

第六周 进程的描述和进程的创建
一.进程的描述
进程控制块PCB——task_struct
为了管理进程,内核必须对每个进程进行清晰的描述,进程描述符提供了内核所需了解的进程信息
(1)struct task_struct数据结构很庞大
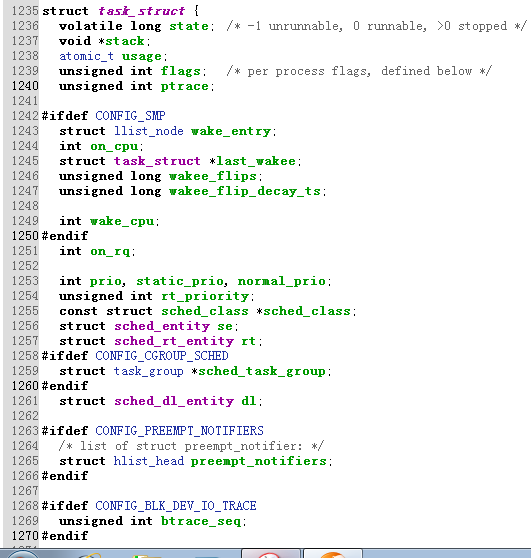
(2)Linux进程的状态与操作系统原理中的描述的进程状态似乎有所不同,比如就绪状态和运行状态都是TASK_RUNNING

(3)进程的标示pid

(4)所有进程链表struct list_head tasks
内核的双向循环链表的实现方法:一个更简略的双向循环链表
为了对给定类型的进程,例如所有在可运行状态下的进程进行有效的搜索,内核维护了几个进程链表
(5)程序创建的进程具有父子关系,在编程时往往需要引用这样的父子关系。进程描述符中有几个域用来表示这样的关系
(6)Linux为每个进程分配一个8KB大小的内存区域,用于存放该进程两个不同的数据结构:Thread_info和进程的内核堆栈
进程处于内核态时使用,不同于用户态堆栈,即PCB中指定了内核栈,但是PCB中没有用户态堆栈,因为内核控制路径所用的堆栈很少,因此对栈和Thread_info 来说,8KB足够了
(7)struct thread_struct thread; //CPU即一个任务的特殊阶段
(8)文件系统和文件描述符
(9)内存管理——进程的地址空间
二.进程的创建
fork一个子进程的代码
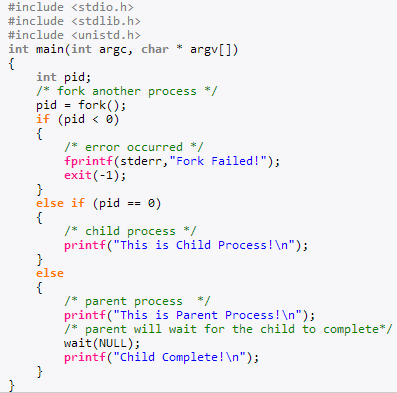
创建一个新进程在内核中的执行过程:
-
fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建
-
Linux通过复制父进程来创建一个新进程
-
复制一个PCB——task_struct

-
要给新进程分配一个新的内核堆栈

-
要修改复制过来的进程数据,比如pid、进程链表等等都要改改吧,见copy_process内部
-
从用户态的代码看fork();函数返回了两次,即在父子进程中各返回一次,父进程从系统调用中返回比较容易理解,子进程从系统调用中返回,那它在系统调用处理过程中的哪里开始执行的呢?这就涉及子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题,这是在哪里设定的?copy_thread in copy_process

三.实验:分析Linux内核创建一个新进程的过程
打开shell终端,执行:
cd LinuxKernel
rm -rf menu
git clone https://github.com/mengning/menu.git
cd menu
mv test_fork.c test.c
make rootfs
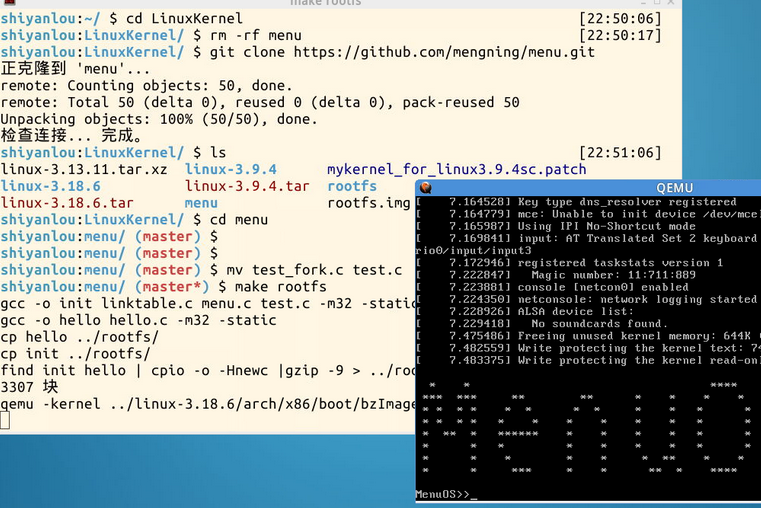
运行help命令:
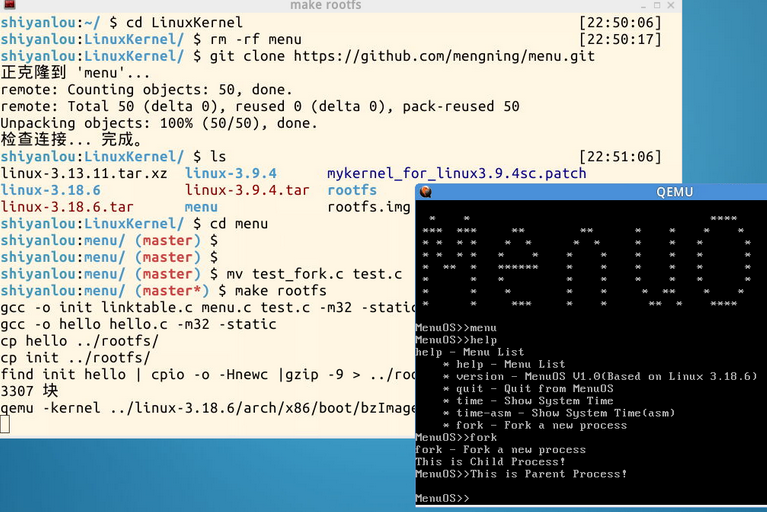
可以看到在menu命令菜单中,包含有fork命令,输出信息表示的是父子进程的创建信息
通过qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S打开调试模式
然后打开gdb:gdb
file linux-3.18.6/vmlinux target remote:1234
设置断点:
b sys_clone
b do_fork
b dup_task_struct
b copy_process
b copy_thread
b ret_from_fork
实验总结:在内核态下执行的0号进程,它是所有进程的祖先。由0号进程创建1号进程(内核态),1号负责执行内核的部分初始化工作及进行系统配置,并创建若干 个用于高速缓存和虚拟主存管理的内核线程。随后,1号进程调用execve()运行可执行程序init,并演变成用户态1号进程,即init进程。而fork()允许用户态下创建新的进程, fork 创造的子进程复制了父亲进程的资源,包括内存的内容task_struct内容,新旧进程使用同一代码段,复制数据段和堆栈段,这里的复制采用了注明的 copy_on_write技术,即一旦子进程开始运行,则新旧进程的地址空间已经分开,两者运行独立。在 Linux 内核中,供用户创建进程的系统调用fork()函数的响应函数是 sys_fork()、sys_clone()、sys_vfork()。这三个函数都是通过调用内核函数 do_fork() 来实现的。

