
《Linux内核分析》第八周 进程的切换和系统的一般执行过程
张文俊 原创作品转载请注明出处 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
一、进程切换的关键代码switch_to的分析
1.进程调度与进程调度的时机分析
- 进程分类
- 分类1
- I/O-bound:等待I/O
- CPU-bound:大量占用CPU进行计算
- 分类2
- 交互式进程(shell)
- 实时进程
- 批处理进程
- 分类1
- 进程调度策略
- 一组决定何时以何种方式选择进程的规则
- Linux的调度基于分时和优先级策略:
- 进程根据优先级(系统根据特定算法计算出来)排队;
- 这个优先级的值表示如何适当分配CPU;
- 调度程序会根据进程的运行周期动态调整优先级;
- 比如nice等系统调用,可以手动调整优先级
- 调度策略本质上是一种算法,这些算法从实现的角度看仅仅是从运行队列中选择一个新进程,选择的过程中运用了不同的策略而已
- 内核中的调度算法相关代码使用了类似OOD中的策略模式
- 进程调度的时机
- 中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule()(也就是说,用户态进程只能被动地调度);
- 内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度;
-
用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。
2.进程切换上下文的相关代码
1.概念:
- 为了控制进程的执行,内核必须有能力挂起正在CPU上执行的进程,并恢复以前挂起的某个进程的执行,这叫做进程切换(挂起正在CPU上执行的进程,与中断时保存现场是不同的,中断前后是在同一个进程上下文中,只是由用户态转向内核态执行)
- 进程上下文包含了进程执行需要的所有信息
- 用户地址空间:包括程序代码,数据,用户堆栈等
- 控制信息:进程描述符,内核堆栈等
- 硬件上下文(中断也要保存硬件上下文只是保存的方法不同,中断是通过压栈来解决的,而这里是通过schedule函数)
- switch_to完成寄存器的切换:先保存当前进程的寄存器,再进行堆栈切换(下图第44、45行)自此后所有的压栈都是在新进程的堆栈中了,再切换eip(下图46、56行),这样当前进程可以从新进程中恢复,还有其他必要的切换
- next_ip一般是$1f(对于新创建的进程来说就是ret_from_fork)
- jmp __switch_to是函数调用,通过寄存器传递参数;函数执行结束return的时候从下一条指令开始(也就是认为是新进程的开始)
二、Linux系统的一般执行过程
1. Linux系统的一般执行过程分析
最一般的情况:正在运行的用户态进程X切换到运行用户态进程Y的过程
- 正在运行的用户态进程X
- 发生中断——
- save cs:eip/esp/eflags(current) to kernel stack;
- then load cs:eip(系统调用的起点,entry of a specific ISR) and ss:esp(point to kernel stack)
- 进入内核代码,SAVE_ALL //保存现场
- (这一步也可能不发生)中断处理过程中或中断返回前调用了schedule(),其中的switch_to做了关键的进程上下文切换(把当前进程X的用户堆栈切换到需要的其他进程堆栈中)
- 标号1之后开始运行上一步中选中的用户态进程Y(这里Y曾经通过以上步骤被切换出去过因此可以从标号1继续执行)
- restore_all //恢复现场
- iret - pop cs:eip/ss:esp/eflags from kernel stack
- 继续运行用户态进程Y
- 补充:中断上下文和进程长下文切换
前者是CPU内部的切换;后者是在内核中堆栈的切换
2.Linux系统执行过程中的几个特殊情况
- 通过中断处理过程中的调度时机,用户态进程与内核线程之间互相切换和内核线程之间互相切换,与最一般的情况非常类似,只是内核线程运行过程中发生中断的时候没有进程用户态和内核态的转换,cs不会变化;
- 内核线程主动调用schedule(),只有进程上下文的切换,没有发生中断上下文的切换,也不需要从中断中返回,与最一般的情况相比更简略;
- 创建子进程的系统调用在子进程中的执行起点(如ret_from_fork,上文中也已经提到过)及返回用户态;
加载一个新的可执行程序后返回到用户态的情况,如execve,在新进程内部修改了中断保存的信息
3.地址切换
- 进程的地址空间一共有4G,其中0——3G是用户态可以访问,3G以上只有内核态可以访问
- 内核&舞女
- 内核就是各种中断处理过程和内核线程的集合;
- 内核相当于出租车,可以为每一个“招手”的进程提供内核态到用户态的转换;
- 没有进程需要“承载”的时候,内核进入idle0号进程进行“空转”;
- 3G以上的部分就是这样的“出租车”,是所有进程共享的,在内核态部分切换的时候就比较容易
三、LINUX 系统架构和执行过程概述
1、CPU和内存的角度看Linux系统的执行
- 执行gets()函数;
- 执行系统调用,陷入内核;
- 等待输入,CPU会调度其他进程执行,同时wait一个I/O中断;
- 敲击ls,发I/O中断给CPU,中断处理程序进行现场保存、压栈等等;
- 中断处理程序发现X进程在等待这个I/O(此时X已经变成阻塞态),处理程序将X设置为WAKE_UP;
- 进程管理可能会把进程X设置为next进程,这样gets系统调用获得数据,再返回用户态堆栈
- 7.从内存角度看,所有的物理地址都会被映射到3G以上的地址空间:因为这部分对所有进程来说都是共享的
四、实验
gdb调试:
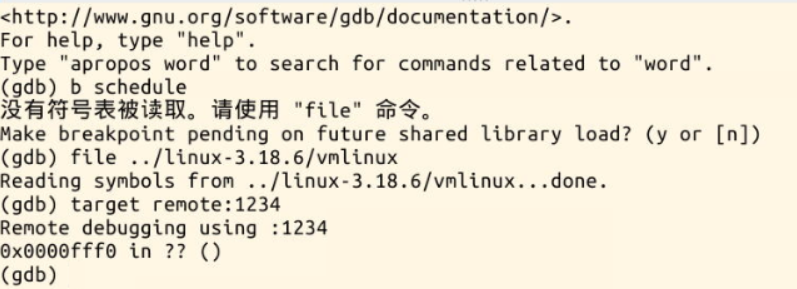
在schedule处设置断点,点击c运行。

c之后按n单步执行,直到遇到__schedule函数,进入其中查看

继续执行,直到发现context_switch函数,设置断点后,设法进入其内部查看


