参照C语言。
第十五章 泛型与集合框架
泛型
- 泛型:目的为建立具有类型安全的集合框架。
- 泛型类声明:
class People<E> class 名称<泛型列表>
链表
-
定义:若干个结点的对象组成的一种数据结构。
-
LinkedList
泛型类:创建链表对象。 -
常用方法:
public boolean add(E element),链表末尾添加结点。public void add(int index,E element),向链表指定位置添加一个结点。public void clean(),删除链表结点。public E get(int index),得到链表中指定位置的结点中的数据。public E set(int index,E element),将当前链表index位置的结点的数据替换为参数element指定的数据,并返回被替换的数据。public int size(),返回链表的长度,即结点 个数。
-
遍历结点:链表对象可以使用Iterator()方法获取一个Iterator对象,该对象就是针对当前链表的迭代器。
Iterator<Integer> iter=list.iterator();
- 排序和查找:Colleations类提供的用于排序和查找的类方法如下:
public static sort(List<E> list),该方法将list中的元素升序排列。int binarySearch(List<E> list,T key,CompareTo<T> c),使用折半法查找,成功返回索引位置,否则返回-1.
- 洗牌与旋转:Collections类还提供了将链表中的数据重新随机排列的类方法以及旋转链表中数据的类方法。
public static void shuffle(List<E> list),将list中的数据随机排列。static void rotate(List<E> list,int distance),旋转链表中的数据。public static void reverse(List<E> list),翻转list中的数据。
堆栈
- 声明堆栈:
Stack<E> stack=new Stack<E>(); - 压栈操作:
public E push(E item); - 弹栈操作:
public E pop(); - 获取堆栈顶的数据:
public int search(Object data);
散列映射
HashMap<K,V>泛型类创建的对象称作散列映射。如:HashMap<String,Student> hashtable=HashSet<String,Student>();。- 常用方法详见课本。
树集
TreeSet<E>类创建的对象称作树集,采用树结构存储数据。并使用add方法添加结点- 结点的大小关系,与添加顺序无关,是按照字典序排序的。
- 常用方法详见书本。
树映射
TreeMap<K,V>对象为树映射。树映射使用public V put(K key,V value)方法添加结点,不仅存储数据value,还存储和其关联的关键字 key。
自动装箱与拆箱
- 程序允许把一个基本数据类型添加到类似链表等数据结构中,系统会自动完成基本类型到相应对象的转换(自动装箱)。当从一个数据结构中获取对象时,如果该对象时基本数据的封装对象,那么系统自动完成对象到基本类型的转换(自动拆箱)。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 203/203 | 4/4 | 15/15 | |
| 第二周 | 326/529 | 2/6 | 12/27 | |
| 第三周 | 1000/1500 | 2/8 | 20/47 | |
| 第四周 | 800/2300 | 3/11 | 20/67 | |
| 第五周 | 500/2800 | 2/13 | 18/85 | |
| 第六周 | 900/3700 | 2/15 | 15/100 |
