
Linux内核分析——第二章 从内核出发
第二章 从内核出发
一、获取内核源码
1、Git是分布式的;下载和管理Linux内核源代码;
2、获取最新提交到版本树的一个副本
$ git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git
当下载代码后,更新自己的分支到最新分支 $ git pull
3、安装内核源代码
(1)压缩形式为bzip2
运行:$ tar xvjf linux-x.y.z.tar.bz2
(2)压缩形式为zip
运行:$ tar xvzf linux-x.y.z.tar.gz
4、使用补丁
从内部源码树开始,运行$ patch -p1 < ../patch-x,y,z
二、内核源码树

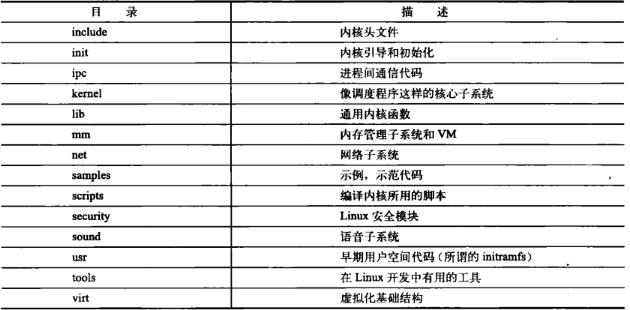
COPYIN:内核许可证;
CREDITS:内核代码的开发者列表;
MAINTAINTERS:维护者列表——负责维护内核子系统和驱动程序;
Makefile:是基本内核的Makefile;
三、编译内核
1、配置内核
(1)字符页面的命令行工具:$ make config
(2)图形界面工具:$ make menuconfig
(3)配置项的二选一和三选一:
二选一:yes 或者 no
三选一:yes 或者 no 或者 module(以模块生成)
(4)其他的几种配置:
$ make defconfig //基于默认配置
$ make oldconfig //验证和更新配置
(5).config文件:配置项会被存放在内核代码树根目录下。
$ zcat /proc/config.gz > .config 目前的内核已经启用了CONFIG_IKCONFIG_PROC选项,可以从/proc下复制文件;
$ make oldconfig 便以一个新内核;
$ make 编译该配置好的内核;
2、减少编译的垃圾信息
(1)少看到垃圾信息却不错过错误报告和警告信息,对输出重定向
$ make > ../detritus
(2)把无用的输出信息重定向到永无返回值的黑洞/dev/null中
$ make > /dev/null
3、衍生多个编译作业
(1)以多个作业编译内核
$ make -jn (j:指定同时执行多任务;n:要衍生出的作业数)
(2)16核处理器
$ make -j32 > /dev/null
4、安装新内核
(1)以root身份,运行,把所有已编译的模块安装到正确的主目录/lib/modules下。
% make modules_install
(2)System.map文件:编译时在内核代码树的根目录下创建的文件;是一个符号对照表;用来将内核符号与它们的起始地址对应起来;调试时,把内存地址转化为函数名和变量名,很有用。
四、内核开发的特点
1、内核开发有一些独特之处:
(1)内核开发时既不能访问C库也不能访问标准的C头文件。
(2)内核编程时必须使用GNU C。
(3)内核编程时缺乏像用户空间那样的内存保护机制。
(4)内核编程时难以执行浮点运算。
(5)内核给每个进程只有一个很小的定长堆栈。
(6)由于内核支持异步中断、抢占和SMP,必须时刻注意同步和并发
(7)要考虑可移植性的重要性。
2、无libc库抑或标准头文件
内核不能链接使用标准C函数库。
3、头文件
(1)基本头文件位于内核源代码顶级目录下的include中。
(2)体系结构相关头文件:内核源代码树arch/<architecture>/include/asm目录下。
4、GNU C
GCC是多种GNU编译器的集合。
5、内联函数
定义一个内联函数,用static作关键字,用inline限定它。
static inline void wolf(unsigned long tail_size);
6、内联汇编
用asm()指令嵌入汇编代码
unsigned int low, high;
asm volatile("rdtsc" : "=a" (low), "=d" (high)); //low 和 high 分别包含64位时间戳的低32位和高32位
7、分支声明
(1)/* error在绝大多数情况下为0 */
if (unlikely(error)) {
/* ... */
}
(2) /* success在通常不为0 */
if (likely(success)) {
/* ... */
}
如果判断正确,性能会提升;如果搞错,性能反而下降。
8、没有内存保护机制
(1)在内核中,不该访问非法的内存地址,引用空指针,否则内核会over;
(2)内核中的内存不分页:每用掉一个字节,物理内存都减少一个;
9、不用轻易在内核中使用浮点数
与用户空间进程不同,内核不完美支持浮点操作,因为他本身不能陷入;
10、容积小而固定的栈
(1)用户空间的栈本身比较大,而且可以动态增长。
(2)对于不用的体系结构,内核栈的大小不一样并都是固定的。
11、同步和并发
内核易产生竞争条件,许多特性都要求能过并发地访问共享数据,就要求同步机制以保证不出现竞争条件,特别是:
(1)Linux是抢占多任务操作系统.
(2)Linux内核支持对称多处理器系统(SMP)。
(3)中断异步到来。
(4)Linux内核可以抢占。
常用解决方法:自旋锁和信号量
12、可移植性的重要性
Linux是可移植的操作系统。
五、小结
1、内核有独一无二的特质。
2、它实施自己的规则和奖惩措施,拥有整个系统的最高管理权。

