

2017-2018-1 20155222 《信息安全系统设计基础》第13周学习总结
深入理解计算机系统第三章--程序的机器级表示
知识点总结
-
x86
x86架构于1978年推出的Intel 8086中央处理器中首度出现,它是从Intel 8008处理器中发展而来的,而8008则是发展自Intel 4004的。8086在三年后为IBM PC所选用,之后x86便成为了个人计算机的标准平台,成为了历来最成功的CPU架构。其他公司也有制造x86架构的处理器,计有Cyrix(现为VIA所收购)、NEC集团、IBM、IDT以及Transmeta。Intel以外最成功的制造商为AMD,其早先产品Athlon系列处理器的市场份额仅次于Intel Pentium。
8086是16位处理器;直到1985年32位的80386的开发,这个架构都维持是16位。接着一系列的处理器表示了32位架构的细微改进,推出了数种的扩充,直到2003年AMD对于这个架构发展了64位的扩充,并命名为AMD64。后来Intel也推出了与之兼容的处理器,并命名为Intel 64。两者一般被统称为x86-64或x64,开创了x86的64位时代。
-
AT&T 格式Linux 汇编语法格式
在 AT&T 汇编格式中,寄存器名要加上 '%' 作为前缀;而在 Intel 汇编格式中,寄存器名不需要加前缀。例如:AT&T 格式 Intel 格式 pushl %eax push eax 在 AT&T 汇编格式中,用 '$' 前缀表示一个立即操作数;而在 Intel 汇编格式中,立即数的表示不用带任何前缀。例如: AT&T 格式 Intel 格式 pushl $1 push 1 AT&T 和 Intel 格式中的源操作数和目标操作数的位置正好相反。在 Intel 汇编格式中,目标操作数在源操作数的左边;而在 AT&T 汇编格式中,目标操作数在源操作数的右边。例如: AT&T 格式 Intel 格式 addl $1, %eax add eax, 1 在 AT&T 汇编格式中,操作数的字长由操作符的最后一个字母决定,后缀'b'、'w'、'l'分别表示操作数为字节(byte,8 比特)、字(word,16 比特)和长字(long,32比特);而在 Intel 汇编格式中,操作数的字长是用 "byte ptr" 和 "word ptr" 等前缀来表示的。例如: AT&T 格式 Intel 格式 movb val, %al mov al, byte ptr val 在 AT&T 汇编格式中,绝对转移和调用指令(jump/call)的操作数前要加上' * ' 作为前缀,而在 Intel 格式中则不需要。 远程转移指令和远程子调用指令的操作码,在 AT&T 汇编格式中为 "ljump" 和 "lcall",而在 Intel 汇编格式中则为 "jmp far" 和 "call far",即: AT&T 格式 Intel 格式 ljump $section, $offset jmp far section:offset lcall $section, $offset call far section:offset 与之相应的远程返回指令则为: AT&T 格式 Intel 格式 lret $stack_adjust ret far stack_adjust 在 AT&T 汇编格式中,内存操作数的寻址方式是 section:disp(base, index, scale) 而在 Intel 汇编格式中,内存操作数的寻址方式为: section:[base + index*scale + disp] 由于 Linux 工作在保护模式下,用的是 32 位线性地址,所以在计算地址时不用考虑段基址和偏移量,而是采用如下的地址计算方法: disp + base + index * scale 值得注意的是Intel早在1990年代就与HP合作提出了一种用在安腾系列处理器中的独立的64位架构,这种架构被称为IA-64。IA-64是一种崭新的系统,和x86架构完全没有相似性;不应该把它与x86-64或x64弄混。
-
IA32数据格式
类型 Intel数据类型 汇编代码后缀 Char 字节 b(1字节) Short 字 w(2字节) Int 双字 l(4字节) Long int 双字 l(4字节) Long long int - 4字节 Char* 双字 l(4字节) Float 单精度 s(4字节) Double 双精度 l(8字节) Long double 扩展精度 t(10或12字节) -
堆栈、栈帧与函数调用过程分析
函数调用是程序设计中的重要环节,也是程序员应聘时常被问及的,本文就函数调用的过程进行分析。- 堆和栈
首先要清楚的是程序对内存的使用分为以下几个区:
l 栈区(stack):由编译器自动分配和释放,存放函数的参数值,局部变量的值等。操作方式类似于数据结构中的栈。
l 堆区(heap):一般由程序员分配和释放,若程序员不释放,程序结束时可能由操作系统回收。与数据结构中的堆是两码事,分配方式类似于链表。
l 全局区(static):全局变量和静态变量存放在此。
l 文字常量区:常量字符串放在此,程序结束后由系统释放。
l 程序代码区:存放函数体的二进制代码。 - 堆和栈的申请方式:
栈由系统自动分配,速度较快,在windows下栈是向低地址扩展的数据结构,是一块连续的内存区域,大小是2MB。
堆需要程序员自己申请,并指明大小,速度比较慢。在C中用malloc,C++中用new。另外,堆是向高地址扩展的数据结构,是不连续的内存区域,堆的大小受限于计算机的虚拟内存。因此堆空间获取和使用比较灵活,可用空间较大。 - 栈帧结构和函数调用过程
栈在函数调用中的作用:参数传递、局部变量分配、保存调用的返回地址、保存寄存器以供恢复。
栈帧(stack Frame):一次函数调用包括将数据和控制从代码的一个部分传递到另外一个部分,栈帧与某个过程调用一一映射。每个函数的每次调用,都有它自己独立的一个栈帧,这个栈帧中维持着所需要的各种信息。寄存器ebp指向当前的栈帧的底部(高地址),寄存器esp指向当前的栈帧的顶部(低址地)。 - 函数调用规则:
l _cdecl:按从右至左的顺序压参数入栈,由调用者把参数弹出栈。由于每次函数调用都要由编译器产生清楚堆栈的代码,所以使用_cdecl的代码比使用_stdcall的代码要大很多,但是这种方式支持可变参数。对于C函数,名字修饰约定为在函数名前加下划线。对于C++,除非特变使用extern C,C++使用不同的名字修饰方式。
l _stdcall:按从右至左的顺序压参数入栈,由被调用者把参数弹出栈。调用约定在输出函数名前加上一个下划线前缀,后面加上一个“@”符号和其参数的字节数。
l _fastcall:主要特点就是快,因为它是通过寄存器来传送参数的,和__stdcall很象,唯一差别就是头两个参数通过寄存器传送。注意通过寄存器传送的两个参数是从左向右的,即第一个参数进ECX,第2个进EDX,其他参数是从右向左的入stack。返回仍然通过EAX。
- 堆和栈
-
缓冲区溢出攻击
-
简介
缓冲区溢出是指当计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量,溢出的数据覆盖在合法数据上。理想的情况是:程序会检查数据长度,而且并不允许输入超过缓冲区长度的字符。但是绝大多数程序都会假设数据长度总是与所分配的储存空间相匹配,这就为缓冲区溢出埋下隐患。操作系统所使用的缓冲区,又被称为"堆栈",在各个操作进程之间,指令会被临时储存在"堆栈"当中,"堆栈"也会出现缓冲区溢出。 -
危害
可以利用它执行非授权指令,甚至可以取得系统特权,进而进行各种非法操作。缓冲区溢出攻击有多种英文名称:buffer overflow,buffer overrun,smash the stack,trash the stack,scribble the stack, mangle the stack, memory leak,overrun screw;它们指的都是同一种攻击手段。第一个缓冲区溢出攻击--Morris蠕虫,发生在二十年前,它曾造成了全世界6000多台网络服务器瘫痪。在当前网络与分布式系统安全中,被广泛利用的50%以上都是缓冲区溢出,其中最著名的例子是1988年利用fingerd漏洞的蠕虫。而缓冲区溢出中,最为危险的是堆栈溢出,因为入侵者可以利用堆栈溢出,在函数返回时改变返回程序的地址,让其跳转到任意地址,带来的危害一种是程序崩溃导致拒绝服务,另外一种就是跳转并且执行一段恶意代码,比如得到shell,然后为所欲为。
-
原理
通过往程序的缓冲区写超出其长度的内容,造成缓冲区的溢出,从而破坏程序的堆栈,使程序转而执行其它指令,以达到攻击的目的。造成缓冲区溢出的原因是程序中没有仔细检查用户输入的参数。例如下面程序:
void function(char *str) { char buffer[16]; strcpy(buffer,str); }上面的strcpy()将直接把str中的内容copy到buffer中。这样只要str的长度大于16,就会造成buffer的溢出,使程序运行出错。存在像strcpy这样的问题的标准函数还有strcat()、sprintf()、vsprintf()、gets()、scanf()等。
当然,随便往缓冲区中填东西造成它溢出一般只会出现分段错误(Segmentation fault),而不能达到攻击的目的。最常见的手段是通过制造缓冲区溢出使程序运行一个用户shell,再通过shell执行其它命令。如果该程序属于root且有suid权限的话,攻击者就获得了一个有root权限的shell,可以对系统进行任意操作了。
缓冲区溢出攻击之所以成为一种常见安全攻击手段其原因在于缓冲区溢出漏洞太普遍了,并且易于实现。而且,缓冲区溢出成为远程攻击的主要手段其原因在于缓冲区溢出漏洞给予了攻击者他所想要的一切:植入并且执行攻击代码。被植入的攻击代码以一定的权限运行有缓冲区溢出漏洞的程序,从而得到被攻击主机的控制权。
在1998年Lincoln实验室用来评估入侵检测的的5种远程攻击中,有2种是缓冲区溢出。而在1998年CERT的13份建议中,有9份是是与缓冲区溢出有关的,在1999年,至少有半数的建议是和缓冲区溢出有关的。在ugtraq的调查中,有2/3的被调查者认为缓冲区溢出漏洞是一个很严重的安全问题。
缓冲区溢出漏洞和攻击有很多种形式,会在第二节对他们进行描述和分类。相应地防卫手段也随者攻击方法的不同而不同,将在第四节描述,它的内容包括针对每种攻击类型的有效的防卫手段。
-
折叠
练习题解析
-
3.1
假设下面的值存放在指明的内存地址和寄存器中:
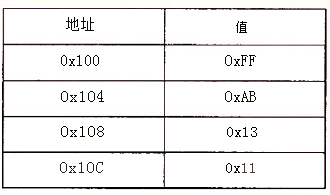
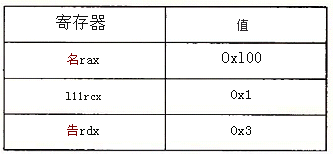
操作数 值 注释 %eax 0x100 寄存器 0x104 0xAB 绝对地址 $0x108 0x108 立即数 (%eax) 0xFF 地址0x100 4(%eax) 0xAB 地址0x104,4+(%eax) 9(%eax,%edx) 0x11 地址0x10c,9+%eax+%edx 260(%ecx,%edx) 0x13 地址0x108,260d=0x104 0xFC(,%ecx,4) 0xFF 地址0x100,0xFC+4*%ecx (%eax,%edx,4) 0x11 地址0x10c,%eax+4*%edx -
3.2
对于下面汇编代码的每一行,根据操作数,确定适当的指令后_缀。(例如, mov可以被重写成 movb、 movw、 mov'或者 movq。)movl %eax,(%esp) movw (%eax),%dx movb $0xFF,%bl movb (%esp,%edx,4),%dh pushl $0xFF movw %dx,(%eax) popl %edi -
3.3
当我们调用汇编器的时候,下面代码的每一行都会产生一个错误信息。解释每一行都是哪里出了错。错例 解析 movb $0xF,(%bl) %bl不能作为地址单位,因为它只有一字节,而IA-32的地址是32位的。 movl %ax,(%esp) %ax只有一个字长,而movl是用来传送双字的,这里应该用movw。 movw (%eax),4(%esp) %eax和%esp为双字长,而movw用来传送单字,这里应该用movl movb %ah,%sh 没有%sh这个寄存器 movl %eax,$0x123 立即数不能作为目的操作数 movl %eax,%dx %eax为双字长,而%dx为单字长,不能互相传送 movb %si,8(%ebp) %si为单字长,而movb用来传送单字节,这里应该用movw -
3.4
假设变量 sp和 dp被声明为类型
src_t sp;
dest_tdp;
这里 src t和 dest t是用 typedef声明的数据类型。我们想使用适当的数据传送指令来实现下面的操作
*dp= (dest_t) *sp;
假设 sp和 dp的值分别存惜在寄存器宅rdi和毛rsi中。对于表中的每个表项, 给出实现指定数据传送的两条指令。 其中第一条指令应该从内存中读数, 做适当的转换, 并设置寄存器%rax的适当部分。然后,第二条指令要把宅rax的适当部分写到内存。在这商种情况中, 寄存器的部分可以是%rax、%eax、%ax或%al, 两者可以互不相同 。
记住, 当执行强制类型转换既涉及大小变化又涉及 C语言中符号变化时, 操作应该先改变大小(2. 2. 6节)。src_t dest_t 指令 int int movl %eax,(%edx) char int movsbl %al,(%edx) char unsigned movsbl %al,(%edx) unsigned char int movzbl %al,(%edx) int char movb %eal,(%edx) unsigned unsigned char movb %eal,(%edx) unsigned int movl %eax,(%edx) -
3.5

void decode1(int *xp,int *yp,int *zp) { int x = *xp; int y = *yp; int z = *zp; *yp = x; *zp = y; *xp = z; } -
3.6
假设寄存器%eax的值为,%ecx的值为y。填写下表,指明下面每条汇编代码指令存储在寄存器%edx中的值:指令 结果 leal 6(%eax),%edx x+6 leal (%eax,%ecx),%edx x+y leal (%eax,%ecx,4),%edx x+4y leal 7(%eax,%eax,8),%edx 9x+7 leal 0xA(,%ecx,4),%edx 10+4y leal 9(%eax,%ecx,2),%edx x+2y+9 -
3.7
假设下面的值存放在指定的存储器地址和寄存器中
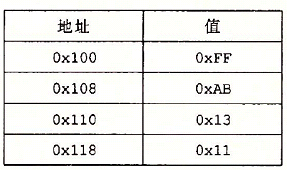
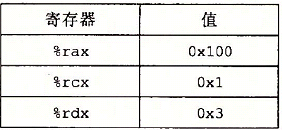
填写下表,给出下面指令的效果,说明将被更新的寄存器或存储器位置,以及位置的值指令 目的 值 解析 addl %ecx,(%eax) 0x100 0x100 这条指令的目的操作数(%eax)是寄存器%eax的值0x100(视为一个指针)所指向的值,所以地址0x100中的值被更新了,新的值为0xFF加上寄存器%ecx的值(视为一个数)0x1,等于0x100。 subl %edx,4(%eax) 0x104 0xA8 这条指令的目的操作数4(%eax)是寄存器%eax的值加上4即0x104(视为一个指针)所指向的值,所以地址0x104中的值被更新了,新的值为0xAB减去寄存器%edx的值(视为一个数)0x3,等于0xA8。 imull $16,(%eax,%edx,4) 0x10c 0x110 这条指令的目的操作数4(%eax)是寄存器%eax的值加上4即0x104(视为一个指针)所指向的值,所以地址0x104中的值被更新了,新的值为0xAB减去寄存器%edx的值(视为一个数)0x3,等于0xA8。 incl 8(%eax) 0x108 0x14 这条指令的目的操作数8(%eax)是寄存器%eax的值0x100加上8即0x108(视为一个指针)所指向的值,所以地址0x108中的值被更新了,新的值为0x13自增一等于0x14。 decl %ecx %ecx 0x0 这条指令的目的操作数%ecx是寄存器%ecx的值0x1,所以寄存器%ecx被更新了,新的值为0x1自减一等于0x0 subl %edx,%eax %eax 0xFD 这条指令的目的操作数%eax是寄存器%eax的值0x100,所以寄存器%eax被更新了,新的值为0x100减去寄存器%edx的值0x3等于0xFD。 -
3.8

movl 8(%ebp),%eax ;取出x的值 sall $2,%eax ;x左移两位 movl 12(%ebp),%ecx;将n的值放进%ecx中 sarl %cl,%eax ;将x向右移动cl中的值个单位,因为只允许移动0~31位,所以只能移动cl中的值个单位(最多为15)而不能移动%ecx中的值个单位(最多为2^32-1),否则可能出错。 -
3.9


int arith(int x,int y,int z) { int t1 = x^y; int t2 = t1 >> 3; int t3 = ~t2; int t4 = t3-z; return t4; } -
3.10

A.这个指令用来将寄存器%ordx设置为0,运用了对任意二,x^x=0这一属性。它对应于C语句x=0
B.将寄存器%rdx设置为。的更直接的方法是用指令movq $0,%rdx
C.不过,汇编和反汇编这段代码,我们发现使用xorq的版本只需要3个字节,而使用movq的版本需要7个字节。其他将%rdx设置为0的方法都依赖于这样一个属性,即任何更新低位4字节的指令都会把高位字节设置为。。因此,我们可以使用xorl o edx,o edx(2字节)或movl $0,$ edx(5字节)。 -
3.11
考虑如下函数,它计算两个无符号64位数的商和余数:void uremdiv(unsigned long x, unsigned long y, unsigned long *qp, unsigned long *rp){ unsigned long q=x/y; unsigned long r,xax/y; *}iP=q; *rP=r; }修改有符号除法的汇编代码来实现这个函数。
我们可以简单地把cqto指令替换为将寄存器%%rdx设置为。的指令,并且用divq而不是idivq作为我们的除法指令,得到下面的代码:void uremdiv(unsigned long x, unsigned long y unsigned long *qp, unsigned long *rp) x in %rdi,y in %rsi,rp in %rcx uremdiv: movq %rdx,%r8 movq %rdi, %rax movl $0,%edx divq %rsi movq %rax, (%r8) movq %rdx, (%rcx) ret } -
3.12
考虑下列的C语言代码:int comp(data_t a,data_t b){ return a COMP b }它给出了参数a和b之间比较的一般形式,这里,参数的数据类型data t(通过typedef)被声明为表3-1中列出的某种整数类型,可以是有符号的也可以是无符号的comp通过#define来定义。
假设a在%rdi中某个部分,b在%rsi中某个部分。对于下面每个指令序列,确定哪种数据类型data t和比较COMP会导致编译器产生这样的代码。(可能有多个正确答案,请列出所有的正确答案。)
A, cmpl %esi,%edi
setl %al
B, cmpw %si,%di
setge %al
C, cmpb %sil,%dil
setbe dal
D, cmpq %rsi,%rdi
setne %a
汇编代码不会记录程序值的类型,理解这点这很重要。相反地,不同的指令确定操作数的大小以及是有符号的还是无符号的。当从指令序列映射回C代时,我们必须做一点儿侦查工作,推断程序值的数据类型。
A.后缀'1'和寄存器指示符表明是32位操作数,而比较是对补码的<。我们可以推断data_t一定是int。
B.后缀'w'和寄存器指示符表明是16位操作数,而比较是对补码的>=。我们可以推断data_t一定是short。
C.后缀'b'和寄存器指示符表明是8位操作数,而比较是对无符号数的<=。我们可以推断data_t一定是unsigned char。
D.后缀'g',和寄存器指示符表明是64位操作数,而比较是!=,有符号、无符号和指针参数都是 一样的。我们可以推断data t可以是long, unsigned long或者某种形式的指针。 -
3.13
练习题3. 14考虑下面的C语言代码:int test(data_t a){ return a TEST 0; }它给出了参数a和0之间比较的一般形式,这里,我们可以用typedef来声明data_t,从而设置参数的数据类型,用#define来声明TEST,从而设置比较的类型。对于下面每个指令序列,确定哪种数据类型data t和比较TEST会导致编译器产生这样的代码。(可能有多个正确答案,请列出所有的正确答案。)
A, testq %rdi,%rdi
setge %al
B, testes %di,%di
sete dal
C, testb %dil,%dil
seta dal
D, testl %edi,%edi
setne %al
这道题使用了TEST指令而不是CMP指令。
A.后缀'g',和寄存器指示符表明是64位操作数,而比较是>=,一定是有符号数。我们可以推断data_ t一定是long
B.后缀'w'和寄存器指示符表明是16位操作数,而比较是二二,这个对有符号和无符号都是一样的。我们可以推断data_ t一定是short或者unsigned short
C.后缀'b'和寄存器指示符表明是8位操作数,而比较是针对无符号数的>。我们可以推断data t一定是unsigned char
D.后缀‘1’和寄存器指示符表明是32位操作数,而比较是<=。我们可以推断data_t一定是int -
3.14
在下面这些反汇编二进制代码节选中,有些信息被X代替了。回答下列关于这些指令的问题。
A.下面je指令的目标是什么?(在此,你不需要知道任何有关callq指令的信息。)
4003fa: 74 02 je:XXXXXX
4003f c:ff d0 callq *%rax
B.下面je指令的目标是什么?
40042f:74 f4 je:XXXXXX
400431:5d P0P %rbp
C. j a和pop指令的地址是多少?
XXXXXX:77 02 ja 400547
XXXXXX:5d pop %rbp
D.在下面的代码中,跳转目标的编码是PC相对的,且是一个4字节补码数。字节按
照从最低位到最高位的顺序列出,反映出x86-64的小端法字节顺序。跳转目标的
地址是什么?
4005e8:e9 73 ff ff ff jmpq XXXXXXX
4005ed: 90 nop
跳转指令提供了一种实现条件执行(if)和几种不同循环结构的方式。
A. j e指令的目标为Ox4003fc+ 0x02。如原始的反汇编代码所示,这就是0x4003fee
4003fa: 74 02 Je 4003fe
4003fc:ff d0 callq *%rax
B. j b指令的目标是。x400431-12由于。xf4是一12的一个字节的补码表示)。正如原始的反汇编代码所示,这就是0x900925:
40042f:74 f4 je 400425
400431:5d P0P %rbp
C.根据反汇编器产生的注释,跳转目标是绝对地址。x400547。根据字节编码,一定在距离pop指令0x2的地址处。减去这个值就得到地址0x400545。注意,7a指令的编码需要2个字节,它一定位于地址。x400543处。检查原始的反汇编代码也证实了这一点:
400543: 77 02 ja 400547
400545: 5d pop }rbp
D.以相反的顺序来读这些字节,我们看到目标偏移量是。xffffff73,或者十进制数一1410
0x4005ed(nop指令的地址)加上这个值得到地址0x900560:
4005e8: e9 73 ff ff ff jmpq 400547
4005ed: 90 nop -
3.15
已知下列C代码:void cond(long a, long *p) { if (p&&a>*p) *P=a; }GCC会产生下面的汇编代码:
void cond(long a, long *p) a in %rdi,p in %rsi cond: testq %rsi,%rsi je .L1 cmpq %rdi,(%rsi) jge .L1 movq %rdi,(%rsi) .L1: rep; retA.按照图3-16 b中所示的风格,用C语言写一个goto版本,执行同样的计算,并模
拟汇编代码的控制流。像示例中那样给汇编代码加上注解可能会有所帮助。
B.请说明为什么C语言代码中只有一个if语句,而汇编代码包含两个条件分支。A.这里是C代码:
void goto_cond(long a, long *p){ if (p==0) goto done; if (*p>=a) goto done; *P=a; done: return; }B.第一个条件分支是“表达式实现的一部分。如果对P为非空的测试失败,代码会跳过对a>*p的测试。
-
3.16
将if语句翻译成got。代码的另一种可行的规则如下:t=test-expr ; if (t) goto true; else-statement goto done; true: then-statement done:A.基于这种规则,重写absdiff se的goto版本。
B.你能想出选用一种规则而不选用另一种规则的理由吗?A.转换成这种替代的形式,只需要调换一下几行代码:
long gotodiff_se_alt(long x, long y){ long result; if (x<Y) goto x_lt_y; ge_cnt++; result=x一Y: return result; x_lt_y: lt_cnt++; result=Y一x; return result; }B.在大多数情况下,可以在这两种方式中任意选择。但是原来的方法对常见的没有e工se语句的情况更好一些。对于这种情况,我们只用简单地将翻译规则修改如下:
t=test-expr; if(!t) goto done; then-statement done:基于这种替代规则的翻译更麻烦一些。
-
3.17
练习题3. 18从如下形式的C语言代码开始:long test (long x,long y, long z){ long val=(___) if(___){ if(__) val=(___) else val=(___) }else if(___) val=(___) return val; }GCC产生如下的汇编代码:
long test (long x, long y, long z) x in%rdi,y in %rsi,z in%rdx test: leaq (%rdi,%rsi),%rax addq %rdx,%rax cmpq $-3,%rdl jge .L2 cmpq %rdx, %rsi jge .L3 movq %rdi,%rax imulq %rsi,%rax ret .L3: movq %rsi,%}rax imulq %rdx,%rax 工et .L2: cmpq $2,%rdi jle .L4 movq %rdi,%rax imulq %rdx, %rax .L4: rep; ret填写C代码中缺失的表达式。
long test (long x, long y, long z){ long val=x+Y+z; if (x<-3){ if (y<z) val=x*y; else val= y*z }else if(x>2) val = x*z return val -
3.18
在一个比较旧的处理器模型上运行,当分支行为模式非常可预测时,我们的代码需要大约16个时钟周期,而当模式是随机的时候,需要大约31个时钟周期。
A.预测错误处罚大约是多少?
B.当分支预测错误时,这个函数需要多少个时钟周期?A.可以直接应用公式得到T,}P=2X (31-16>=30a
B.当预测错误时,函数会需要大概16-X30=46个周期。 -
3.19
define OP______/Unknown operator/
在下面的C函数中,我们对OP操作的定义是不完整的
long arith(lo return x }当编译时,GCC会产生如下汇编代码:
long arith(long x) x in }rdi arith: leaq 7(}rdi),0/rax testq }rdi,%rdi cmovns }rdi,%rax sarq $3,}rax retA.OP进行的是什么操作?
B.给代码添加注释,解释它是如何工作的。A.运算符是‘/’。可以看到这是一个通过右移实现除以2的3次幂的例子(见2. 3. 7节)。在移位k=3之前,如果被除数是负数的话,必须加上偏移量2^k-1=7
-
3.20
练习题3. 21 C代码开始的形式如下:long test (long x, long y){ long val=(________); if(________){ if(_________) val=(_________); else val=(_________); }else if(_____) val=_(_________); return val; }GCC会产生如下汇编代码:
long test (long x, long y) x in %rdi,y in %rsi test: leaq 0(,%rdi,8),%rax testq %rsi,%rsi jle .L2 movq %rsi,%rax subq%,%rax movq %rdi,%rdx andq %rsi,%rdx cmpq %rsi,%rdi cmovge %rdx, %rax ret :L2: addq %rsi,%rdi cmpq $-2, %rsi cmovle %rdi,%rax ret填补C代码中缺失的表达式。
long test (long x, long y){ long val,8*x; if (y>0){ if (x<Y) val=y-x; else val=x&y; }else if (y<=-2) val = x+y; return val; } -
3.21
A.用一个32位int表示n!,最大的n的值是多少?
B.如果用一个64位long表示,最大的n的值是多少?A.6 227 020 800
B.用数据类型long来计算,直到zo!才溢出,得到2 432 902 008 176 640 000 -
3.22
已知C代码如下:long dw_loop(long x){ long y=x*x; long *p=&x; long n=2*x; do{ x+=y} (*p)++; n--; }while (n>0); return x; }GCC产生的汇编代码如下:
long dw_locp(long x) x initially %rdi dw_loop: movq }rdi,}rax movq %rdi,}rcx imulq %rdi,}rcx leaq (}rdi,}rdi),%rdx .L2: leaq 1(}rcx,}rax),0/rax subq $1,yrdx testq }rdx,%rdx Jg·L2 rep;retA.哪些寄存器用来存放程序值x. y和n?
B.编译器如何消除对指针变量P和表达式(*P)++
C.对汇编代码添加一些注释,描述程序的操作,隐含的指针间接引用的需求?类似于图3-19c中所示的那样。编泽循环产生的代码可能会很难分析,因为编译器对循环代码可以执行许多不同的优化,也因为可能很难把程序变量和寄存器匹配起来。这个特殊的例子展示了几个汇编代码不仅仅是C代码直接翻译的地方。
A.虽然参数x通过寄存器%rdi传递给函数,可以看到一旦进人循环就再也没有引用过该寄存器了。相反,我们看到第2~5行上寄存器%rax,%rcx和%rdx分别被初始化为x, xx和x+x。因此可以推断,这些寄存器包含着程序变量。
B.编译器认为指针p总是指向x,因此表达式(p)++就能够实现x加一。代码通过第7行的Leaq指令,把这个加一和加y组合起来。 -
3.23
对于如下C代码:long loop while (long a, long b) { long result= while(_______){ result=(_______) a=(_______) } return result }以命令行选项一。9运行GCC产生如下代码:
long Ioop_while(long a, long) a in %rdi,b in %rsi loop_while: movl $1,义eax jmp .L2 L3: leaq (%rdi,%rsi),%rdx imulq %rdx,%义rax addq $i,%rdi L2: cmpq %rsi,%rdi j1 .L3 rep; ret可以看到编译器使用了跳转到中间的翻译方法,在第3行用jmp跳转到以标号.L2开始的测试。填写C代码中缺失的部分。
long loop_while(long a, long b) { long result=1; while (a<b){ result=result*(a+b) a=a+1; } return result; }
家庭作业解析
- 3.54
一个函数的原型为
GCC产生如下汇编代码:long decode2(long x, long y, long z);
参数x, y和z通过寄存器%rdi,%rsi和%rdx传递。代码将返回值存放在寄存器%rax中。写出等价于上述汇编代码的decode2的C代码。1 decode2: 2 subq %rdx, %rsi 3 imulq %rsi, %rdi a movq %rsi,%rax s salq $63, %rax 6 sarq $63,%rax 7 xorq %rdi, %rax 8 ret
int t1 = z;
int t2 = t1 - z;
int t3 = t2;
int t4 = t3 << 15;
int t5 = t4 >> 15;
int t6 = t2 ^ x;
int t7 = t5 * t6;
return t7;
-
3.55
下面的代码计算两个64位有符号值二和Y的128位乘积,并将结果存储在内存中:1 typedef _int128 int128_t; 2 3 void store_prod(int128_t *dest,int64_t x, int64_t y){ 4 *dest=x*(int128_t) y; 5 }GCC产出下面的汇编代码来实现计算:
1 movl 12(%ebp),%esi //取x的低32位 2 movl 20(%ebp),%eax //取y 3 movl %eax,%edx //将y复制到%edx中 4 sarl $31,%edx //取y的最高位即符号位 5 movl %edx,%ecx //将y的符号位复制到%ecx中 6 imull %esi,%ecx 7 movl 16(%ebp),%ebx;取x的高32位 8 imull %eax,%ebx //x的高32位乘以y 9 addl %ebx,%ecx //计算 x的高32位* y + x的低32位 * y的符号位 存到%ecx 10 mull %esi //计算y * x的低32位 的无符号64位乘积 11 leal (%ecx,%edx),%edx;将64位乘积的高位与x的高32位 * y + x的低32位 * y的符号位得到最终结果的高位 12 movl 8(%ebp),%ecx 13 movl %eax,(%ecx) 14 movl %edx,4(%ecx) //将结果写入目的内存地址
| 语句 | %eax | %ebx | %ecx | %edx | %esi |
|---|---|---|---|---|---|
| 1 | x的低32位 | ||||
| 2 | y | x的低32位 | |||
| 3 | y | y | x的低32位 | ||
| 4 | y | y的符号位 | x的低32位 | ||
| 5 | y | y的符号位 | y的符号位 | x的低32位 | |
| 6 | y | y的符号位 * x的低32位 | y的符号位 | x的低32位 | |
| 7 | y | x的高32位 | y的符号位 * x的低32位 | y的符号位 | x的低32位 |
| 8 | y | x的高32位 * y | y的符号位 * x的低32位 | y的符号位 | x的低32位 |
| 9 | y | x的高32位 * y | y的符号位 * x的低32位+x的高32位 * y | y的符号位 | x的低32位 |
| 10 | x的低32位 * y | x的高32位 * y | y的符号位 * x的低32位+x的高32位 * y | y的符号位 | x的低32位 |
| 11 | x的低32位 * y | x的高32位 * y | y的符号位 * x的低32位+x的高32位 * y | y的符号位 + y的符号位 * x的低32位+x的高32位 * y | x的低32位 |
| 12 | x的低32位 * y | x的高32位 * y | * dest | y的符号位 + y的符号位 * x的低32位+x的高32位 * y | x的低32位 |
| 13 | |||||
| 14 |
-
3.56考虑下面的汇编代码
long loop (long x, int n) x in %rdi,n in %esi loop: movl %esi,%ecx movl $1,%edx movl $0,%eax jmp .L2 .L3: movq %rdi, %r8 andq %rdx, %r8 orq %r8, %rax salq %cl, %rdx .L2: testq %rdx, %rdx jne .L3 rep; ret以上代码是编译以下整体形式的C代码产生的:
long loop (long x, int n) { long result = (_______); long mask; for (mask=______;mask_______;mask_______){ result |= ________; } return result; }你的任务是填写这个C代码中缺失的部分,得到一个程序等价于产生的汇编代码。回想一下,这个函数的结果是在寄存器%rax中返回的。你会发现以下工作很有帮助:检查循环之前、之中和之后的汇编代码,形成一个寄存器和程序变量之间一致的映射。
A.哪个寄存器保存着程序值x, n, result和mask?
B. result和mask的初始值是什么?
C. mask的测试条件是什么?
D. mask是如何被修改的?
E. result是如何被修改的
F.填写这段C代码中所有缺失的部分。解析:
A. x:%esi,n:%ebx,result:%edi,mask:%edx
B. result=0x55555555; //0101 0101 0101 0101 0101 0101 0101 0101 mask=0x80000000;
C. mask!=0
D. mask每次循环右移n位
E. result每次循环和x&mask的值进行异或
F.int loop(int x,int n) { int result=0x55555555; int mask; for(mask=0x80000000;mask!=0;((unsigned)mask)>>n)//汇编中mask是逻辑右移,而mask是有符号整型应该先转成无符号整型才能保证C语言的右移操作符编译成汇编的逻辑右移 { result^=x&mask; } return result; } -
3.57在3. 6. 6节,我们查看了下面的代码,作为使用条件数据传送的一种选择:
long cread(long *xp){ return (xp?*xp:0); }我们给出了使用条件传送指令的一个尝试实现,但是认为它是不合法的,因为它试图从一个空地址读数据。写一个C函数cread alt,它与cread有一样的行为,除了它可以被编译成使用条件数据传送。当编译时,产生的代码应该使用条件传送指令而不是某种跳转指令。
解析:
int cread_alt(int *xp) { int t=0; int *p=xp?xp:&t; return *p; }
