

20199107 2019-2020-2 《网络攻防实践》综合实践(大作业)
1 基础知识
1.1 论文简介
本次综合实践我选择的论文题为:What Are You Searching For? A Remote Key logging Attack on Search Engine Autocomplete,选自Usenix Security 2019。现在许多搜索引擎都具有自动完成功能,可在用户键入时向用户显示建议查询的列表。当查询发生更改时,自动完成功能会从客户端引发网络流量。该论文提出了一种通过搜索引擎自动完成功能对键盘记录进行攻击的一种侧信道攻击方法,称为击键识别和熵消除程序(Keystroke Recognition and Entropy Elimination Program,KREEP)。并针对百度和谷歌两个搜索引擎进行了攻击。
1.2 自动完成
许多网站都具有自动完成功能。当用户在搜索表单中输入文本时,就会向用户显示建议的搜索查询列表。建议查询的列表由算法根据用户的搜索历史记录,当前趋势和地理位置确定。为了使用户能够更快地找到信息,自动完成功能要求用户的客户端在检测到键盘输入事件时与服务器进行通信。因此,用户的击键会显示在网络流量中。例如,当在百度输入use后再输一个n时,搜索栏会给出usenix,usenix security等推荐。
主要有两种方法可以实现自动完成功能。首先是一种轮询模型,在该模型中,网页以固定的时间间隔定期检查查询输入的内容。当检测到更改时,会将自动完成请求发送到服务器以检索查询建议。根据轮询率和打字员的速度,自动完成请求可能不会立即跟在每次击键之后。如果在轮询计时器到期之前发生了两次击键,则它们都将包含在下一个自动完成请求中。在这种情况下,当键入速度超过轮询速度时,由于多个键合并到单个请求中,因此键盘输入事件时间可能不会如实保存在数据包到达时间中。
实现自动完成功能的第二种方法是回调模型,在该模型中,请求由键盘输入事件触发。在这种方法中,每个自动完成请求都会紧随在每个输入事件之后,因此数据包到达时间能忠实地保留击键事件之间的时间间隔。不可打印的字符(例如Shift,Ctrl和Alt)将被忽略,因为这些字符本身不会导致查询发生可见的变化。百度和谷歌都是使用这一种模型的,该论文仅关注第二种模型。
1.3 确定有限自动机
确定有限自动机(deterministic finite automaton, DFA)确定有限状态自动机A是由:
(1)一个非空有限的状态集合Q;
(2)一个输入字母表Σ(非空有限的字符集合),
(3)一个转移函数δ:Q×Σ→Q
(4)一个开始状态s∈Q
(5)一个接受状态的集合F⊆Q
所组成的5-元组。对于一个给定的属于该自动机的状态和一个属于该自动机字母表Σ的字符,它都能根据事先给定的转移函数转移到下一个状态(这个状态可以是先前那个状态)。
确定有限状态自动机从起始状态开始,一个字符接一个字符地读入一个字符串(该字符串每个字符都在字母表中),并根据给定的转移函数一步一步地转移至下一个状态。在读完该字符串后,如果该自动机停在一个属于F的接受状态,那么它就接受该字符串,反之则拒绝该字符串。
1.4 击键记录攻击
击键记录侧信道攻击旨在通过意外的信息泄漏来恢复受害者的键盘按键记录。这种攻击有范围广泛的模式,例如声学,震动,手部运动和CPU负载峰值等。对于密码输入,击键记录攻击可能会假设每个按键具有相等的出现概率,即最大熵,而对于自然语言,通常会假设用户键入了字典中包含的单词。
1.5 HTTP2头压缩中的静态霍夫曼编码
HTTP 请求和响应都是由「状态行、请求 / 响应头部、消息主体」三部分组成。一般而言,消息主体都会经过 gzip 压缩,或者本身传输的就是压缩过后的二进制文件(例如图片、音频),但状态行和头部却没有经过任何压缩,直接以纯文本传输。随着 Web 功能越来越复杂,每个页面产生的请求数也越来越多,根据 HTTP Archive 的统计,当前平均每个页面都会产生上百个请求。越来越多的请求导致消耗在头部的流量越来越多,尤其是每次都要传输 UserAgent、Cookie 这类不会频繁变动的内容,完全是一种浪费。因此催生了HTTP2标头压缩技术。HTTP2标头压缩需要:
(1)维护一份相同的静态字典(Static Table),包含常见的头部名称,以及特别常见的头部名称与值的组合;
(2)维护一份相同的动态字典(Dynamic Table),可以动态地添加内容;
(3)基于静态哈夫曼码表的哈夫曼编码(Huffman Coding),这个霍夫曼编码是根据大量HTTP头文件的统计信息生成的。这是一个典型的数据结构中的霍夫曼编码,根据字符的常用程度,使常用字符编码长度更短。并进行了一些调整,以确保没有符号具有唯一的编码长度。
1.6 神经网络
1.6.1 机器学习与分类问题
机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。机器学习又分为监督学习和非监督学习,其中监督学习可以从给定的有标记的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。分类问题即将样本区分到给定的类,例如在二维坐标系下,给定一个点,求这个点属于哪个象限。最简单的分类问题为2分类,即将样本按“是”(正类)或“否”(负类)分为两个类,要分k个类就称为k分类问题。
1.6.2 用神经网络解决分类问题
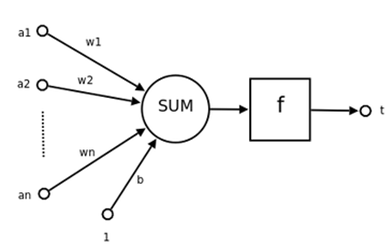
神经网络是机器学习的方法之一。神经元是神经网络的基本组成,其结构如图1。其中:
\(a_1,...,a_n\)为输入向量的各个分量;
\(w_1,...,w_n\)为神经元各个突触的权值;
b为偏置,近似于常数项;
f为激活函数,通常为非线性函数。一般为ReLU(),sigmoid(),tanh()等;
t为神经元输出。
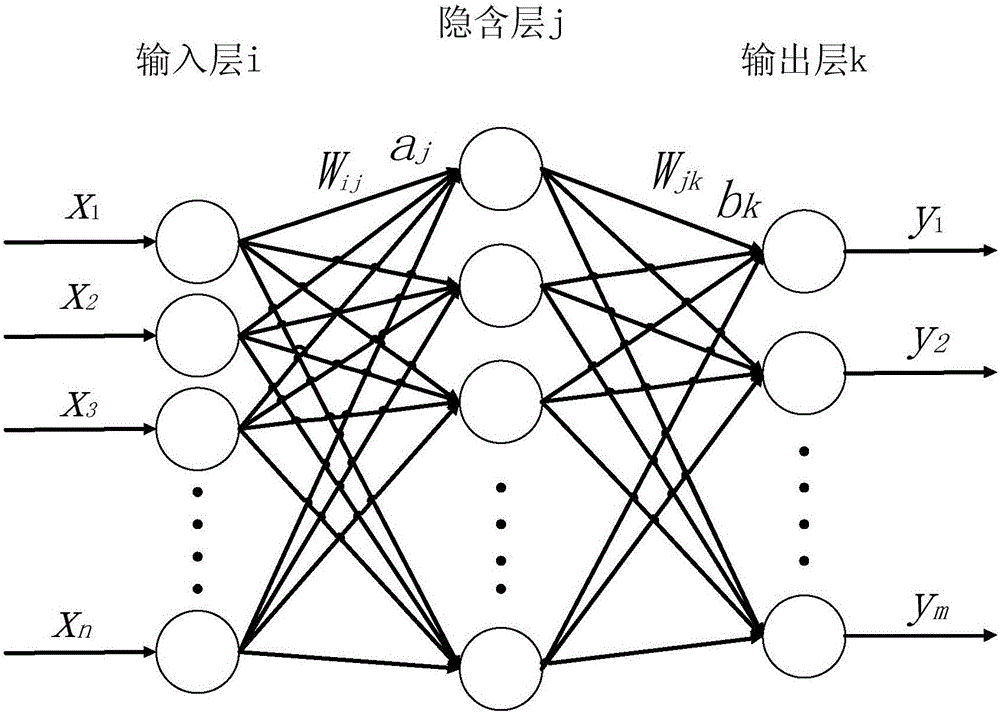
多个神经元相连接构成神经网络,一般神经网络有三层以上,图2为一个三层神经网络,第一层为输入层,输入层一般为列向量形式的样本数据,中间的层为隐藏层(隐含层),最后一层称为输出层,通过多层神经网络,可以实现极其复杂的非线性运算,即可以拟合非常复杂的函数。
对于分类问题,分多少类决定了输出单元的个数。通过Softmax将其转化为每个类别的概率。例如上图,设上图有四个输出\(z_1,z_2,z_3,z_4\),令\(a_i=e^{z_i}/(\sum^4_{i=1} e^{z_i})\)。最后可选择概率最大的一个。
1.6.3 字典
当使用神经网络处理自然语言问题,例如找出一句英语中的人名时,通常需要一个字典来表示用到的单词。字典由大量单词组成,例如论文中使用了包含12k个单词的字典,此外,通常词汇表还会包含一个用于表示词汇表以外单词的
1.6.4 双向循环神经网络
处理自然语言问题时,常使用循环神经网络(RNN),即循环使用一个神经网络,这样即可通过多次输出的单词组成句子。
一般的RNN是单向的,只接收来自前文的信息,而自然语言问题常常要考虑前后文,因此又有人提出了双向循环神经网络,该神经网络同时考虑前后文。
通常在RNN中,距离越远单词之间影响越小,因此可以使用门控循环单元(GRU)记忆信息并继续提供给该网络。
1.6.5 集束搜索
集束搜索即每次不仅仅考虑概率最高的输出,而是记录概率最高的b个输出。例如,b=3且字典大小d=100,一开始选择d个可能的单词中概率最高的b个,在此基础上,这b个单词每个又有d种可能,共b×d=3×100=300种假设,再次取这300种假设中最高的3个,依次类推,直到输出结束。
1.7 性能指标
1.7.1 F_1-score
\(F_1-score\)是一种常见的评估神经网络二分类问题性能的指标,其定义如下。
\(tp\):真正类个数;
\(tn\):真负类个数;
\(fp\):假正类个数;
\(fn\):假负类个数;
查准率\(Precision=tp/(tp+fp)\);
召回率\(Recall=tp/(tp+fn)\);
\(F_1-score=2×(Precision×Recall)/(Precision+Recall)\)
\(F_1-score\)可以有效避免偏斜类的影响,例如检测癌症患者的分类问题,患癌症的样本本来占比就很少,假设在测试集中只占0.1%,如果使用准确率作为指标,即使分类器其实是将所有人都判定为不患癌症,也能有99.9%的准确率,但显然,将所有人都判定为不患癌症并不是一个我们想要的好分类器。
1.7.2 编辑距离
编辑距离,又叫Levenshtein距离,指的是两个字符串之间,由一个转换成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
2 论文原理
2.1 介绍
2.1.1 主要贡献
(1)提出了一种检测由自动完成查询中的单词引起的数据包的方法。来自每个搜索引擎的自动完成的数据包大小的模式将会以确定有限自动机(DFA)为特征。我们将最长的递增子序列问题(该问题具有有效的动态规划解决方案)概括为寻找DFA接受的最长子序列的问题。通过这种方法可以用近乎完美的精度检测网络流量中的击键,并以超过90%的准确率描述单词。
(2)提出了一种利用HPACK中使用的静态霍夫曼代码(HTTP2标头压缩格式)的侧信道攻击。以前的研究表明,HPACK通过压缩大小泄漏的信息相对较少。但使用自动完成功能时,搜索查询将一次递增一个字符,并重新压缩。由于这种增量压缩,信息泄漏比以前认为的要多。我们描述了一种利用此信息泄漏来缩减字典的方法,该方法可提高我们的远程键盘记录攻击的准确性。
(3)提出了一个可从击键时间识别单词的神经网络。该神经网络考虑了每个击键时间及其前后文,接受了83位打字员击键记录的训练,并以19%的正确识别单词。
(4)提出了一种利用较低英语相关熵的集成了语言模型和击键时间攻击的攻击方法。以前的击键时间攻击已经发现,与密码相比,自然语言的相关熵较低,简而言之就是比起无序的密码,自然语言的混乱程度较低。该论文介绍了一种结合击键时间攻击和语言模型来生成假设的搜索内容的方法。
2.1.2 KREEP简介
该攻击整合了由三个独立来源泄漏的信息,包括以数据包到达时间表示的击键时间,URL中百分比编码的空格字符以及HPACK中使用的静态霍夫曼代码。虽然每个来源本身都是相对较弱的预测变量,但结合起来,并利用相对较低的英语熵,最多可以找到15%的搜索的击键记录。KREEP是一种远程被动攻击,可以在加密的网络流量上运行,即使对网络流量进行了加密,该攻击仍然可以成功。
该攻击包括五个阶段:
(1)击键检测:将与击键相对应的数据包从背景流量中分离出来;
(2)标记化:描述分组序列中的单词;
(3)字典修剪:通过HTTP2标头压缩侧信道的方式从大型字典中消除单词;
(4)单词识别:由神经网络执行,该神经网络根据数据包到达的时间预测单词的概率;
(5)集束搜索:使用语言模型生成假设查询。
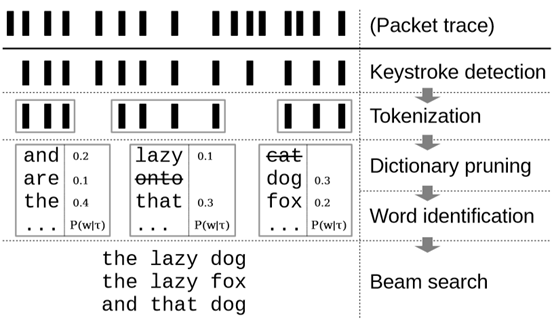
输入到KREEP的是一个包含自动完成后台流量的抓包记录(.pcap文件)。输出是假设搜索查询的列表。每个组件都为下一个组件提供输入。接下来将会提出该论文的威胁模型,并逐一介绍以上五个阶段。
2.1.3 威胁模型
假设有一个远程攻击者,该攻击者可以捕获具有自动完成功能的搜索引擎收到的受害者发出的加密网络流量。假设受害者只输入字母键和空格键(总共27个键)构成仅由小写英文单词组成的查询,每个单词之间用空格分隔。不包括复制,粘贴,Backspac,Delete以及其他任何可能导致光标更改位置的输入,例如箭头键。受害者可能会在输入完整查询之前选择自动完成建议。KREEP可以识别直到进行选择为止的查询。查询的单词必须包含在攻击者已知的大型英语字典中。使用的字典包含超过12k个单词,其中包括10k个最常见的英语单词以及出现在Enron电子邮件语料库和英语gigaword newswire语料库中的英语单词。执行单词识别的神经网络在一个独立的数据集上进行训练。假设攻击者也有权访问此数据集。
2.2 击键检测
该阶段通过数据包的次序以及大小差异,将自动完成请求的数据包从背景流量中分离出来。击键检测是是一个二分类问题,判断一个数据包是否为搜索引擎的一系列自动完成请求的数据包。
当检测到查询发生更改时,客户端会将HTTP GET请求发送到服务器,并且服务器以建议的搜索查询列表作为响应。这导致在击键事件之后出现一系列HTTP请求,每个自动完成请求均包含一个附加到URL路径的新字符。该请求除了包含其他参数(例如身份验证令牌和页面加载选项)外,还包含部分完成的查询输入,这些参数通常在连续两次之间不改变。每个请求仅改变一个字符,每个包的大小比前一个包增加约1个字节。结果,数据包大小的序列单调增加,如图4所示。
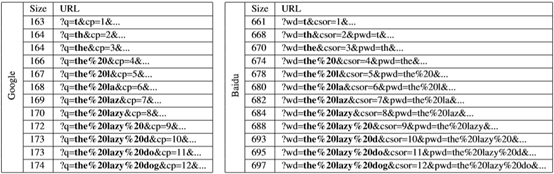
令\(s_i\)为第i个自动完成请求的字节大小,\(s_0\)为第一个请求的大小。对于\(i>0\),数据包大小差异\(d_i=s_i-s_{i-1}\)。此差异反映了数据包大小增长与查询长度的关系,该请求长度与请求中包含的其他参数的大小无关,这些参数由于大小标识符不同而在主机之间有所不同,身份验证令牌和页面加载选项。但是,这些参数通常在来自单个主机的连续自动完成请求中保持不变。
针对Google和百度的\(d_i\)为查询长度的函数的分布。从这个图和手动检查几个HTTP请求包开始,论文对每个搜索引擎的行为进行了几次观察。然后,使用这些观察结果来构建DFA,以接受一系列自动填充数据包大小差异。
由于自动完成请求的大小是单调增加的,因此可以通过找到数据包大小的最长递增子序列(LIS)来执行击键检测,这可以通过动态编程来解决。但是,LIS无法解决以下问题:数据包通常会增加一个固定数量,并且由于HPACK,两个连续的数据包可能具有相同的大小。为此,该论文将LIS问题概括为基于上一节中的观察结果找到序列检测器DFA接受的最长子序列的问题。
首先定义一个DFA,该DFA接受由每个搜索引擎的自动完成功能生成的一系列数据包大小差异。将最长的自动机子序列(LAS)设为DFA接受的最长的子序列。通过按数据包大小顺序查找LAS,可以检测到击键数据包。可惜论文中使用的查找方法不是恒成立的,但此方法在实践中效果不错。
2.3 标记化
标记化是识别自动完成请求序列中单词的过程。由于假设搜索是由空格隔开的英语单词组成的,因此可以在单词级别进行下一阶段的攻击(字典修剪,单词识别和集束搜索)。像击键检测一样,标记化是一个分类问题,因为每个数据包都可以标记为定界符或单词的一部分。论文假设空格字符是单词之间的唯一分隔符。
百分比编码是用来表示URL中允许字符集之外的字符的转义序列。 百分比编码的序列由三个ASCII字符组成,“%”后跟两个十六进制数字。URL中的空格字符(ASCII = 32)的百分比编码为“%20”。 当用户在搜索查询字段中输入一个空格时,此转义序列将附加到URL,导致未压缩的请求数据包增加3个字节。
由于HPACK压缩,当按下Space键时,Google自动完成数据包增加2个字节。字符“%”,“ 2”和“ 0”的霍夫曼码分别具有6、5和5的位长,而序列“%20”的总压缩位长为16位。通过将增加2个字节的数据包标记为字边界来执行标记化。百度不使用HPACK,因此转义序列“%20”占用3个字节。但是,由于每个请求中都包含上一个查询,因此当按下空格时,数据包的大小增加4个字节,通过检测任意两个连续的4字节增加中的第一个来实现百度查询的标记化。
2.4 字典修剪
这部分使用了一种利用HPACK中静态霍夫曼编码的侧信道攻击,该攻击可用于缩减字典的大小(由于百度没有使用HPACK压缩,目前仅适用于谷歌)。
一般而言,HPACK中,压缩字符串文字被填充到8的倍数,这样是很难通过其长度泄露信息的。然而,在一系列自动完成请求中,由于每个请求都包含一个附加到URL路径的新字符,将其通过标头压缩后再发送到服务器,一系列自动完成请求的长度会逐渐递增,此时论文中称其为增量压缩。增量压缩导致,在添加每个新字符之后,对手会观察到压缩查询的累积字节大小B_1,...,B_n的序列,而不是总大小B,而不同的单词以不同的速率增长。
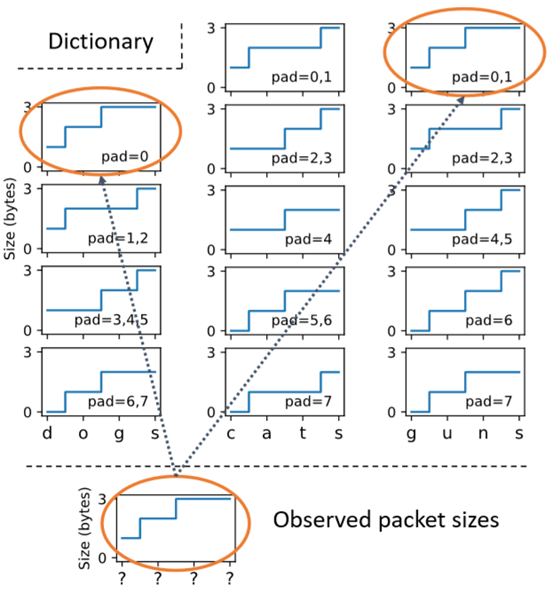
为了利用通过增量压缩泄漏的信息,将观察到的累积字节大小序列与词典中包含的每个单词的累积大小进行比较。对于每种可能的填充量,都预先计算字典中单词的大小。最后可以从字典中消除观察序列从不出现的单词。例如图5,其中用户键入了4个字母的单词,其累积字节大小为[1,2,3,3]。将此序列与字典进行比较,有两个潜在的匹配:对于填充\(p_0=0\)的“dogs”和\(p_0=0\)或\(p_0=1\)的“guns”。但由于任何填充下都无法匹配单词“cats”,因此认为用户没有搜索“cats”。
2.5 单词识别
该阶段使用分组到达时间来预测用户键入的单词。在字典修剪之后,确定主要单词的概率。然后在集束搜索中将其与语言模型相结合,以生成假设查询。
由于每个自动完成请求都是由按键事件触发的,因此数据包到达时间可以忠实地保留按键等待时间。这些等待时间用于预测用户按下了哪些键。论文定义了一个模型,该模型考虑上下文并预测了每个键的概率。
论文使用三层神经网络来预测每个键的概率。通常,每个长度为n的单词有n+1个数据包到达时间,因为空格在第一个字符之前,在最后一个字符之后。该模型将0≤i≤n的延迟时间𝜏𝑖序列作为输入,并预测P(k_i),即每个键k_i的概率。网络的第一层是带有门控循环单元(GRU)的双向循环神经网络(RNN),它以n + 1个时间间隔的序列作为输入。第二层是卷积层,卷积核大小为2,无填充。 卷积层将输出的大小从n + 1减小到n。 最后一层是具有softmax激活的层,可预测每个时间步长每个键(26个类别)的概率。 此架构如图6所示。
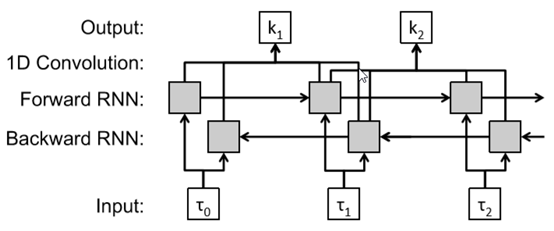
单词概率由网络输出的每个键(字母)概率序列确定。单词w的概率是该单词中所有键的联合概率,\(P(w│τ)=∏_{k_i∈w}P(k_i)\)
2.6 集束搜索
在最后阶段,将单词概率与语言模型组合在一起,以在集束搜索中生成假设查询。
假设查询为1≤i≤N的N个单词\(w_i\)的序列,在自然语言(例如英语)中,某些单词更可能跟随其他单词。例如,尝试预测“从_恢复”序列的8个字母的单词。诸如“扭伤(sprained)”和“断裂(fractured)”之类的单词的概率应比诸如“购买(purchase)”和“位置(position)”之类的其他单词更高。语言模型的英语语言约束可以与数据包时序预测的单词概率结合使用。
语言模型根据给定单词之前的单词来估计单词的概率,用\(P(w_i | w_1...w_{i-1})\)表示。将语言模型与按键时序模型相结合,以确定整个查询\(W=[w_1,...,w_N]\)的概率\(P(W)=∏_{w_i∈W} P(w_i│τ) {P(w_i | w_1 ...w_{i-1})}^α\)其中α参数控制着语言模型的权重,越大的𝛼意味着对语言模型赋予的权重越大。论文发现在0.2到0.5范围内的α效果很好,并使用α=0.2。语言模型是采用了其他人在Billion Word corpus语料库上训练的模型。最后使用集束宽度为50的集束搜索来生成假设查询。
3 代码复现
3.1 KREEP性能评估
论文使用了一个公开的击键数据集的子集作为训练集,该数据集包含从超过10万名用户那里收集的,来自Enron电子邮件语料库和英语gigaword newswire语料库的击键数据。从该数据集中保留了83k用户,这些用户在台式机或笔记本电脑键盘上使用美国英语语言环境,并使用QWERTY键盘布局。论文随机选择了长度在1到20个单词之间的4k个不同的短语作为测试集来模拟搜索查询(测试集数据没有在训练集出现),其中仅包含字母和空格键。
论文在Google和百度搜索引擎(默认为HTTPS连接)以上述4k个短语为查询,并在击键事件发生时生成自动完成请求。所有结果均通过加密的流量获得:Google为TLSv1.3,百度为TLSv1.2。
表1中针对Chrome浏览器和FireFox浏览器中的百度和Google网站分别报告了击键检测和标记化的准确性。在网站和浏览器中,击键检测的准确性都很高。
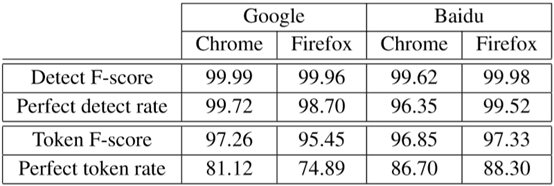
令牌化失败的情况中Google的误报主要是由于HPACK标头中的字符串长度字段发生翻转而引起的,该字段指定了压缩字符串的字节大小。 在HPACK中,字符串长度以7位整数开始。当压缩字节数超过255时,会为字符串长度分配一个额外的字节,从而导致整体增加2个字节(“字符串长度”增加+1,而查询中的新字符增加+1)。由于通常不知道发生此翻转的位置,因此无法区分2字节的增加是由于“字符串长度”翻转还是由于添加了百分比编码的空格。
表2显示了在假设查询中能识别出真实查询的比例。论文还确定了每个搜索引擎的最小编辑距离,并将其作为查询长度的函数。

通常,识别查询的难度随查询长度的增加而增加。假设与真实查询的平均最小编辑距离为0.37。对于相等长度的字符串,编辑距离减小为汉明距离,并且在大约98%的查询中可以实现完美检测(F-score为100%)。0.37的编辑距离约有63%的击键识别精度。论文并未发现浏览器的性能有显着差异,但是由于增量压缩泄露了信息,KREEP在Google上实现了更高的查询识别率。
3.2 论文代码复现
3.2.1 安装kreep项目过程
论文代码托管地址为https://github.com/vmonaco/kreep。我使用Kali-linux虚拟机安装该项目。
项目的readme中只告诉我们可以使用pip install进行在线安装。从关键字pip可判断该代码为python代码,kali自带python2.7,可用
apt install -y python-pip
安装pip,后经测试发现,在python2.7环境下安装会报错,因此再使用
apt-get install python3
apt install -y python3-pip
安装python3.8和相应的pip,使用python3和pip3关键字可代替python和pip关键字。
大概是因为指定了github项目地址,即使是换了pip源之后,联网安装速度还是会很慢。因此我选择先下载项目zip文件到kali虚拟机后,到其所在目录下使用
pip3 install kreep-master.zip
在本地进行安装。安装完毕后,尝试使用时会报错,提示找不到文件File b'/usr/local/lib/python3.8/dist-packages/kreep/models/bigrams.csv' does not exist: b'/usr/local/lib/python3.8/dist-packages/kreep/models/bigrams.csv’,到相应的路径下发现该文件夹是空的,但在github上可以找到所需模型,如图7。
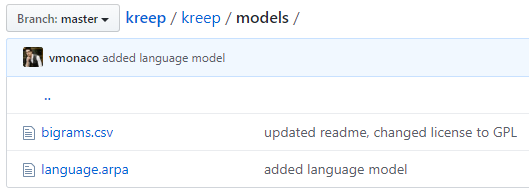
模型有两个,都需要复制到相应文件夹中。之后经过如下的测试证明安装无误。
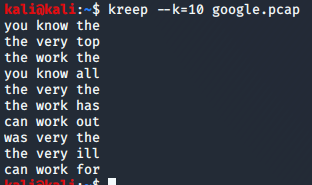

3.2.2 抓包测试结果
我在百度和谷歌搜索“happy brithday”并使用wireshark抓包测试,发现需要保存为wireshark默认的pcapng才不会报错。我做了多次抓包测试,换了几个关键词,然而结果如图,并不理想,连标记化都无法成功。
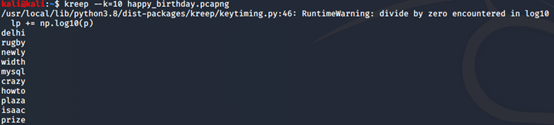
上图为百度测试结果
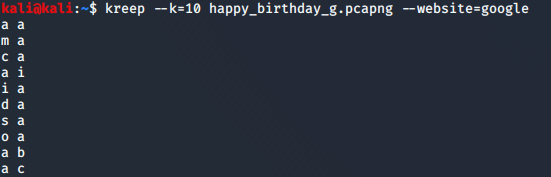
上图为google测试结果
猜测可能是我抓包有问题,因为用的不是pcap而是pcapng格式(我也尝试将结果另存为wireshark的pcap格式但会报错),也可能因为地处中国,因为要用中文,因此百度和谷歌等搜索引擎的自动完成功能有本地化修改(例如自动完成会混入中文),而该神经网络模型无法泛化到这个程度。也或许是因为论文中也有提出可行的防御措施(例如加噪声、在HTTP头加随机填充等),百度和谷歌已经做了防御措施使攻击不再成功。
3.3 防御措施
(1)随机填充:每个自动完成数据包的大小以0.5的概率增加1字节,其他数据包的大小保持不变。
(2)将空格编码为单个字符:例如将空格编码为“+”而不是“%20”,搜索引擎Yandex和DuckDuckGo都使用这种策略。
(3)使用轮询模型而不是回调模型来实现自动完成功能。

