
2017-2018-1 20155305 《信息安全系统设计基础》第九周学习总结
2017-2018-1 20155305 《信息安全系统设计基础》第九周学习总结
教材内容总结
1.了解常见的存储技术(RAM、ROM、磁盘、固态硬盘等)
- ram,掉电数据全部丢失,内存,显存都是ram;
- rom,掉电不易失,bios就是一种rom,这里注意,目前闪存也是掉电不易失,但本质属于nandflash,rom细分还有很多种,有些rom只能一次性写入,有些可以反复擦写;
- 内存,本质是ram,冯诺依曼结构上面的定义,cpu直接访问的是内存;
- 硬盘,hdd,ssd都是硬盘,属于外存,上面的东西需要先读入内存才可以被计算机访问;
2.理解局部性原理
-
局部性通常有两种不同的形式:时间局部性和空间局部性。在一个具有良好时间局部性的程序中,被引用一次的存储器位置很有可能在接下来时间内再被多次引用。在已给具有良好空间局部性的程序中,若一个存储器位置被引用了一次,那么在接下来时间内将引用附近的一个存储器位置。
int sum1(int array[]) { int i, sum = 0; int length = sizeof(v); for(i = 0; i < length; i++) sum += array[i]; return sum; } -
该函数中,变量sum在每次循环迭代时被引用一次,因此对sum来说,有好的时间局部性。对变量v来说,它是一个int类型数组,循环时按顺序访问v[i],因而有很好的空间局部性,但时间局部性不好,因为每个元素只被访问了一次。这就有点像一个程序的时间复杂度和空间复杂度一样,二者是不可兼得的,所以只要满足时间和空间局部性二者之一,就可以说符合程序的局部性原则。
3.理解缓存
- 缓存是什么?
用于加速数据交换,达到用时即取的作用。缓存也是优化的一种方式。 - 理解:
一般我们在进行访问请求网站流程:用户通过客户端(浏览器)发送请求到服务器端,服务器端连接到数据库读取数据,最后服务器把数据信息返送到客户端。
加入缓存的理解是:
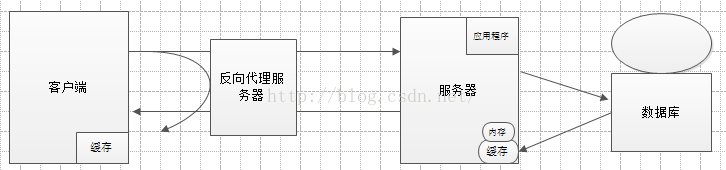
(1)服务器从数据库读取数据时,可以把数据存入内存中,下次用到同样数据,不需要再次连接数据库,直接从内存中读取。
(2)数据库(mysql)缓存:我们在做sql查询的时候,可以使用mysql自带的缓存机制,把更改不频繁的查询数据缓存起来,下次查询直接在缓存内读取,大大的节约了查询时间。
(3)客户端和服务器端之间用上反向代理服务器,客户端发送请求,代理服务器会代替客户端请求服务器,之后把访问到的时结果缓存到本服务器,下次客户端直接在反向代理服务器中把结果得到,极大的加快了访问速度。
(4)客户(浏览器)端的缓存:用户访问网站静态页面,可以把静态页面缓存到本地文件,下次访问直接从文件内读取,不需要走php解析的过程。
4.存储器层次结构
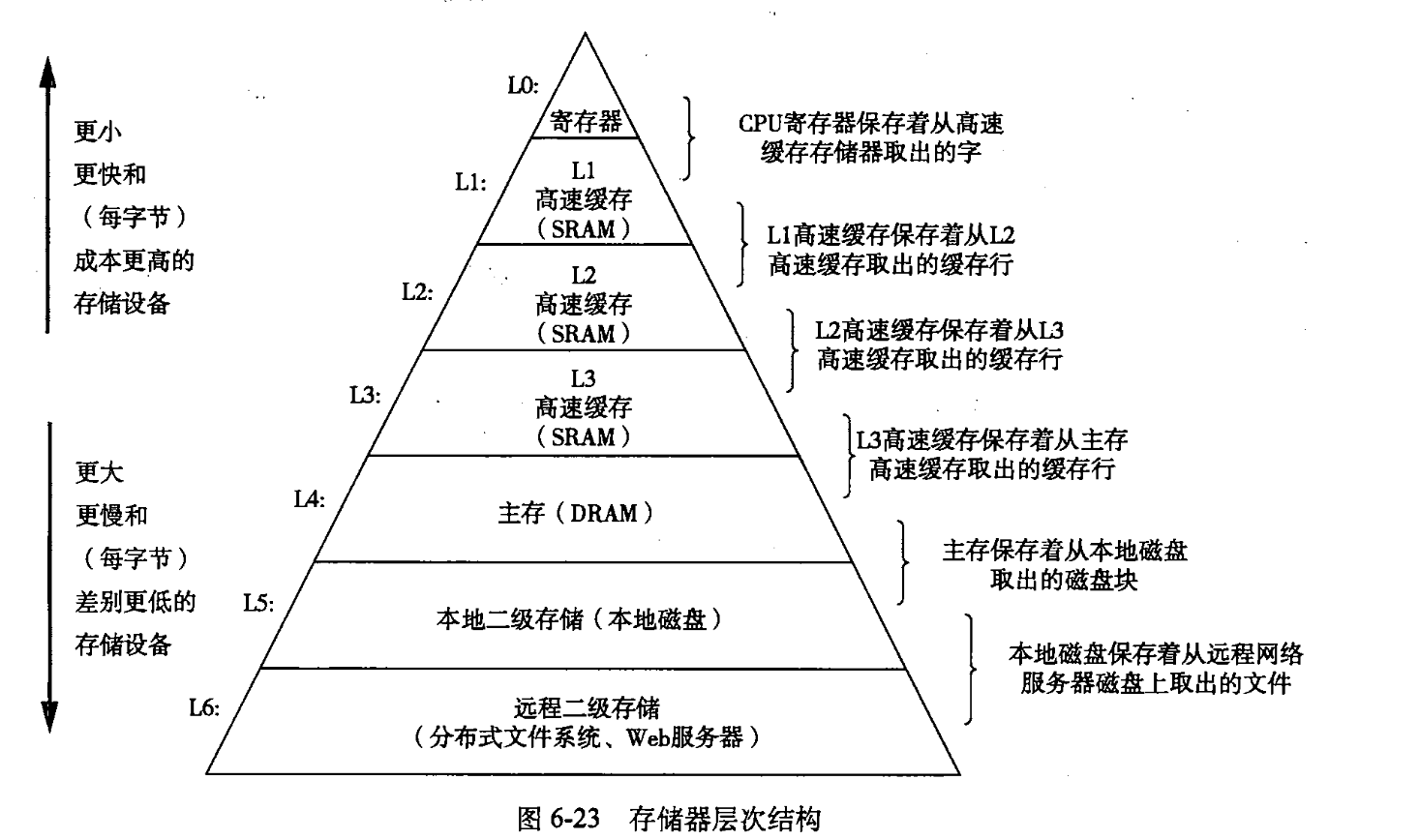
- 缓存
高速缓存:是一个小而快速的存储设备,它作为存储在更大、更慢的设备中的数据对象的缓冲区域。
缓存:使用高速缓存的过程称为缓存。
数据总是以块大小为传送单元在第k层与第k+1层之间来回拷贝。任一对相邻的层次之间块大小是固定的,但是其他的层次对之间可以有不同的块大小。
特点:层越低,块越大。
1)缓存命中
当程序需要第k+1层的某个数据对象d时,首先在当前存储在第k层的一个块中查找d,如果d刚好缓存在第k层中,就称为缓存命中。
该程序直接从第k层读取d,比从第k+1层中读取d更快。
2)缓存不命中
即第k层中没有缓存数据对象d。
这时第k层缓存会从第k+1层缓存中取出包含d的那个块。如果第k层缓存已满,就可能会覆盖现存的一个块
3)缓存不命中的种类
a.强制性不命中/冷不命中
即第k层的缓存是空的(称为冷缓存),对任何数据对象的访问都不会命中。
b.冲突不命中
由于一个放置策略:将第k+1层的某个块限制放置在第k层块的一个小的子集中,这就会导致缓存没有满,但是那个对应的块满了,就会不命中。
c.容量不命中
当工作集的大小超过缓存的大小时,缓存会经历容量不命中,就是说缓存太小了,不能处理这个工作集。
4)缓存管理
某种形式的逻辑必须管理缓存,而管理缓存的逻辑可以是硬件、软件,或者两者的集合。
- 存储器层次结构概念小结
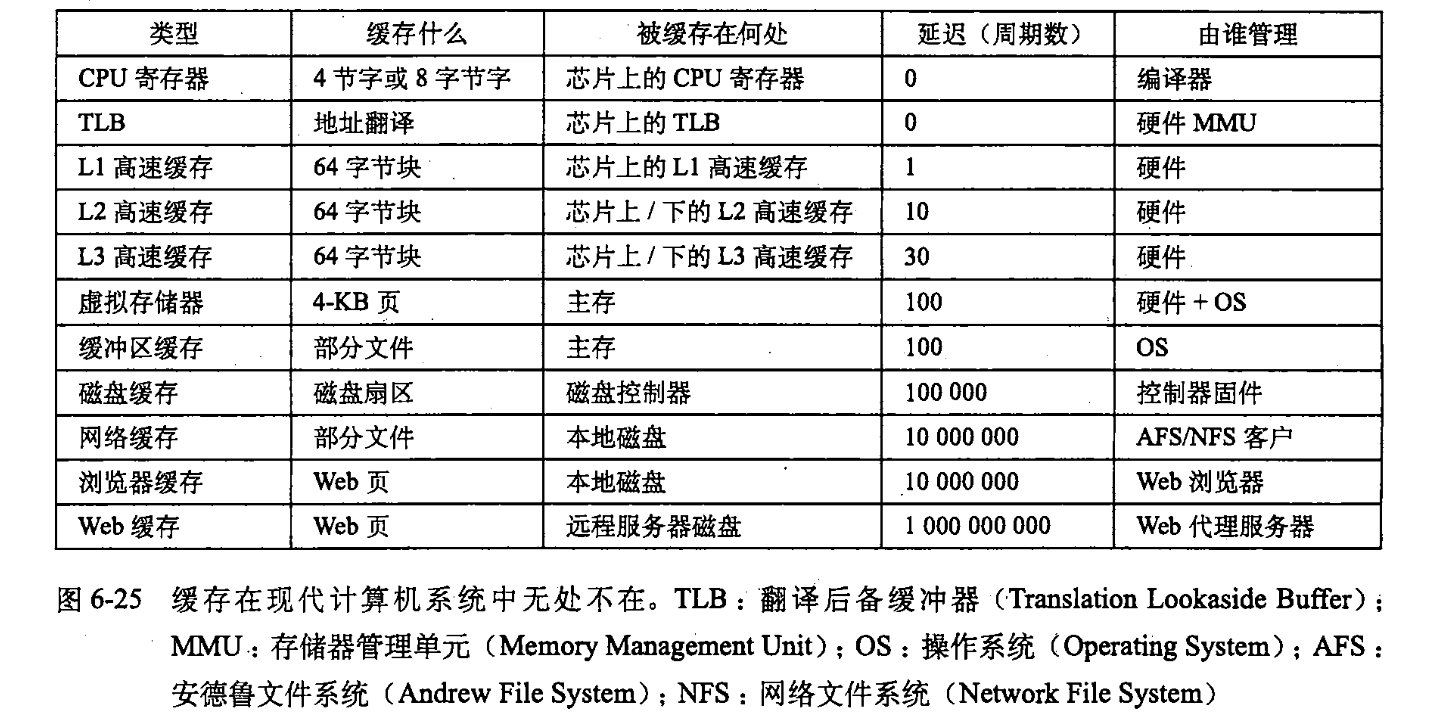
5.高速缓存存储器
①L1高速缓存:位于CPU寄存器文件和主存之间,访问速度2-4个时钟周期
②L2高速缓存:位于L1高速缓存和主存之间,访问速度10个时钟周期
③L3高速缓存:位于L2高速缓存和主存之间,访问速度30或40个时钟周期
-
通用的高速缓存存储器结构
高速缓存是一个高速缓存组的数组,它的结构可以用元组(S,E,B,m)来描述:S:这个数组中有S=2^s个高速缓存组 E:每个组包含E个高速缓存行 B:每个行是由一个B=2^b字节的数据块组成的 m:每个存储器地址有m位,形成M=2^m个不同的地址
除此之外还有标记位和有效位:
有效位:每个行有一个有效位,指明这个行是否包含有意义的信息
标记位:t=m-(b+s)个,唯一的标识存储在这个高速缓存行中的块
组索引位:s
块偏移位:b
高速缓存的结构将m个地址划分成了t个标记位,s个组索引位和b个块偏移位。
1)高速缓存的大小/容量C:指所有块的大小的和,不包括标记位和有效位,所以:
C=S*E*B
2)工作过程
S,B将m个地址位分为了三个字段:
先通过s个组索引位找到这个字必须存储在哪个组中
然后t个标记位告诉我们这个组中的哪一行包含这个字(当且仅当设置了有效位并且该行的标记位与地址中的标记位相匹配时)
b个块偏移位给出来在B个字节的数据块中的字偏移
-
直接映射高速缓存
根据E(每个组的高速缓存行数)划分高速缓存为不同的类,E=1的称为直接映射高速缓存。
高速缓存确定一个请求是否命中,然后取出被请求的字的过程,分为三步:1.组选择 2.行匹配 3.字抽取
1)组选择
高速缓存从w的地址中间抽取出s个组索引位
组索引位:一个对应于一个组号的无符号整数。
类比:高速缓存-关于组的一位数组,组索引位就是到这个数组的索引。
2)行匹配
判断缓存命中的两个充分必要条件:
该行设置了有效位
高速缓存行中的标记和w的地址中的标记相匹配
3)字选择
块-关于字节的数组,字节偏移是到这个数组的一个索引。
4)缓存不命中时的行替换
5)后运行中的直接映射高速缓存
标记位和索引位连起来唯一的标识了存储器中的每个块
映射到同一个高速缓存组的块由标记位唯一地标识
教材学习中的问题和解决过程
- 问题1:
代码调试中的问题和解决过程
- 问题1:
代码托管
上周考试错题总结
结对及互评
点评模板:
-
博客中值得学习的或问题:
- 学习态度认真
-
代码中值得学习的或问题:
- 编写代码严谨
-
其他
本周结对学习情况
- [20155311](博客链接)
- 结对照片
- 结对学习内容
-存储器技术,缓存,局部性
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 10/ 10 | 1/1 | 10/10 | |
| 第三周 | 158/ 168 | 1/2 | 17/27 | |
| 第五周 | 145/ 313 | 3/ 5 | 21/48 | |
| 第六周 | 209/ 522 | 1/ 6 | 20/68 | |
| 第七周 | 200/ 722 | 2/ 8 | 20/88 | |
| 第九周 | 55/ 777 | 2/ 10 | 19/107 |
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式
:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
-
计划学习时间:20小时
-
实际学习时间:19小时
-
改进情况:开始进入学习状态,但因为别的课程作业也很多,所以安排不够好,可能学习不够认真
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号